SiamFC++笔记
SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines
文章根据这些思路:引入分类和目标状态估计分支(G1),无歧义的分类得分(G2),无先验知识的跟踪(G3)和评估质量得分(G4)来设计SiamFC ++。
SiamRPN ++和SiamFC ++的比较(红色部分代表得分高的区域):

guide:
- G1 : 分类和状态估计任务的分离:分类任务将目标从干扰物和背景中分类出来,目标状态的估计如bbox回归等有利于对目标尺度变化的适应性
- G2 : 得分无歧义:分类分数应该直接表示目标存在的置信度分数,即在“视野”中对应像素的子窗口,而不是预设置的锚点框。如SiamRPN容易产生假阳性结果,从而导致跟踪失败。
- G3 : 无先验:不应该有目标比例/比率这样的先验知识,基于数据分发的先验知识阻碍了模型的泛化能力。
- G4 : 预测质量的评估:直接使用分类置信度进行边框选择会导致性能下降,所以应该使用与分类无关的估计质量评分。目标状态评估分支(例如ATOM和DiMP:基于IoU-Net)的准确性很大程度上取决于此准则。
SiamFC++:
- Siamese-based Feature Extraction and Matching
离线学习相似度的度量函数,并在跟踪过程中在搜索图像中进行模板图像(目标)的定位。在嵌入空间中进行互相关计算:
f i ( z , x ) = ψ i ( ϕ ( z ) ) ⋆ ψ i ( ϕ ( x ) ) , i ∈ { c l s , r e g } f_i\left(z,x\right)=\psi_i\left(\phi\left(z\right)\right)\star\psi_i\left(\phi\left(x\right)\right),i\in\{\mathrm{cls},\mathrm{reg}\} fi(z,x)=ψi(ϕ(z))⋆ψi(ϕ(x)),i∈{cls,reg}
ϕ \phi ϕ就是孪生的特征提取结构, ψ i \psi_i ψi是针对不同任务的网络(分类与回归)。 ϕ ⋅ \phi· ϕ⋅和 ψ i ⋅ \psi_i· ψi⋅之间通过两个卷积层微调特征图。

- Application of Design Guidelines in Head Network:
G1 : 分类和状态估计任务的分离
互相关运算之后再设计分类head和回归head。分类head将 ψ c l s \psi_{cls} ψcls作为输入,对特征图每个点的分类就是对原图上对应patch的分类(17 × \times × 17 × \times × 1),而回归head将 ψ r e g \psi_{reg} ψreg作为输入,输出额外的偏移量(17 × \times × 17 × \times × 4)回归,优化边框位置的预测。
对于分类任务,如果特征图 ψ c l s \psi_{cls} ψcls上的位置 ( x , y ) \left(x,y\right) (x,y)在输入图像上的对应位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor{\frac{s}{2}}\right\rfloor+xs,\left\lfloor{\frac{s}{2}}\right\rfloor+ys\right) (⌊2s⌋+xs,⌊2s⌋+ys)在bbox内,则将其视为正样本。s是backbone的步长(s = 8)。
对于特征图 ψ r e g \psi_{reg} ψreg上每个正样本 ( x , y ) \left(x,y\right) (x,y)的回归,最后一层预测对应位置 ( x , y ) \left(x,y\right) (x,y)到gt边框四条边的距离:四维向量 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^\ast=\left(l^\ast,t^\ast,r^\ast,b^\ast\right) t∗=(l∗,t∗,r∗,b∗):
l ∗ = ( ⌊ s 2 ⌋ + x s ) − x 0 l^\ast=\left(\left\lfloor\frac{s}{2}\right\rfloor+xs\right)-x_0 l∗=(⌊2s⌋+xs)−x0
t ∗ = ( ⌊ s 2 ⌋ + y s ) − y 0 t^\ast=\left(\left\lfloor\frac{s}{2}\right\rfloor+ys\right)-y_0 t∗=(⌊2s⌋+ys)−y0
r ∗ = x 1 − ( ⌊ s 2 ⌋ + x s ) r^\ast=x_1-\left(\left\lfloor\frac{s}{2}\right\rfloor+xs\right) r∗=x1−(⌊2s⌋+xs)
b ∗ = y 1 − ( ⌊ s 2 ⌋ + y s ) b^\ast=y_1-\left(\left\lfloor\frac{s}{2}\right\rfloor+ys\right) b∗=y1−(⌊2s⌋+ys)
其中 ( x 0 , y 0 ) 和 ( x 1 , y 1 ) \left(x_0,y_0\right)和\left(x_1,y_1\right) (x0,y0)和(x1,y1)表示左上角和右下角的角点。
G2 : 得分无歧义
直接对相应的图像块进行分类,并在该位置回归目标边框,即直接将位置视为训练样本。而基于锚点的目标(将输入图像上的位置视为多个锚框的中心)在相同位置会输出多个分类得分,并根据锚点回归目标边界框,这导致了每个位置的歧义性。
G3 : 无先验
没有预设的锚点和阈值,自然没有人工先验信息。
G4 : 预测质量的评估
直接使用分类得分来选择最终预测边框,可能会导致定位精度降低,因为分类置信度与定位精度没有很好的相关性。假设目标中心周围的特征像素比其他像素具有更好的估计质量。在分类head并行添加1×1卷积层来进行质量评估。该输出用于估计Prior Spatial Score(PSS),其定义如下:
P S S ∗ = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) × min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) \mathrm{PS}\mathrm{S}^\mathrm{*}=\sqrt{\frac{\min{\left(l^\ast,r^\ast\right)}}{\max{\left(l^\ast,r^\ast\right)}}\times\frac{\min{\left(t^\ast,b^\ast\right)}}{\max{\left(t^\ast,b^\ast\right)}}} PSS∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
也可以预测Iou得分:
I o U ∗ = I n t e r s e c t i o n ( B , B ∗ ) U n i o n ( B , B ∗ ) \mathrm{Io}\mathrm{U}^\mathrm{*}=\frac{\mathrm{\ Intersection\ } \left(B,B^\ast\right)}{\mathrm{\ Union\ }\left(B,B^\ast\right)} IoU∗= Union (B,B∗) Intersection (B,B∗)
B B B, B ∗ B^\ast B∗分别表示预测边框和对应的GT bbox。
Training Objective:
L ( { p x , y } , q x , y , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y 1 { c x , y ∗ > 0 } L q u a l i t y ( q x , y , q x , y ∗ ) + λ N p o s ∑ x , y 1 { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) \begin{array}{l} L\left(\left\{p_{x, y}\right\}, q_{x, y},\left\{{t}_{x, y}\right\}\right)=\frac{1}{N_{\mathrm{pos}}} \sum_{x, y} L_{\mathrm{cls}}\left(p_{x, y}, c_{x, y}^{*}\right) \\ +\frac{\lambda}{N_{\mathrm{pos}}} \sum_{x, y} \mathbf{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\mathrm{quality}}\left(q_{x, y}, q_{x, y}^{*}\right) \\ +\frac{\lambda}{N_{\mathrm{pos}}} \sum_{x, y} \mathbf{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\mathrm{reg}}\left({t}_{x, y}, {t}_{x, y}^{*}\right) \end{array} L({px,y},qx,y,{tx,y})=Npos1∑x,yLcls(px,y,cx,y∗)+Nposλ∑x,y1{cx,y∗>0}Lquality(qx,y,qx,y∗)+Nposλ∑x,y1{cx,y∗>0}Lreg(tx,y,tx,y∗)
其中1·是0-1分布的,即只对目标位置(正样本)进行计算。 L c l s L_{\mathrm{cls}} Lcls表示分类的focal loss, L q u a l i t y L_{\mathrm{quality}} Lquality表示质量评估的交叉熵损失, L r e g L_{\mathrm{reg}} Lreg表示预测边框的IoU损失。
实验:
消融实验(Backbone、Head、Head structure、Quality assessment)

