逻辑(斯谛)回归(Logistic Regression)
文章目录
- 1. 逻辑斯谛分布
- 2 二元逻辑斯谛回归
- 3 模型参数估计
GitHub
简书
CSDN
在我们学习机器学习的过程中,我们所需解决的问题,大致可以分为两部分:分类和回归.其中,分类是指模型用来预测一个有限的离散值集合中的一个,比如猫狗分类,肿瘤的恶性或良性; 回归是指模型的输出是一个连续变量,比如预测房价、身高等.本篇内容讲解的是机器学习中经典的逻辑(斯谛)回归(Logistic Regression),从名字上看,大家误以为该方法是一种回归方法,其实不然,它是分类方法的一种,常用于二元分类,但是为什么会取名回归,我个人理解大致有如下几点原因:
1. 利用回归的思想来解决分类问题;
2. 它的输出也是一个连续值,通过设定阈值来实现分类
1. 逻辑斯谛分布
定义:设X是连续随机变量,X服从逻辑斯谛分布是指X具有下列分布函数和密度函数:
(1) F ( x ) = P ( X ≤ x ) = 1 1 + e − ( x − u ) / γ F(x)=P(X \leq x)=\frac{1}{1+e^{-(x-u)/\gamma}} \tag{1} F(x)=P(X≤x)=1+e−(x−u)/γ1(1)
(2) f ( x ) = F ′ ( x ) = e − ( x − μ ) γ γ ( 1 + e − ( x − u ) / γ ) 2 f(x)=F^{'}(x)=\frac{e^{-(x-\mu)\gamma}}{\gamma(1+e^{-(x-u)/\gamma})^2} \tag{2} f(x)=F′(x)=γ(1+e−(x−u)/γ)2e−(x−μ)γ(2)
其中, μ \mu μ为位置参数, γ > 0 \gamma > 0 γ>0为形状参数.
该函数以点 ( μ , 1 2 ) (\mu, \frac{1}{2}) (μ,21)为中对称,既有如下关系:
(3) F ( − x + μ ) = 1 − F ( x + μ ) F ( − x + μ ) − 1 2 = F ( x + μ ) + 1 2 \begin{aligned} F(-x+\mu) &= 1 - F(x+\mu)\\ F(-x+\mu)-\frac{1}{2} &= F(x + \mu) + \frac{1}{2} \end{aligned} \tag{3} F(−x+μ)F(−x+μ)−21=1−F(x+μ)=F(x+μ)+21(3)
形状参数 γ \gamma γ的值越小,曲线在中心附近增长的越快.该函数的图形如下图所示:
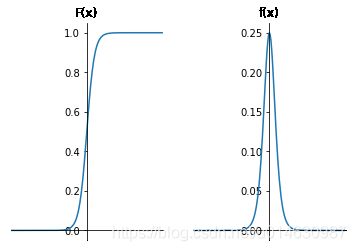
图一 逻辑斯谛分布的分布函数和密度函数
2 二元逻辑斯谛回归
二元逻辑斯谛回归模型是一种分类模型,有条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)表示,X取值为实数,随机变量 Y 取值为 1或0;
逻辑斯谛回归模型的条件概率如下:
(4) p ( Y = 1 ∣ x ) = e x p ( w ⋅ x + b ) 1 + e x p ( w ⋅ x + b ) = 1 1 + e x p ( − ( w ⋅ x + b ) ) P ( Y = 0 ∣ x ) = 1 1 + e x p ( ( w ⋅ x + b ) ) \begin{aligned} p(Y=1|x)&=\frac{exp(w\cdot x+b)}{1+exp(w\cdot x+b)}=\frac{1}{1+exp(-(w\cdot x+b))} \\ P(Y=0|x)&=\frac{1}{1+exp((w\cdot x+b))} \end{aligned} \tag{4} p(Y=1∣x)P(Y=0∣x)=1+exp(w⋅x+b)exp(w⋅x+b)=1+exp(−(w⋅x+b))1=1+exp((w⋅x+b))1(4)
这里, $ x \in R^n 表 示 样 本 的 特 征 向 量 , 表示样本的特征向量, 表示样本的特征向量,Y \in {0, 1}$是输出表示样本的类别, w ∈ R n w \in R^n w∈Rn 和 $ b \in R 是 模 型 的 参 数 , 其 中 , 是模型的参数,其中, 是模型的参数,其中,w$ 表示权重向量, b b b表示偏置。 w ⋅ x w \cdot x w⋅x表示 w w w和 x x x的内积.通常为了方便,我们将样本和权重向量进行扩充,仍记作 w w w和 b b b:
w = ( w 1 , w 2 . . . w n , b ) w = (w^1, w^2... w^n, b) w=(w1,w2...wn,b)
