springDataJPA的用法详解
第1章 概述
1.1 概述
Spring Data JPA 是Spring基于【JPA】和【ORM】之上封装的框架。针对JPA的高级封装。
操作数据库还是要使用ORM框架。
适配不同的ORM框架,在ORM框架切换时提供了极大的便利。
Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现,在实际的工作工程中,推荐使用 Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的 ORM 框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
1.2 特性
SpringData Jpa 极大简化了数据库访问层代码。 使用了 SpringDataJpa,我们的 dao 层中只需要写接口,就自动具有了增删改查、分页查询等方法
1.3 与 JPA 和hibernate 的关系
JPA 是一套规范,内部是有接口和抽象类组成的。hibernate 是一套成熟的 ORM 框架,而且 Hibernate 实现了 JPA 规范,所以也可以称 hibernate 为 JPA 的一种实现方式,我们使用 JPA 的 API 编程,意味着站在更高的角度上看待问题(面向接口编程)
Spring Data JPA 是 Spring 提供的一套对 JPA 操作更加高级的封装,是在 JPA 规范下的专门用来进行数据持久化的解决方案。
第2章 入门案例(CRUD)
2.1 需求说明
Spring Data JPA 完成客户的基本 CRUD 操作
2.2 搭建开发环境
2.2.1 引入依赖
使用 Spring Data JPA,需要整合 Spring 与 Spring Data JPA,并且需要提供 JPA 的服务提供者hibernate,所以需要导入 spring 相关坐标,hibernate 坐标,数据库驱动坐标等。
<dependencies>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
<!-- hibernate对JPA的实现 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.0.7.Final</version>
</dependency>
<!-- hibernate依赖的C3P0连接池 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>5.0.7.Final</version>
</dependency>
</dependencies>
</project>
2.2.2 配置文件 *
整合 Spring Data JPA 与 Spring
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<!-- 配置要扫描的包 -->
<context:component-scan base-package="com.itheima"></context:component-scan>
<!-- 1.dataSource -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver" />
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/day03" />
<property name="user" value="root" />
<property name="password" value="123456" />
</bean>
<!-- 2.EntityManagerFactory -->
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<!-- 注入数据源 -->
<property name="dataSource" ref="dataSource" />
<!-- 指定实体类所在的包 -->
<property name="packagesToScan" value="com.itheima.domain" />
<!-- 指定jpa的实现提供者 -->
<property name="persistenceProvider">
<bean class="org.hibernate.jpa.HibernatePersistenceProvider" />
</property>
<!--JPA供应商适配器 -->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<!-- 是否生成DDL语句 -->
<property name="generateDdl" value="true" />
<!-- 数据库厂商名称 -->
<property name="database" value="MYSQL" />
<!-- 数据库方言 -->
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect" />
<!-- 是否显示SQL -->
<property name="showSql" value="true" />
</bean>
</property>
<!--JPA方言 ORM的特性-->
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" />
</property>
</bean>
<!-- 3.事务管理器 -->
<!-- JPA事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- 整合spring data jpa -->
<jpa:repositories base-package="com.itheima.dao"
transaction-manager-ref="transactionManager"
entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
<!-- 4.txAdvice -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="get*" read-only="true" propagation="SUPPORTS" />
<tx:method name="find*" read-only="true" propagation="SUPPORTS" />
<tx:method name="*" propagation="REQUIRED" read-only="false" />
</tx:attributes>
</tx:advice>
<!-- 5.aop -->
<aop:config>
<aop:pointcut id="pointcut"
expression="execution(* com.itheima.service.*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut" />
</aop:config>
</beans>
2.2.3 实体类 *
所有的注解都是使用 JPA 的规范提供的注解,
所以在导入注解包的时候,一定要导入 javax.persistence 下的注解
@Entity //表明当前类是持久化类。
@Table(name="cst_customer") //建立实体类与表的映射关系
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)//主键生成策略
@Column(name="cust_id") //建立实体类中属性与表中字段的映射关系。如果属性名与列名一致,则此注解可以不写
private Long custId;
@Column(name="cust_name")
private String custName;
@Column(name="cust_source")
private String custSource;
