如何到top5%?NLP文本分类和情感分析竞赛总结
转自公众号 AI圈终身学习(ID:AIHomie)
因为微信外链限制,读者可以在公众号AI圈终身学习(ID:AIHomie)首页回复**“2018竞赛”**,获得我所有的比赛代码。
目录:
-
文本分类任务介绍
-
文本分类问题Pipeline
-
文本表示
-
模型介绍
-
后处理-模型融合和半监督学习
-
其他trick
写在前面
从2018年9月初-12月初,笔者主要做了三个比赛,成绩如下:
- CCL 2018中移在线客服领域用户意图分类 冠军
- CCF-BDCI 2018年汽车行业用户观点主题及情感识别挑战赛 排名6/1701
- 达观杯 2018长文本分类智能处理挑战赛 排名18/3462
笔者主要方向是KBQA,深深体会到竞赛是学习一个新领域最好的方式,这些比赛总的来说都属于文本分类领域,因此最近打算一起总结一下。
我也是小白,但是竞赛要取得好的名次我觉得比较简单,因为最重要的direction已经给你定好了(可以多思考学习举办方的出题方向和方式),也不用考虑落地问题,剩下的都是偏竞赛方面的技术问题,所以竞赛拿到好的名次并不代表这个人多牛。但是只要**态度端正,不眼高手低,付出一定的时间成本,就能做到前排。**那么具体怎么做呢?我慢慢介绍。
一、文本分类任务介绍
文本分类任务的目标是想办法预测出文本对应的类别,是NLP的基础任务。因为数据标注成本相对于其他任务低廉很多,因此有大量的标注数据可以训练模型,这是文本分类性能目前相对较好的重要原因。
接下来我依次介绍三个比赛的任务描述,如果您看完这节迷迷糊糊,请把达观杯的任务描述和目标记住就好。
1.1 达观杯任务描述
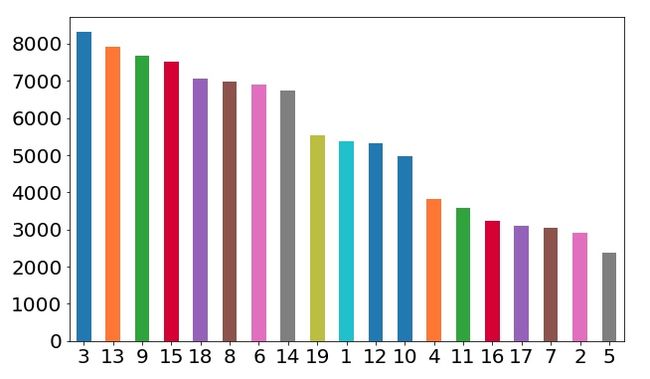
达观杯是一个长文本分类问题,最长的句子超过1w个词。文本进行过脱敏处理,任务目标是判断文本数据属于什么类别,类别总共有19种。比如给你一段新闻文章,判断文章属于经济、政治还是娱乐或者其他的类别。如图,横坐标是种类名称(脱敏的),纵坐标是对应的语料数量。
1.2 CCL中移在线任务描述
中移在线比赛是一个长文本多分类问题,和达观杯的主要区别是类别的层次增加了,也就是说类别是树状结构。
该题的目标是通过10086的语音转对话文本,判断用户的意图。比如下图的一个例子,其中1代表客服,2代表客户,然后根据对话文本内容判断改用户来电意图类别是“办理>>下载/设置”:
1 您好请说
2 哎那天只能提醒
1 转来电提醒是吧
2 行行好的哎
1 就把所有的电话都在来电提醒吗
2 好的
1 好呀请稍等那我帮你设置好了所有的电话都转来电提醒了还需要其他帮助吗
2 不用
1.3 BDCI汽车领域主题情感分析任务描述
BDCI这个题虽然是情感分析,但是也可以属于文本分类领域。
