pytorch 句子相似度
文章目录
- 1.根据向量
- 1.1 embedding层介绍
- 1.2 相似度计算
- 1.2.1 字面距离相似度度量
- 1.2.2 语义相似性
- 2. 一些简单方法
- 2.1 编辑距离
- 2.2 杰卡德系数计算
- 2.3 Word2Vec 计算
1.根据向量
1.1 embedding层介绍
做nlp很多时候要用到嵌入层,pytorch中自带了这个层,那么什么是embedding层?
用最通俗的语言讲就是在nlp里,embedding层就是句子、词转为向量,比如把单词表[‘你’,‘好’,‘吗’]
编码成
‘你’ --------------[0.2,0.1]
‘好’ --------------[0.3,0.2]
‘吗’ --------------[0.6,0.5]
一个不错的参考的传送门
为什么要embedding?
简而言之就是one-hot编码太占地方了!!!
详细介绍传送门
pytorch里的embedding层文档:官方文档
pytorch的embedding层的参数理解:
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2,scale_grad_by_freq=False, sparse=False)
num_embeddings:嵌入字典的大小(词的个数);
embedding_dim:每个嵌入向量的大小;
padding_idx:若给定,则每遇到 padding_idx 时,位于 padding_idx 的嵌入向量(即 padding_idx 映射所对应的向量)为0;
max_norm:若给定,则每个大于 max_norm 的数都会被规范化为 max_norm;
norm_type:为 max_norm 计算 p-范数的 p值;
scale_grad_by_freq:若给定,则将按照 mini-batch 中 words 频率的倒数 scale gradients;
sparse:若为 True,则 weight 矩阵将是稀疏张量。
输入:含有待提取 indices 的任意 shape 的 Long Tensor;
输出:输出 shape =(,H),其中 * 为输入的 shape,H = embedding_dim(若输入 shape 为 NM,则输出 shape 为 NMH);
torch.nn.Embedding 的权重为 num_embeddings * embedding_dim 的矩阵,例如输入10个词,每个词用3为向量表示,则权重为10\times 3的矩阵;
参考传送门
代码解释:
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
>>> # example with padding_idx
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0,2,0,5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
a = torch.LongTensor([0])
embedding = torch.nn.Embedding(2, 5)
b = embedding(a)
b
Out[29]: tensor([[1.7931, 0.5004, 0.3444, 0.7140, 0.3001]], grad_fn=<EmbeddingBackward>)
参考传送门
import torch
from torch import nn
input = torch.LongTensor([[1, 2, 6, 4], [5, 6, 7, 8]])
em = nn.Embedding(10, 3, padding_idx=6)
output = em(input)
print("output:",output)
print("output.shape:",output.shape)
print("em.weight.shape:",em.weight.shape)
结果如下:
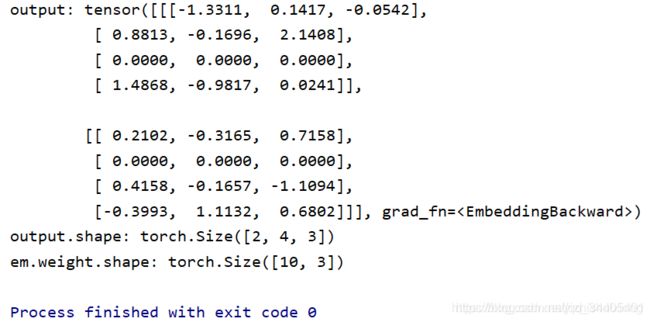
可以看出 “6” 所对应映射的向量被填充了0。
1.2 相似度计算
1.2.1 字面距离相似度度量
参考传送门1
方法和代码传送门2
1.2.2 语义相似性
参考传送门1
2. 一些简单方法
2.1 编辑距离
编辑距离,英文叫做 Edit Distance,又称 Levenshtein 距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,
如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如我们有两个字符串:string 和 setting,如果我们想要把 string 转化为 setting,需要这么两步:
第一步,在 s 和 t 之间加入字符 e。
第二步,把 r 替换成 t。
所以它们的编辑距离差就是 2,这就对应着二者要进行转化所要改变(添加、替换、删除)的最小步数。
安装:pip3 install distance
import distance
str1 = "公司地址是哪里"
str2 = "公司在什么位置"
def edit_distance(s1, s2):
return distance.levenshtein(s1, s2)
print(edit_distance(str1, str2))
想要获取相似的文本的话可以直接设定一个编辑距离的阈值来实现,如设置编辑距离为 2
def edit_distance(s1, s2):
return distance.levenshtein(s1, s2)
strings = [
'你在干什么',
'你在干啥子',
'你在做什么',
'你好啊',
'我喜欢吃香蕉'
]
target = '你在干啥'
results = list(filter(lambda x: edit_distance(x, target) <= 2, strings))
print(results)
# ['你在干什么', '你在干啥子']
2.2 杰卡德系数计算
杰卡德系数计算
杰卡德系数,英文叫做 Jaccard index, 又称为 Jaccard 相似系数,用于比较有限样本集之间的相似性与差异性。Jaccard 系数值越大,样本相似度越高。