@Column(name="cust_industry")
private String custIndustry;
@Column(name="cust_level")
private String custLevel;
@Column(name="cust_address")
private String custAddress;
@Column(name="cust_phone")
private String custPhone;
//配置一对多关联关系
//targetEntity:指定多的一方的类的字节码
//mappedBy:指定子表实体类中引用主表对象的名称
@OneToMany(targetEntity=LinkMan.class,mappedBy="customer")
private Set<LinkMan> linkMans = new HashSet<LinkMan>(0);
public Set<LinkMan> getLinkMans() {
return linkMans;
}
public void setLinkMans(Set<LinkMan> linkMans) {
this.linkMans = linkMans;
}
public Long getCustId() {
return custId;
}
public void setCustId(Long custId) {
this.custId = custId;
}
public String getCustName() {
return custName;
}
public void setCustName(String custName) {
this.custName = custName;
}
public String getCustSource() {
return custSource;
}
public void setCustSource(String custSource) {
this.custSource = custSource;
}
public String getCustIndustry() {
return custIndustry;
}
public void setCustIndustry(String custIndustry) {
this.custIndustry = custIndustry;
}
public String getCustLevel() {
return custLevel;
}
public void setCustLevel(String custLevel) {
this.custLevel = custLevel;
}
public String getCustAddress() {
return custAddress;
}
public void setCustAddress(String custAddress) {
this.custAddress = custAddress;
}
public String getCustPhone() {
return custPhone;
}
public void setCustPhone(String custPhone) {
this.custPhone = custPhone;
}
}
第3章 原理
通过继承JpaRepository接口来的,最终是来自CrudRepository接口
真正的实现类 SimpleJpaRepository
框架使用动态代理,Service层在运行时实际上调用的是代理出来的SimpleJpaRepository的方法。使用的JDK动态代理。
SpringDataJPA 只是对标准 JPA 操作进行了进一步封装,简化了 Dao 层代码的开发。
第4章 SpringDataJPA 查询(Dao层)
4.1 接口查询
在继承 JpaRepository和 JpaRepository 接口后,我们就可以使用接口中定义的方法进行查询
4.1.1 继承JpaRepository
JpaRepository 封装CRUD操作 <持久化类型,主键类型>

4.1.2 JpaSpecificationExecutor * * *
继承JpaSpecificationExecutor
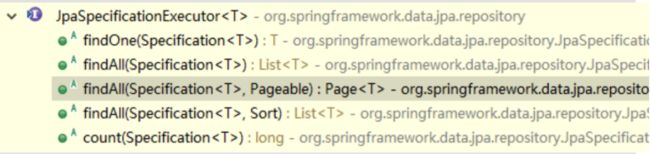
复杂查询的用法:
1、dao层继承JpaSpecificationExecutor
2、Service层用法:
/**
* 多条件查询+分页
*/
public Page findPage(Map map, int page, int size) {
Specification spec = createSpecification(map);
Pageable pageable = PageRequest.of(page - 1, size);
return labelDao.findAll(spec, pageable);
}
//多条件生成
private Specification createSpecification(Map map) {
Specification spec = new Specification() {
@Override
//root:代表任何实体类。
//cq:用于生成 sql语句的
//cb:提供了多条件查询的API方法
public Predicate toPredicate(Root root, CriteriaQuery cq, CriteriaBuilder cb) {
List list = new ArrayList<>();
if (map.get("labelname") != null && !"".equals(map.get("labelname"))) {
Predicate p1 = cb.like(root.get("labelname"), "%" + map.get("labelname") + "%"); // "labelname" like labelname
list.add(p1);
}
if (map.get("state") != null && !"".equals(map.get("state"))) {
Predicate p2 = cb.equal(root.get("state"), map.get("state"));
list.add(p2);
}
if (map.get("recommend") != null && !"".equals(map.get("recommend"))) {
Predicate p3 = cb.equal(root.get("recommend"), map.get("recommend"));
list.add(p3);
}
return cb.and(list.toArray(new Predicate[list.size()]));
}
};
return spec;
}
4.2 JPQL查询 **
对于某些业务来说,我们还需要灵活的构造查询条件,这时就可以使用
@Query 注解,结合 JPQL 的语句方式完成查询。
@Query 注解的使用非常简单,只需在方法上面标注该注解,同时提供一个 JPQL 查询语句即可
//JpaRepository 封装CRUD操作
//JpaSpecificationExecutor 封装高级操作,动态查询
public interface CustomerDao extends JpaRepository,JpaSpecificationExecutor{
//简单的crud不需要写代码
//JPQL:?1 代表参数的占位符,其中 1 对应方法中的参数索引
@Query("from Customer where custName like ?2 and custId =?1")
List findAllCustomerByJPQL(Long id ,String custName);
}
此外,也可以通过使用 @Query 来执行一个“更新”操作,为此,我们需要在使用 @Query 的同时,用@Modifying 来将该操作标识为修改查询,这样框架最终会生成一个更新的操作,而非查询:
@Query(value="update Customer set custName = ?1 where custId = ?2")
@Modifying
public void updateCustomer(String custName,Long custId);
4.3 SQL查询 *
Spring Data JPA 同样也支持 sql 语句的查询,如下:
//JpaRepository 封装CRUD操作
//JpaSpecificationExecutor 封装高级操作,动态查询
public interface CustomerDao extends JpaRepository,JpaSpecificationExecutor{
//简单的crud不需要写代码
/**
* nativeQuery : 使用本地 sql 的方式查询
*/
@Query(value = "select * from cst_customer where cust_name like ?2 and cust_id=?1",nativeQuery = true)
List findAllCustomerBySQL(Long id ,String custName);
}
4.4 方法命名查询 ***
顾名思义,方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照 Spring Data JPA 提供的方法命名规则定义方法的名称,就可以完成查询工作。Spring Data JPA 在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询
按照 Spring Data JPA 定义的规则,查询方法以 findBy 开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
//方法命名方式查询(根据客户名称查询客户)
//JpaRepository 封装CRUD操作
//JpaSpecificationExecutor 封装高级操作,动态查询
public interface CustomerDao extends JpaRepository<Customer,Long>,JpaSpecificationExecutor<Customer>{
//简单的crud不需要写代码
//from Customer where custName like ?2 and custId =?1
List<Customer> findByCustNameLikeAndCustId (String custName,Long custId);
}
具体的关键字,使用方法和生产成 SQL 如下表所示
关键字、方法、示例:
1、And
findByLastnameAndFirstname
… where x.lastname = ?1 and x.firstname = ?2
2、Or
findByLastnameOrFirstname
… where x.lastname = ?1 or x.firstname = ?2
3、Is,Equals
findByFirstnameIs,findByFirstnameEquals
… where x.firstname = ?1
4、Between
findByStartDateBetween
… where x.startDate between ?1 and ?2
5、LessThan
findByAgeLessThan
… where x.age < ?1
6、LessThanEqual
findByAgeLessThanEqual
… where x.age ⇐ ?1
7、GreaterThan
findByAgeGreaterThan
… where x.age > ?1
8、GreaterThanEqual
findByAgeGreaterThanEqual
… where x.age >= ?1
9、After
findByStartDateAfter
… where x.startDate > ?1
10、Before
findByStartDateBefore
… where x.startDate < ?1
11、IsNull
findByAgeIsNull
… where x.age is null
12、IsNotNull,NotNull
findByAge(Is)NotNull
… where x.age not null
13、Like
findByFirstnameLike
… where x.firstname like ?1
14、NotLike
findByFirstnameNotLike
… where x.firstname not ike ?1 … where x.firstname
15、StartingWith
findByFirstnameStartingWith
like ?1 (parameter bound with appended %)… where x.firstname
16、EndingWith
findByFirstnameEndingWith
like ?1 (parameter bound with prepended %) … where x.firstname
17、Containing
findByFirstnameContaining
like ?1 (parameter bound wrapped in %)
18、OrderBy
findByAgeOrderByLastnameDesc
… where x.age = ?1 order by x.lastname desc
19、Not
findByLastnameNot
… where x.lastname <> ?1
20、In
findByAgeIn(Collection ages)
… where x.age in ?1
21、NotIn
findByAgeNotIn(Collection age)
… where x.age not in ?1
22、TRUE
findByActiveTrue()
… where x.active = true
23、FALSE
findByActiveFalse()
… where x.active = false
24、IgnoreCase
findByFirstnameIgnoreCase
… where UPPER(x.firstame) = UPPER(?1)
第5章 Specifications 动态查询(忽略)
有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在 SpringDataJPA 中可以通过 JpaSpecificationExecutor 接口查询。相比 JPQL,其优势是类型安全,更加的面向对象。
要在DAO继承工具接口 JpaSpecificationExecutor
5.1 条件查询
package com.itheima.test;
//整合测试框架和Spring框架
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = “classpath:applicationContext.xml”)
public class TestSpringDataJpa {
@Autowired
private CustomerService customerService;
@Test
public void testSpecifications(){
Specification spec = new Specification() {
//criteriaBuilder 生成where条件
//criteriaQuery 生成整条语句
//root 封装谁就代表,用在表达式中
//from Customer where custName like ?2 and custId =?1
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
//custName like ?
