ICTCLAS分词系统研究(一)
ICTClAS分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统,难能可贵的是该版的Free版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是,该源代码没有配套的文档,阅读起来可能有一定的障碍,尤其是对C/C++不熟的人来说.本人就一直用Java/VB作为主要的开发语言,C/C++上大学时倒是学过,不过工作之后一直没有再使用过,语法什么的忘的几乎一干二净了.但语言这东西,基本的东西都相通的,况且Java也是在C/C++的基础上形成的,有一定的相似处.阅读一遍源代码,主要的语法都应该不成问题了.
虽然在ICTCLAS的系统中没有完整的文档说明,但是我们可以通过查阅张华平和刘群发表的一些相关论文资料,还是可以窥探出主要的思路.
该分词系统的主要是思想是先通过CHMM(层叠形马尔可夫模型)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率.共分五层,如下图一所示:
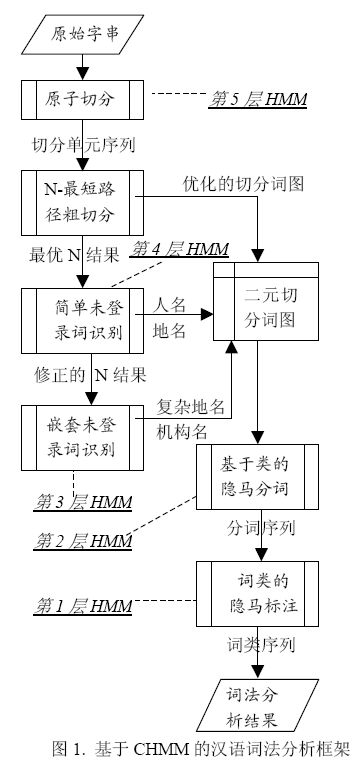
基本思路:先进行原子切分,然后在此基础上进行N-最短路径粗切分,找出前N个最符合的切分结果,生成二元分词表,然后生成分词结果,接着进行词性标注并完成主要分词步骤.
下面是对源代码的主要内容的研究:
1.首先,ICTCLAS分词程序首先调用CICTCLAS_WinDlg::OnBtnRun()开始程序的执行.并且可以从看出它的处理方法是把源字符串分段处理。并且在分词前,完成词典的加载过程,即生成m_ICTCLAS对象时调用构造函数完成词典库的加载。关于词典结构的分析,请参加分词系统研究(二)。
void CICTCLAS_WinDlg::OnBtnRun()
{
......
//在此处进行分词和词性标记
if(!m_ICTCLAS.ParagraphProcessing((char *)(LPCTSTR)m_sSource,sResult))
m_sResult.Format("错误:程序初始化异常!");
else
m_sResult.Format("%s",sResult);//输出最终分词结果
......
}
2.在OnBtnRun()方法里面调用分段分词处理方法bool CResult::ParagraphProcessing(char *sParagraph,char *sResult)完成分词的整个处理过程,包括分词的词性标注.其中第一个参数为源字符串,第二个参数为分词后的字符串.在这两个方法中即完成了整个分词处理过程,下面需要了解的是在此方法中,如何调用其它方法一步步按照上图所示的分析框架完成分词过程.为了简单起见,我们先不做未登录词的分析。
//Paragraph Segment and POS Tagging
bool CResult::ParagraphProcessing(char *sParagraph,char *sResult)
{
........
Processing(sSentence,1); //Processing and output the result of current sentence.
Output(m_pResult[0],sSentenceResult,bFirstIgnore); //Output to the imediate result
.......
}
3.主要的分词处理是在Processing()方法里面发生的,下面我们对它进行进一步的分析.
bool CResult::Processing(char *sSentence,unsigned int nCount)
{
......
//进行二叉分词
m_Seg.BiSegment(sSentence, m_dSmoothingPara,m_dictCore,m_dictBigram,nCount);
......
//在此处进行词性标注
m_POSTagger.POSTagging(m_Seg.m_pWordSeg[nIndex],m_dictCore,m_dictCore);
......
}
4.现在我们先不管词性标注,把注意力集中在二叉分词上,因为这个是分词的两大关键步骤的第一步.
参考文章:
1.<<基于层叠隐马模型的汉语词法分析>>,刘群 张华平等
2.<<基于N-最短路径的中文词语粗分模型>>,张华平 刘群