x = ( x 1 , x 2 . . . x n , 1 ) x = (x^1, x^2...x^n, 1) x=(x1,x2...xn,1)
此时逻辑斯蒂回归模型记作:
(5) p ( Y = 1 ∣ x ) = e x p ( w ⋅ x ) 1 + e x p ( w ⋅ x ) P ( Y = 0 ∣ x ) = 1 1 + e x p ( ( w ⋅ x ) ) \begin{aligned} p(Y=1|x)&=\frac{exp(w\cdot x)}{1+exp(w\cdot x)} \\ P(Y=0|x)&=\frac{1}{1+exp((w\cdot x))} \end{aligned} \tag{5} p(Y=1∣x)P(Y=0∣x)=1+exp(w⋅x)exp(w⋅x)=1+exp((w⋅x))1(5)
几率是指一个事件发生与不发生的概率比值,即 p 1 − p \frac{p}{1-p} 1−pp
则它的对数几率为 l n i t ( p ) = l o g p 1 − p lnit(p)=log \frac{p}{1-p} lnit(p)=log1−pp,对于逻辑斯蒂回归回归而言,其对数几率为
(6) l o g i t ( P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) ) = w ⋅ x logit(\frac{P(Y=1|x)}{1-P(Y=1|x)})=w \cdot x \tag{6} logit(1−P(Y=1∣x)P(Y=1∣x))=w⋅x(6)
3 模型参数估计
对于给定的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) . . . ( x n , y x ) } T=\{(x_1, y_1), (x_2, y_2)...(x_n, y_x)\} T={(x1,y1),(x2,y2)...(xn,yx)},可以应用极大似然估计(使模型预测的标签为真是标签的值最大化)模型参数,从而得到最优的逻辑斯蒂回归模型。
首先,设 P ( Y = 1 ∣ x ) = π ( x ) , P ( Y = 0 ∣ x ) = 1 − π ( x ) P(Y=1|x)=\pi(x), P(Y=0|x)=1-\pi(x) P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x),则似然函数为:
(7) ∏ i = 1 n [ π ( x ) ] y i [ 1 − π ( x ) ] 1 − y i = ∏ i = 1 n y i π ( x i ) + ( 1 − y i ) ( i − π ( x i ) ) \begin{aligned} \prod_{i=1}^n[\pi(x)]^{y_i}[1-\pi(x)]^{1-y_i}=\prod_{i=1}^n{y_i\pi(x_i)+(1-y_i)(i-\pi(x_i))} \end{aligned} \tag{7} i=1∏n[π(x)]yi[1−π(x)]1−yi=i=1∏nyiπ(xi)+(1−yi)(i−π(xi))(7)
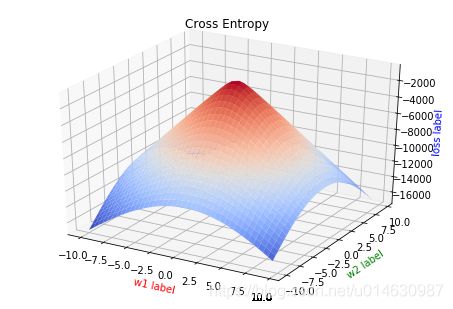
极大似然函数和交叉熵的树学公式形式时一摸一样的,但是他们背后的数学原理略有不同。
通常在处理优化问题时,我们都利用对数函数来把连乘变成求和来简化问题,因此公式七的对数似然函数为:
(8) L ( w ) = ∑ i = 1 n [ y i l n π ( x i ) + ( 1 − y i ) l n ( 1 − π ( x i ) ) ] = ∑ i = 1 n [ y i l n π ( x i ) − y i l n ( 1 − π ( x i ) ) + l n ( 1 − π ( x i ) ) ] = ∑ i = 1 n [ y i l n π ( x i ) 1 − π ( x i ) ( 注 : 这 就 是 对 数 几 率 值 ) + l n ( 1 − π ( x i ) ) ] = ∑ i = 1 n [ y i ( w ∗ x i ) + l n ( 1 1 + e x p ( ( w ⋅ x ) ) ) ] = ∑ i = 1 n [ y i ( w ∗ x i ) − l n ( 1 + e x p ( w ⋅ x 1 ) ) ] \begin{aligned} L(w) &= \sum_{i=1}^{n}[y_i ln \pi(x_i)+(1-y_i)ln(1-\pi(x_i))]\\ &=\sum_{i=1}^{n}[y_i ln \pi(x_i) - y_i ln(1-\pi(x_i)) + ln(1-\pi(x_i))] \\ &=\sum_{i=1}^{n}[y_iln\frac{\pi(x_i)}{1-\pi(x_i)}(注:这就是对数几率值)+ln(1-\pi(x_i))] \\ &=\sum_{i=1}^{n}[y_i(w*x_i)+ln(\frac{1}{1+exp((w\cdot x))})] \\ &=\sum_{i=1}^{n}[y_i(w*x_i)-ln(1+exp(w\cdot x_1))] \end{aligned} \tag{8} L(w)=i=1∑n[yilnπ(xi)+(1−yi)ln(1−π(xi))]=i=1∑n[yilnπ(xi)−yiln(1−π(xi))+ln(1−π(xi))]=i=1∑n[yiln1−π(xi)π(xi)(注:这就是对数几率值)+ln(1−π(xi))]=i=1∑n[yi(w∗xi)+ln(1+exp((w⋅x))1)]=i=1∑n[yi(w∗xi)−ln(1+exp(w⋅x1))](8)
通过梯度下降和拟牛顿法即可求的该函数,我们求 L ( w ) L(w) L(w)对 w w w的倒数:
(9) ∂ L ( w ) ∂ w = ∑ i = 1 n [ y i x i − ( 1 1 + e x p ( w ⋅ x 1 ) ∗ e x p ( w ⋅ x i ) ) ∗ x i ] = ∑ i = 1 n [ y i x i − π ( x i ) ∗ x i ] \begin{aligned} \frac{\partial L(w)}{\partial w}&=\sum_{i=1}^{n}[y_ix_i-(\frac{1}{1+exp(w\cdot x_1)}*exp(w \cdot x_i)) * x_i]\\ &=\sum_{i=1}^{n}[y_ix_i-\pi(x_i)*x_i] \end{aligned} \tag{9} ∂w∂L(w)=i=1∑n[yixi−(1+exp(w⋅x1)1∗exp(w⋅xi))∗xi]=i=1∑n[yixi−π(xi)∗xi](9)
通常我们在实际优化的时候,都是求取最小值,因此通常使用 − L ( w ) -L(w) −L(w)作为损失函数.
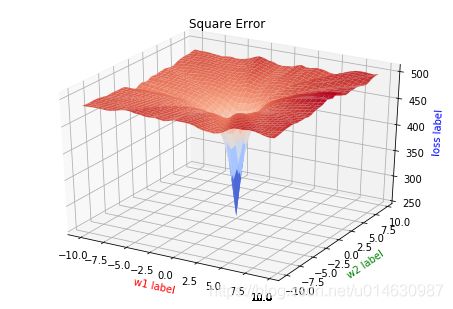
问题:在机器学习或深度学习中,我们通常以 L 2 L_2 L2作为损失函数,但是为什么这里是用了极大似然估计?
我们先观察一下使用 L 2 L_2 L2范数作为损失函数时,对 w w w的求导公式:
(10) L 2 ( w ) = 1 2 ∑ i = 1 n ( π ( x i ) − y i ) 2 ∂ l 2 ( w ) ∂ w = ∑ i = 1 n [ ( π ( x i ) − y i ) ∗ ∂ π ( x i ) ∂ z ∗ ∂ z ∂ w ] = ∑ i = 1 n [ ( π ( x i ) − y i ) π ( x i ) ( 1 − π ( x i ) ) x i ] \begin{aligned} L_2(w)&=\frac{1}{2}\sum_{i=1}^{n}(\pi(x_i) - y_i)^2 \\ \frac{\partial l_2(w)}{\partial w} &=\sum_{i=1}^{n}[(\pi(x_i) - y_i)*\frac{\partial\pi (x_i)}{\partial z} * \frac{\partial z}{\partial w}] \\ &=\sum_{i=1}^{n}[(\pi(x_i) - y_i)\pi(x_i) (1-\pi(x_i)) x_i] \end{aligned} \tag{10} L2(w)∂w∂l2(w)=21i=1∑n(π(xi)−yi)2=i=1∑n[(π(xi)−yi)∗∂z∂π(xi)∗∂w∂z]=i=1∑n[(π(xi)−yi)π(xi)(1−π(xi))xi](10)
其中, z = w ⋅ x z=w \cdot x z=w⋅x, 则 π ( x ) = e x p ( x ) 1 + e x p ( x ) \pi (x) = \frac{exp(x)}{1+exp(x)} π(x)=1+exp(x)exp(x),其导数为 π ′ ( x ) = π ( x ) ( 1 − π ( x ) ) \pi^{'} (x)=\pi(x)(1-\pi(x)) π′(x)=π(x)(1−π(x))
这里主要考虑的是优化问题,极大似然估计函数是一个凸函数,这是优化问题再最容易优化的模型,我们可以得到全局最优解,而对于 L 2 L_2 L2,由于Sigmoig函数导数的特性,当 π ( x ) \pi (x) π(x)接近0或者1时,此时的倒数就接近0,从而容易使函数陷入局部最优.
下图是两个损失函数以w为参数的简化图