语料举例如下:
评论文本:斯柯达要说配置,似乎比大众要好一点,价格也低一些,用料完全一样。我听说过野帝,但没听说过你说这车。
情感分析结果:①价格 正向情感 ②配置 正向情感
本题主要是根据用户对汽车的评论文本,分析用户的主题和对应的情感,比如上面的主题就是价格和配置,都对应正向情感。
本题的主题有十种:动力、价格、内饰、配置、安全性、外观、操控、油耗、空间、舒适性。
情感有三类:正向、中立、反向。
情感分析学术上可以分为ASC和TSC问题,本题属于ASC问题。不了解也没关系,这不是重点。
1.4 评价指标
F 1 = 2 P R P + R F_1 = \cfrac{2PR}{P+R} F1=P+R2PR
二、文本分类问题Pipeline
我也不搞那些花里胡哨的了,机器学习和深度学习的文本分类pipeline我觉得都可以用这张图表示:
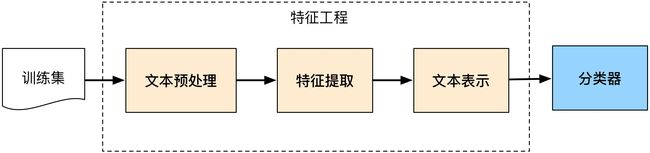
只是区别在于:
- 机器学习提取的是如tf-idf的具体(concrete)特征
- 深度学习提取的是如词向量的抽象(abstract)特征
对于分类器,传统的朴素贝叶斯分类、SVM、XGB、LGB算法,在NLP竞赛中都不太好使,因此NLP比赛里用到的基本都是深度学习。对照着pipeline,竞赛中最重要的两步就是:
- 做好文本表示工作,可以简单理解成词向量训练,即做好**“数据–>信息”**的流程
- 做好分类器,可以理解成模型的设计,即做好**“信息–>知识”**的流程
三、文本表示
3.1 语义粒度与文本长度
语义粒度是指对文本是否分词,以词还是以字来表示一个句子的输入特征。一般来讲,我们都需要对他们进行尝试,只要效果不相差太多,我们都需要保留,为最后的模型融合增加差异性。
文本长度我一般用占比95%或者98%的长度最为最大长度,对超过最大长度的句子进行截取,不足的进行填充(padding)。
另外就是对句子进行padding的时候,keras补0默认是补在前面,我想了下这应该是RNN结构的隐藏层参数空间最开始初始化为0,有个冷启动过程,所以我觉得补在前面是不错的。
3.2 词向量选择
我们知道,Word2Vec和GloVe近几年在文本表示中几乎处于垄断地位,在比赛中几乎都是用他们来做文本表示,所以寻找好的词向量是比赛的关键点。如果数据没有脱敏,可以直接用github上训练好的词向量;否则就自己训练。
这里面有一个重要的trick是拼接Word2Vec和GloVe作为新的特征输入会对模型由一定提升效果,直接相加或者求平均效果通常都不好。
在单种词向量维度选择上,一般要费点时,加上拼接的话需要做的测试就更多了。而且不同模型上表现也不一样,最后大概率也选不到最佳维度,做这种事情心里都会觉得草蛋,但是心态要平和。这也是我为什么觉得态度端正,不要眼高手低非常重要。
