史上最全Lombok——看这篇就够了
Lombok
- 0 前言
- 1 使用Lombok前提
- 1.1 如何在 IDEA 中如何安装 Lombok:
- 1.2 引入pom依赖
- 1.3 已经添加依赖为什么还要安装idea的Lombok插件?
- 2 怎么使用Lombok?
- 3 注解详解
- 3.1 @Data
- 3.2 @Setter
- 3.3 @Getter
- 3.4 @Slf4j
- 3.5 @AllArgsConstructor
- 3.6 @NoArgsConstructor
- 3.7 @EqualsAndHashCode
- 3.8 @NonNull
- 3.9 @Cleanup
- 3.10 @ToString
- 3.11 @RequiredArgsConstructor
- 3.12 @Value
- 3.13 @SneakyThrows
- 3.14 @Synchronized
- 4 总结
- Lombok注解原理
- 5 扩展
- 自定义支持JSR269的注解
0 前言
lombok是一个编译级别的插件,它可以在项目编译的时候生成一些代码。在很多工具类的项目中都有这个功能。比如dagger。
通俗的说,lombok可以通过注解来标示生成getter settter等代码。我们自然可以通过编译器比如IDEA的Generate生成,为啥要用这个?
在项目开发阶段,一个class的属性是一直变化的,今天可能增加一个字段,明天可能删除一个字段。每次变化都需要修改对应的模板代码。另外,有的class的字段超级多,多到一眼看不完。如果加上模板代码,更难一眼看出来。更有甚者,由于字段太多,想要使用builder来创建。手动创建builder和字段和原来的类夹杂在一起,看起来真的难受。lombok的@Builder即可解决这个问题
1 使用Lombok前提
1.1 如何在 IDEA 中如何安装 Lombok:
安装
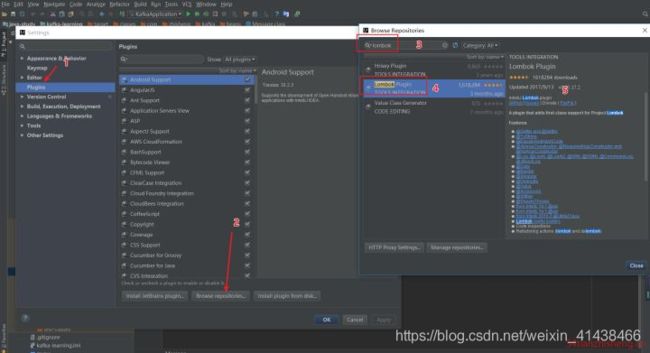
打开 IDEA 的 Settings 面板,并选择 Plugins 选项,然后点击 “Browse repositories”
在输入框输入”lombok”,得到搜索结果,点击安装,然后安装提示重启 IDEA,安装成功;
1.2 引入pom依赖
在自己的项目里添加 lombok 的编译支持,在 pom 文件里面添加 dependency
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.18</version>
<scope>provided</scope>
</dependency>
1.3 已经添加依赖为什么还要安装idea的Lombok插件?
现在有一个A类,其中有一些字段,没有创建它们的setter和getter方法,使用了lombok的@Data注解,另外有一个B类,它调用了A类实例的相应字段的setter和getter方法。
编译A类和B类所在的项目,并不会报错,因为最终生成的A类字节码文件中存在相应字段的setter和getter方法。
但是,IDE发现B类源代码中所使用的A类实例的setter和getter方法在A类源代码中找不到定义,IDE会认为这是错误。
要解决以上这个不是真正错误的错误,所以需要下载安装Intellij Idea中的"Lombok plugin"。
2 怎么使用Lombok?
在实体类上引入相关的注解就行:
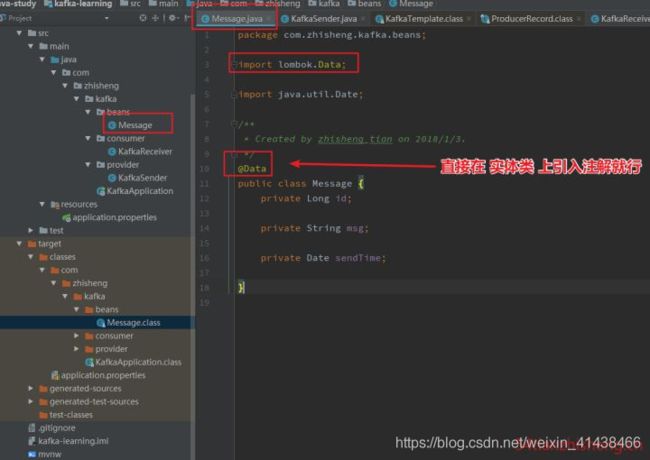
有哪些注解?