实际上它的计算方式非常简单,就是两个样本的交集除以并集得到的数值,当两个样本完全一致时,结果为 1,当两个样本完全不同时,结果为 0。
算法非常简单,就是交集除以并集,下面我们用 Python 代码来实现一下:
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
def jaccard_similarity(s1, s2):
def add_space(s):
return ' '.join(list(s))
# 将字中间加入空格
s1, s2 = add_space(s1), add_space(s2)
# 转化为TF矩阵
cv = CountVectorizer(tokenizer=lambda s: s.split())
corpus = [s1, s2]
vectors = cv.fit_transform(corpus).toarray()
# 获取词表内容
ret = cv.get_feature_names()
print(ret)
# 求交集
numerator = np.sum(np.min(vectors, axis=0))
# 求并集
denominator = np.sum(np.max(vectors, axis=0))
# 计算杰卡德系数
return 1.0 * numerator / denominator
s1 = '你在干嘛呢'
s2 = '你在干什么呢'
print(jaccard_similarity(s1, s2))
2.3 Word2Vec 计算
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,可以将每一个词转换为向量,word2vec 有很详细的介绍如下:
详细介绍传送门
下面使用余弦相似度来计算其相似度:
Word2Vec的词向量模型是训练的维基百科的中文语库,这里模型有250维和50维,向量维度越大模型越大,计算越复杂,正常使用时,需要小的模型,发现50维的也差不多,训练模型方式和模型下载请参考:之前文章。
流程:
01、对句子进行拆词:Python提供了很对可用库,自行选择
02、去除无用的分词:删除没用的语气词等,为的是减少对计算句子平均词向量的影响
03、计算句子平均词向量:使用用AVG-W2V,计算句子平均词向量,所以02步尤为重要
04、余弦相似度:
余弦相似度 np.linalg.norm(求范数)(向量的第二范数为传统意义上的向量长度
dist1=float(np.dot(vec1,vec2)/(np.linalg.norm(vec1)*np.linalg.norm(vec2)))
然后打算开始代码时,pip install word2vec出了问题,以后再解决。。。:
这里我们可以直接下载训练好的 Word2Vec 模型,模型的链接地址为:https://pan.baidu.com/s/1TZ8GII0CEX32ydjsfMc0zw,是使用新闻、百度百科、小说数据来训练的 64 维的 Word2Vec 模型,数据量很大,整体效果还不错,我们可以直接下载下来使用,这里我们使用的是 news_12g_baidubaike_20g_novel_90g_embedding_64.bin 数据,然后实现 Sentence2Vec,代码如下:
import gensim
import jieba
import numpy as np
from scipy.linalg import norm
model_file = './word2vec/news_12g_baidubaike_20g_novel_90g_embedding_64.bin'
model = gensim.models.KeyedVectors.load_word2vec_format(model_file, binary=True)
def vector_similarity(s1, s2):
def sentence_vector(s):
words = jieba.lcut(s)
v = np.zeros(64)
for word in words:
v += model[word]
v /= len(words)
return v
v1, v2 = sentence_vector(s1), sentence_vector(s2)
return np.dot(v1, v2) / (norm(v1) * norm(v2))
在获取 Sentence Vector 的时候,我们首先对句子进行分词,然后对分好的每一个词获取其对应的 Vector,然后将所有 Vector 相加并求平均,这样就可得到 Sentence Vector 了,然后再计算其夹角余弦值即可。
调用示例如下:
s1 = '你在干嘛'
s2 = '你正做什么'
vector_similarity(s1, s2)
输出:
0.6701133967824016
strings = [
'你在干什么',
'你在干啥子',
'你在做什么',
'你好啊',
'我喜欢吃香蕉'
]
target = '你在干啥'
for string in strings:
print(string, vector_similarity(string, target))
输出:
你在干什么 0.8785495016487204
你在干啥子 0.9789649689827049
你在做什么 0.8781992402695274
你好啊 0.5174225914249863
我喜欢吃香蕉 0.582990841450621
可以看到相近的语句相似度都能到 0.8 以上,而不同的句子相似度都不足 0.6,这个区分度就非常大了,可以说有了 Word2Vec 我们可以结合一些语义信息来进行一些判断,效果明显也好很多。
所以总体来说,Word2Vec 计算的方式是非常好的。
另外学术界还有一些可能更好的研究成果,这个可以参考知乎上的一些回答:https://www.zhihu.com/question/29978268/answer/54399062。
以上便是进行句子相似度计算的基本方法和 Python 实现,本节代码地址:https://github.com/AIDeepLearning/SentenceDistance。
代码传送门