当然,牛逼的人总是会想办法自动找一下最合适的词向量维度,感兴趣的同学可以看看NeurIPS 2018斯坦福的这篇论文《On the Dimensionality of Word Embedding》。
3.3 语言模型词向量
今年做比赛是幸运的,因为新出了语言模型词向量,比较出名的是ULMFit、ELMo和BERT。他们的效果基本都能甩词向量几个点。
Word2Vec等词向量的缺点是只包含模型第一层的先验知识,模型的其余部分依旧需要从头训练。而语言模型改为采用分层表示的方式,用以解决语义依赖等问题。我们以ELMo为例:
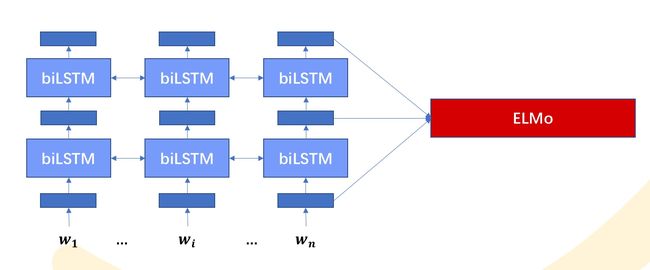
他最低层先用词向量(比如Word2Vec)表示,然后再过两层双向LSTM语言模型,将三层的输出按一定方式组合作为特征表示。
比如这两句话:
我 今天 吃了 个 苹果 。
苹果 股价 又跌了 。
对“苹果”这个词,用Word2Vec表示,两个结果都是一样的;但是ELMo就能考虑上下文语义输出两种更符合语义的不同表示。
因为我们需要预训练语言模型,因此这就很像图像领域的迁移学习:先根据大规模语料训练好网络的一部分,然后用这部分网络接个分类器在小规模语料上重新finetune提高性能。
有了语言模型词向量最好的一点是,我们可以不用太纠结Word2Vec和GloVe的词向量维度选择了,可以选一个200维或者300维的最后再一起融合就好了。
四、模型介绍
我们已经通过文本表示技术将”文本数据转化为信息“,而文本分类模型就是将”信息转化为知识“。文本分类模型非常多,我们可以借鉴第一性原理去理解他们,会轻松一些。
我觉得文本分类最重要的是抓取关键词,而影响关键词抓取最重要的一点是文本的长度,就像人类做阅读题一样,越长的内容越难把握住重心。但是如果我们过于优化长文本性能,在短文本上的性能就会受到影响。因此我们关注的重点是:
- 关键词特征
- 长文本
- 短文本
我们将所有的神经网络组件和功能拆解,可以分成这几种:

这样看就很少了。功能解释都是我在亲自实验中的感悟,如果没看懂我解释一下。
对于短文本,CNN配合Max-pooling池化(如TextCNN模型)速度快,而且效果也很好。因为短文本上的关键词比较容易找到,而且Max-pooling会直接过滤掉模型认为不重要特征。虽然Attention也突出了重点特征,但是难以过滤掉所有低分特征。而Capsules效果比CNN好,所以我个人觉得在短文本上LSTM/GRU+Capusules是一个不错模型,这也是目前Kaggle Quora比赛上(短文本分类)最好的baseline之一。