Predicate p1 = criteriaBuilder.like(root.get("custName").as(String.class), "%集团%");
//custId =?1
Predicate p2 = criteriaBuilder.equal(root.get("custId").as(Long.class), 1L);
//custName like ?2 and custId =?1
Predicate p3 = criteriaBuilder.and(p1, p2);
return p3;
}
};
List customerList = customerService.testQBC(spec);
for (Customer customer : customerList) {
System.out.println(customer.getCustName());
}
}
}
5.2 分页查询
package com.itheima.test;
//整合测试框架和Spring框架
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = “classpath:applicationContext.xml”)
public class TestSpringDataJpa {
@Autowired
private CustomerService customerService;
/分页+排序/
@Test
public void testSpecificationsPage(){
Specification spec = new Specification() {
//criteriaBuilder 生成where条件
//criteriaQuery 生成整条语句
//root 封装谁就代表,用在表达式中
//from Customer where custName like ?2 and custId =?1
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
//custName like ?
Predicate p1 = criteriaBuilder.like(root.get(“custName”).as(String.class), “%集团%”);
//custId =?1
Predicate p2 = criteriaBuilder.equal(root.get(“custId”).as(Long.class), 1L);
//custName like ?2 and custId =?1
Predicate p3 = criteriaBuilder.and(p1, p2);
return p3;
}
};
/**
*构造分页参数
*Pageable : 接口
*PageRequest 实现了 Pageable 接口,调用构造方法的形式构造
*第一个参数:页码(从 0 开始)
第二个参数:每页查询条数
/
//Pageable pageable = PageRequest.of(1,2); + 排序
Pageable pageable = PageRequest.of(0,2, Sort.by(Sort.Order.desc(“custId”)));
/
*分页查询,封装为 SpringDataJpa 内部的 pagebean
*此重载的 testQBCPage方法为分页方法需要两个参数
*第一个参数:查询条件 Specification
*第二个参数:分页参数
*/
List customerList = customerService.testQBCPage(spec,pageable);
for (Customer customer : customerList) {
System.out.println(customer.getCustId()+"----"+customer.getCustName());
}
}
}
对于 Spring Data JPA 中的分页查询,是其内部自动实现的封装过程,返回的是一个 Spring Data JPA提供的 pageBean 对象。其中的方法说明如下:
//获取总页数
int getTotalPages();
//获取总记录数
long getTotalElements();
//获取列表数据
List getContent();
@Override
public List testQBCPage(Specification spec, Pageable pageable) {
Page page = customerDao.findAll(spec, pageable);
return page.hasContent()?page.getContent():null;
}
5.3 多表查询
package com.itheima.test;
//整合测试框架和Spring框架
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = “classpath:applicationContext.xml”)
public class TestSpringDataJpa {
@Autowired
private CustomerService customerService;
@Test
@Transactional //延迟加载时为保证事务不关闭,所以要添加 @Transactional 的注解
public void testSpecificationsJoin(){
Specification spec = new Specification() {
//criteriaBuilder 生成where条件
//criteriaQuery 生成整条语句
//root 封装谁就代表,用在表达式中
//from Customer where custName like ?2 and custId =?1
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
//一个用户customer对应多个联系人linkMan
Join
Predicate p1 = criteriaBuilder.equal(root.get(“custId”).as(Long.class), 1L);
//多表查询的信息已经包含在root中
return p1;
}
};
List customerList = customerService.testQBC(spec);
Customer customer = customerList.get(0); //查询出含一个对象的数组,所以取索引为0的对象
System.out.println(customer.getCustId()+"----"+customer.getCustName());
//延迟加载时为保证事务不关闭,所以要添加 @Transactional 的注解。
Set linkMans = customer.getLinkMans();
for (LinkMan linkMan : linkMans) {
System.out.println(linkMan.getLkmId()+"—"+linkMan.getLkmName());
}
}
}
注意:
如果出现了no Session的报错,是延迟加载时,没有数据库链接导致。
解决方案:
1、关闭延迟加载, 将fetch设成eager
2、用spring 的OpenSessionInViewFilter
3、如果使用的是spring boot,则在配置文件application.properties添加spring.jpa.open-in-view=true
第一种方式不好,修改框架默认的配置,无法使用到延迟加载的特性,参考上一节课对象导航查询。
后两种方式只能用在Servlet容器下,当运行单元测试的时候是无法启用OpenSessionInViewFilter的。
这种情况下需要在单元测试方法@Transactional注解。