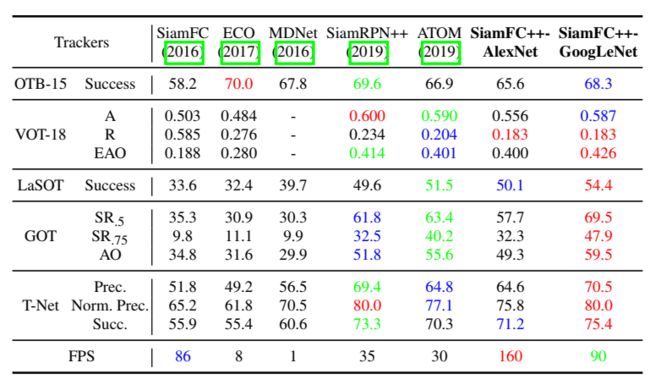
不同数据集上的横向对比:
作者在VOT2018数据集上记录了SiamRPN ++和SiamFC ++产生的最高分,然后根据跟踪结果成功或失败进行拆分。结果与Groundtruth的重叠为零,则视为失败;否则成功。
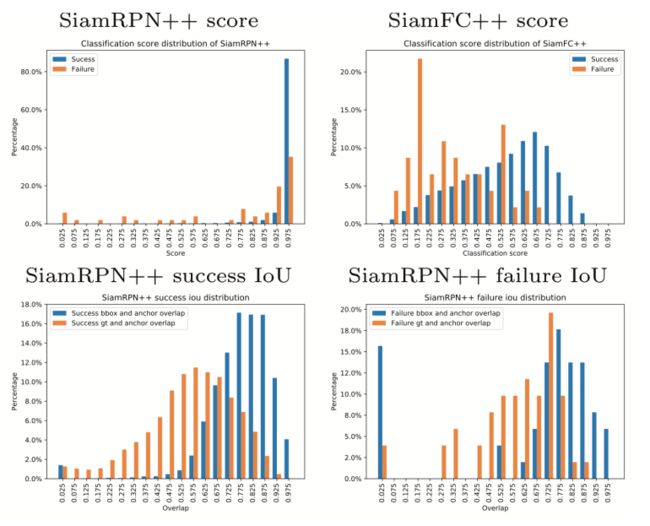
第一行中比较SiamRPN ++和SiamFC ++分数,SiamRPN ++的分类分数不管成功与否,都具有相似的分布方式。SiamFC ++的分布更为合理:跟踪成功应当集中分布于高得分位置,失败应当集中分布于低分位置。
第二行绘制了成功和失败状态下输出边界框和gt之间IoU分布的直方图。基于锚点的方式会导致目标状态估计产生偏差,SiamRPN ++的预测框倾向于与锚框重叠而不是与gt重叠。