但是对于长文本直接用CNN就不行了,在客服领域意图分类任务里,TextCNN会比HAN模型低十多个点,几乎没法用。当然我们可以在TextCNN前加一层LSTM,这样效果就能提升很多。
神经网络组件的功能大概就是这样,读者可以根据自己的理解尝试排列组合再调参。
下面简单介绍下笔者用过的两个比较经典的文本分类算法。当然比赛中用的模型可能有十个左右,所有的代码地址,我已经在文首交代过了。有兴趣可以看看。
4.1 TextCNN
CNN家族在文本分类比较出名的就是Kim的TextCNN和kaiming的DPCNN,DPCNN我还没有跑出过比较好的结果,就介绍下TextCNN。
如果TextCNN卷积核宽度为2、3、4,每种卷积核的个数为2的话,那么它长这个样:
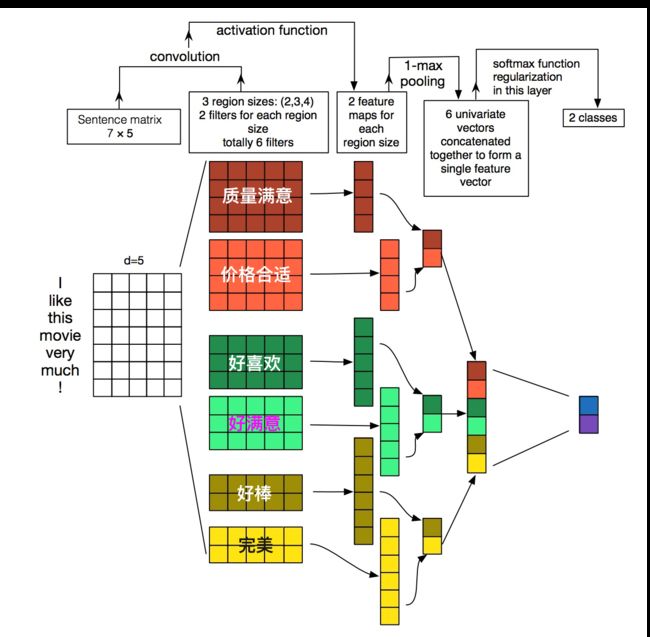
他的工作机制是:卷积窗口沿着长度为n的文本一个个滑动,类似于n-gram机制对文本切词,然后和文本中的每个词进行相似度计算,因为后面接了个Max-pooling,因此只会保留和卷积核最相近的词。这就是TextCNN抓取关键词的机制。
我一般喜欢在CNN前面加一层LSTM,效果相对不错。也可以把CNN换成Capsules组合成新模型。关于Capsules本文不多介绍了,有兴趣可以看看苏剑林大佬的博客和Capsules在文本分类中的研究。
4.2 HAN模型
前几年Attention才出来的时候,一个段子说,只要一个LSTM+Attention就能通吃所以的NLP任务。这个模型确实有效,但是比较简单我就不介绍了。RNN族比较出名的文本分类模型是RCNN和HAN模型,这里介绍下HAN模型,其他的模型有兴趣的读者可以读论文或者看看我的代码。HAN的论文名称是《Hierarchical Attention Networks for Document Classification》,它长这个样子:
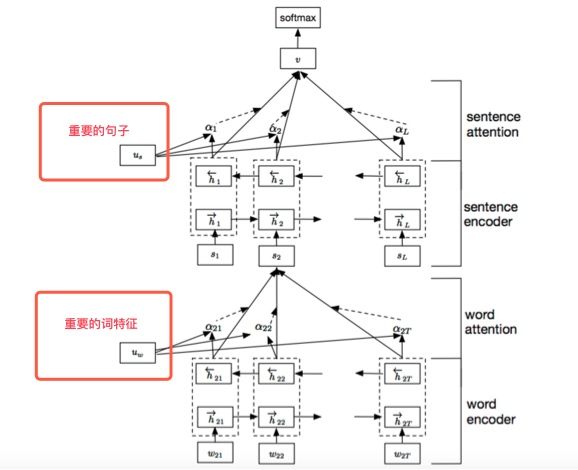
它主要是将长句按照句号划分成若干条句子,对每条句子用Attention做重要词特征抽取后进入下一级,下一级对所有的重要句做特征抽取后用MLP分类。更具体的可以看这个图:
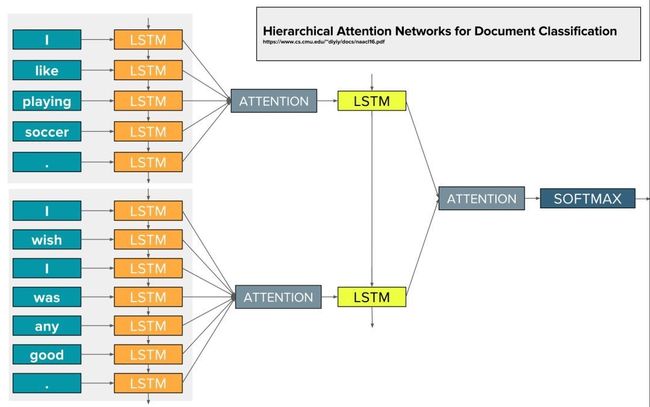
**可能有读者会疑惑,那么对于脱敏文本怎么办呢?怎么识别句号?**在多个数据集上做个试验的朋友肯定知道,只要是正常的中文语料,训练词向量频次第二高的几乎都是句号,第一高的一般是逗号,随意截个图感受下:
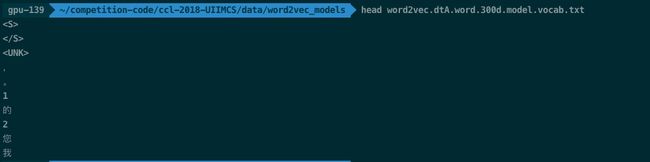
因此大胆的用第二高频词划分,不放心再看看切分后的句子数量,在词和字级别上数量是否相等即可。因为如果第二高频词不是符号而是字,切分后的句子数量肯定是不等的。
