CMU SPHINX介绍
对于CMU Sphinx-4进行相关简单的介绍,并对其中的一些功能和使用进行相关说明。
Introduction:
CMU Sphinx:
由卡内基梅隆大学制作的用于语音识别的开源工具箱。
CMU Sphinx-4:
Sphinx-4是完全用Java语言写的先进的语音识别系统。它是通过卡内基梅隆大学Sphinx组,Sun微系统实验室、三菱电器研究实验室、惠普等联合完成的,同时美国加州大学圣克鲁斯分校和麻省理工学院也对其有贡献。
Capabilities:
1.实时模式以及批处理模式下的语音识别,能够识别离散和连续的语音。
2.通用可插拔的前端结构。包括实现预加重、汉明窗、FFT、Mel频率滤波器、离散余弦变换、倒谱均值归一化、倒谱的特征值提取,增量倒谱,双增量倒谱特征。
3.通用可插拔的语言模型结构。包括可插拔语言模型支持单元组、二元组、三元组、Java Speech API语法格式以及ARPA-格式FST文法的ASCII和二进制版本。
4.通用的声学模型结构。包括可插拔的支持Sphinx-3声学模型。
5.通用的搜索管理。包括可插拔的支持广度优先和字修剪搜索。
6.一些对于处理后的识别结果,包括获得的可信度分数,生成的格子以及嵌入到JSGF标签中的ECMAScript
7.独立的工具。包括用于显示波形图和频谱图,从音频中产生特征。
Performance:
Sphinx-4是一个复杂的系统,能够执行许多不同类型的识别任务。因此,很难用Sphinx-4对于一些简单数字的识别精度和速度来衡量性能。取而代之,通常会做一些在Sphinx-4上的回归测试来决定如何在多种多样的任务下执行。这些任务和最后的结果如下(每个任务的难度依次递增):
·孤立数字(TI46):用事先录制好的测试数据来运行Sphinx-4,收集在一时间识别一个字的性能。 这个词汇表仅仅是从0-9的孤立话语,只包含一个数字以及一个单一的话语。
·连续数字(TIDIGITS):扩展单个字来识别同一时间的更多的字(如,连续话语)。词汇仅仅是从0到9的数字话语,用一个单一的话语包含的数字序列。
·小词汇集(AN4):扩展词汇到大约100个词,从说话词汇的输入数据范围来讲,就如同一个字母一个字母的把单词拼出来。
·中等词汇集(RM1):扩展词汇到大约1000次。
·中等词汇集(WSJ5K):扩展词汇到大约5000次。
·中等词汇集(WSJ20K):扩展词汇到大约20000次。
·大词汇集(HUB4):扩展词汇集到大约64000次。
下面的图表是Sphinx 3.3与Sphinx 4的性能对比:
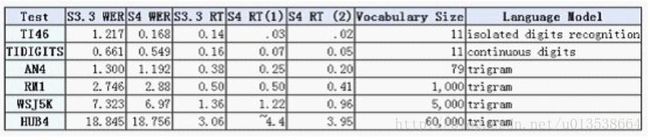
其中HUB4测试的性能是不完全的。
key:
· WER - word error rate (%) (lower is better)
· RT - Real Time - Ratio of processing time to audio time - (lower is better )
· S3.3 RT - Results for a single or dual CPU configuration
· S4 RT(1) - Results on a single - CPU configuration
· S4 RT(2) - Results for a dual - CPU configuration
Downloading Sphinx-4:
· Sphinx4-{version}-bin.zip:提供jar包文件,文档和实例。
· Sphinx4-{version}-src.zip:提供源、文档、实例,单元测试和回归测试。
Demos:
简单例子:Hello World Demo: 识别简单的短语
Hello N-Gram Demo: 运用N元语言模型来进行识别
语音文件转录的例子:
Transcriber Demo: 一个简单的例子来展示如何转录有多个离散词语的连续语音文件
Confidence Demo: 展示如何获得结果的可信度
Lattice Demo: 展示如何从识别结果中提取点阵
Class-Based Language model Demo: 展示一个基于分类的语言模型
Aligner Tags Demo: 对齐音频文件来转录并且获得字的时间。可用于隐藏式字幕。
一些先进的对话系统例子:
ZipCity Demo: 一个Java应用,通过识别字串儿来定位城市的位置
JSGF Demo: 展示程序如何在复杂的JSGF语法中交换
Dialog Demo: 展示程序如何在复杂的JSGF语法和听写语法中交换
Action Tags Demo: 展示如何使用动作标签来后处理从JSGF中得到的RuleParse对象
Sphinx-4 Frequently Asked Questions:
General:
Who created Sphinx-4?
I have a question about Sphinx-4. How can I get it answered?
How can I contact the Sphinx-4 team?
Which Sphinx-4 distribution should I use?
Sphinx-4:
I want to add speech recognition to my application. Where do I start?
How can I decode/transcribe .wav files?
How can I get the N-Best list?
How can I detect and ignore out-of-grammar utterances?
How can I change my language models or grammars at runtime?
How can I perform word-spotting?
Java:
How well does Sphinx-4 perform compared to other speech recognizers?
Isn't the Java Platform too slow to be used for speech recognition?
Does Sphinx-4 support the Java Speech API (JSAPI)?
Where can I learn more about the Java Speech Grammar Format (JSGF)?
Can I use Sphinx-4 in a J2ME device such as a phone or a PDA?
Why can't I use Java versions prior to 1.4?
I am having microphone troubles under linux. What can I do?
Acoustic & Language Models:
How can I train my own acoustic models?
How do I use models trained by SphinxTrain in Sphinx-4?
How can I create my own language models?
Development Javadoc:
javadoc:
各种类和包的介绍可以供编程开发的时候查找。