pytorch + visdom AutoEncode 和 VAE(Variational Autoencoder) 处理 手写数字数据集(MNIST)
环境
系统:win10
cpu:i7-6700HQ
gpu:gtx965m
python : 3.6
pytorch :0.3
数据
使用 mnist,使用方法前面文章有。
train_dataset = datasets.MNIST('./mnist', True, transforms.ToTensor(), download=False)
train_loader = DataLoader(train_dataset, BATCH_SIZE, True)并非分类问题,只要训练集就可以,不需要测试集。
可视化一下数据:
dataiter = iter(train_loader)
inputs, _ = dataiter.next()
inputs = inputs[:20]
# 可视化visualize
viz.images(inputs, nrow=8, padding=3)
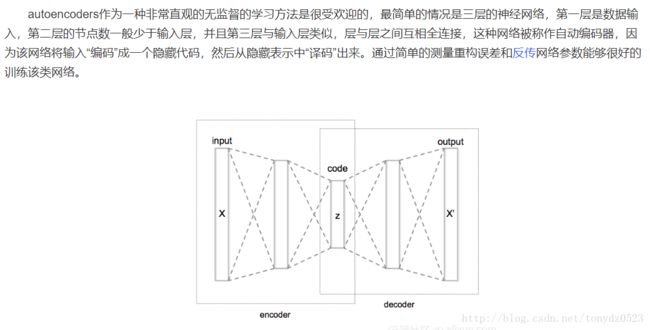
AutoEncoder (自编码)
自编码是什么呢,百度找的解释:
我们结合简单的神经网络看,更直观一些:
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.Tanh(),
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3),
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid(),
)
自编码分为两个部分:编码(encode),解码(decode);编码就是说把输入的东东,通过神经层(编码过程)提炼出 n 个 特征点,上面的神经网络是 3 个 ,输出的这n 个 特征点就是 得到的 code ,经过解码过程将这个提炼的 code 反向输出,生成原尺寸数据,根据与原数据对比(loss),来判断特征值是否为最优,通过反复训练学习,可以获得具有原图一类共同特征的图片,但是也有缺点,就是由于兼顾所有,导致图像模糊。
我们训练10个 epochs看一下效果:

发下生成的图从模糊逐渐能看清数字,但是3和8,7和9 搞不清楚。。
接下来,我们把简单的nn,换成cnn,看看效果如何。。
self.en_conv = nn.Sequential(
nn.Conv2d(1, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.Tanh(),
nn.Conv2d(16, 32, 4, 2, 1),
nn.BatchNorm2d(32),
nn.Tanh(),
nn.Conv2d(32, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.Tanh()
)
self.en_fc = nn.Linear(16*7*7, 3)
self.de_fc = nn.Linear(3, 16*7*7)
self.de_conv = nn.Sequential(
nn.ConvTranspose2d(16, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.Tanh(),
nn.ConvTranspose2d(16, 1, 4, 2, 1),
nn.Sigmoid()
)10个epoch后 效果图:

我们在训练结束后将一部分测试集数据导入取其编码,因为是3个值,用3d散点图可视化:
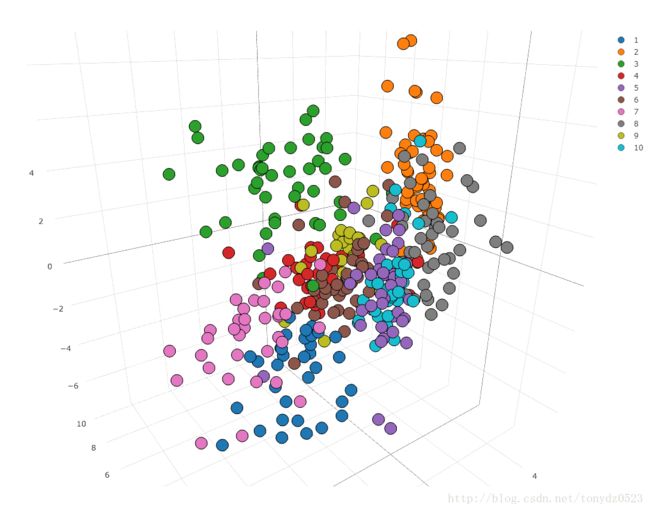
(注:图中标签1~10,其实为0~9)
可见4、9比较相似难以区分, 3、5、8相似
代码在这 。。
VAE(Variational Autoencoder)
由于Autoencoder 只是在数据原有的基础上进行学习,生成的数据的局限性很大,不能在原数据基础上合理的生成新数据, 而VAE可以通过对编码器添加约束,强迫它产生服从单位高斯分布的潜在变量。
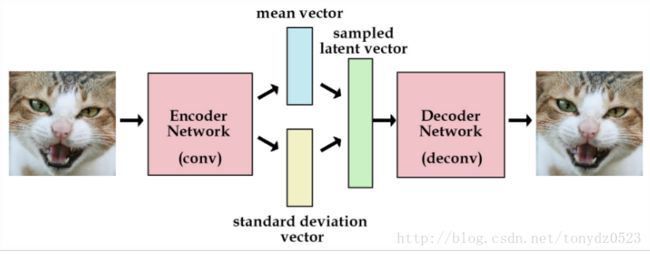
VAE的编码器会产生两个向量:一个是均值向量,一个是标准差向量,根据两个向量对高斯分布的拟合度上进行权衡,加上生成图片的准确度,生成新的loss值。

根据生成的两个向量生成新的向量,用以产生随机的潜在变量,提高net 的生成图片的能力。

网络如下:
self.conv1 = nn.Sequential(nn.Conv2d(1, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.ReLU(True))
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 4, 2, 1),
nn.BatchNorm2d(32),
nn.ReLU(True))
self.conv3 = nn.Sequential(nn.Conv2d(32, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.ReLU(True))
self.fc_encode1 = nn.Linear(16 * 7 * 7, hidden_size)
self.fc_encode2 = nn.Linear(16 * 7 * 7, hidden_size)
self.fc_decode = nn.Linear(hidden_size, 16 * 7 * 7)
self.deconv1 = nn.Sequential(nn.ConvTranspose2d(16, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.ReLU())
self.deconv2 = nn.Sequential(nn.ConvTranspose2d(16, 1, 4, 2, 1),
nn.Sigmoid())
3个hidden 10个epochs ,效果如下:

数字已经有明显的形态,不过不够清晰,我们用10个hidden,训练18个epochs:

增加隐藏层后,发现效果明显比之前好很多,7个epoch就已经形状相仿了。
将hidden设置为3,画3d 散点图如下:
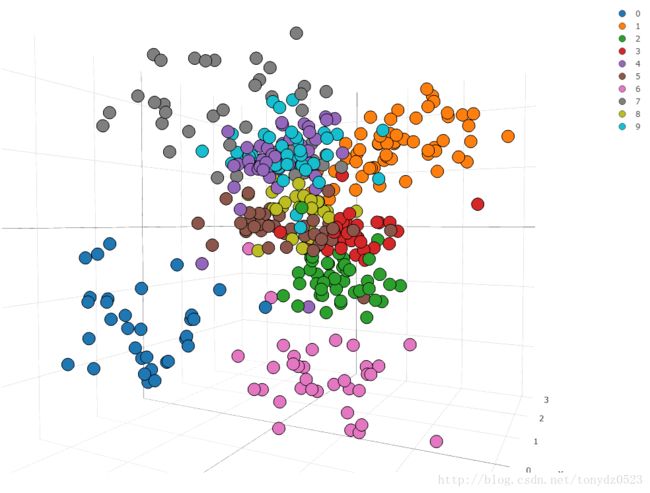
代码在这。