我们用这个模型的时候尝试了下ELMo和Word2Vec的拼接,下面是一个HAN模型词向量拼接的模型,调一下参效果也还行,主要也还是为了最后的模型融合,增加模型多样性。
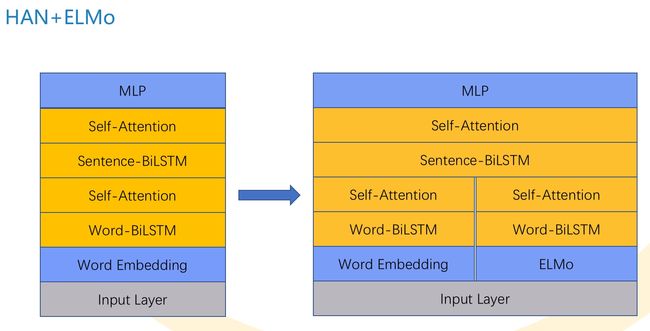
五、后处理
5.1 模型融合
一般比赛做到最后都会有几十上百个模型结果,所以我也是很偷懒的用的oof(out-of-fold)文件做Stacking:
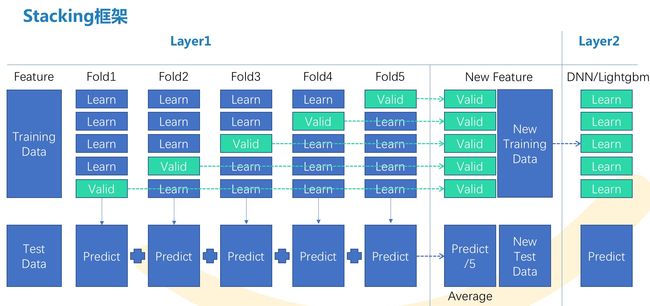
我们以达观杯为例,具体流程是:
- 每个模型做交叉验证(比如10折),然后把验证集得到的概率结果拼一起,组成一个oof训练集。比如达观杯的一个oof shape为(102722, 19),因为有19个类别。
- 假如我们有10个不同的模型,最后我们把10个oof结果拼一起(102722, 190),再通过分类器拟合成(102722, 19)即可。
- 对测试集的处理,把每个模型的加权平均即可。
俗话说一码胜千言,如果你看不懂我在说什么,建议你看一下下代码,非常少,也很容易理解。
5.2 假标签(Pseudo Label)
假标签是一种半监督方法:
- 通过训练集训练好的模型,去预测测试集的结果
- 把测试集这个结果作为测试集的标签,和训练集混合在一起训练模型
一般模型能忍受10%的噪音,所以建议假标签方法不要一股脑把所有测试集和训练集混合,尽量保持比例在10:1附近。
六、其他的Trick
关于Finetune学习率我觉得很多人过于看重了,最开始我看大家都说Finetune很重要,所以我都是按照Finetune的方式去训练的,比如:
- 微调Embedding学习率。
- 训练过程中,验证集得分或loss变差,重新加载上一轮的模型,并降学习率降半。
- Snapshot Ensemble。
其实强扭的瓜不甜,这样容易线下验证集过高导致过拟合。我后面重新跑了达观杯,不Finetune在线上的效果就比Finetune的效果好。但是ULMFit的那个三角学习率好像大家都说效果不错,可能我的姿势还不太对,暂时先随缘吧。
相对于Finetune,Hinton的蒸馏方法更加的稳定有效。由于本文我已经写了很多了,这里蒸馏就不细讲了,有兴趣的同学可以一起探讨。
由于篇幅有限,情感分析的具体模型区别这里也暂时先不写了,后面补上。
致谢
最后要感谢实验室导师的帮助,以及比赛期间一起坚持相互打劲的队友zzk、hzq、jetou、fjj,我们最近在一起搭建非盈利开源学习平台-AI圈,欢迎您的加入。
如果读者对于文中出现的模型构建或者其他问题有疑惑,可以在公众号AI圈终身学习(ID:AIHomie)首页回复**“2018竞赛”**,获得我所有的比赛代码。
感谢阅读,希望这篇文章能对您有所帮助。