@Data
@Setter
@Getter
@Slf4j
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode
@NonNull
@Cleanup
@ToString
@RequiredArgsConstructor
@Value
@SneakyThrows
@Synchronized
3 注解详解
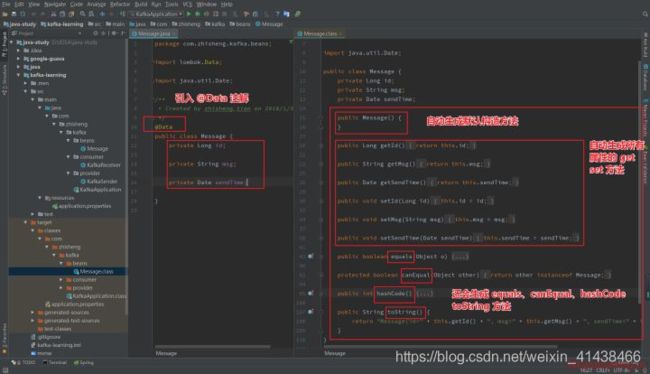
3.1 @Data
注解在 类 上;提供类所有属性的 get 和 set 方法,此外还提供了equals、canEqual、hashCode、toString 方法。
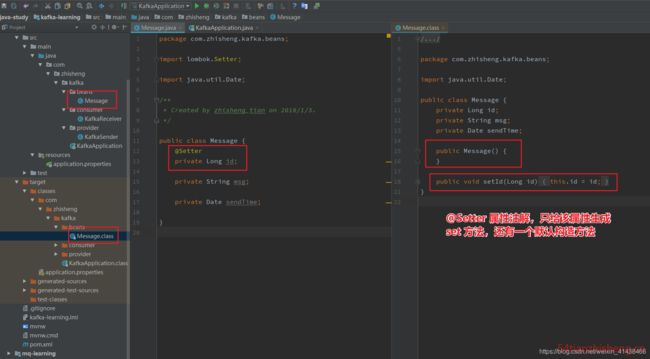
3.2 @Setter
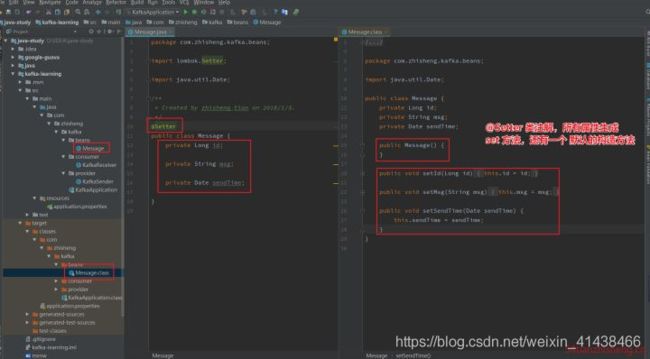
注解在 属性 上;为单个属性提供 set 方法;
注解在 类 上,为该类所有的属性提供 set 方法, 都提供默认构造方法。
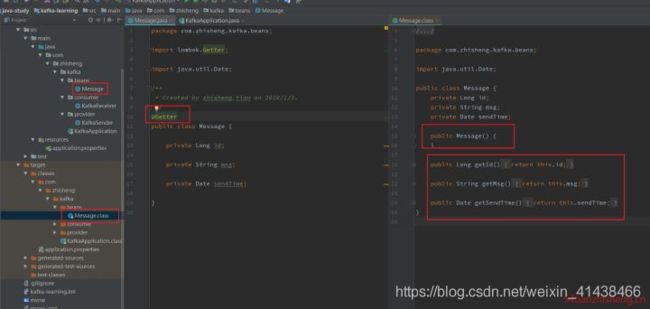
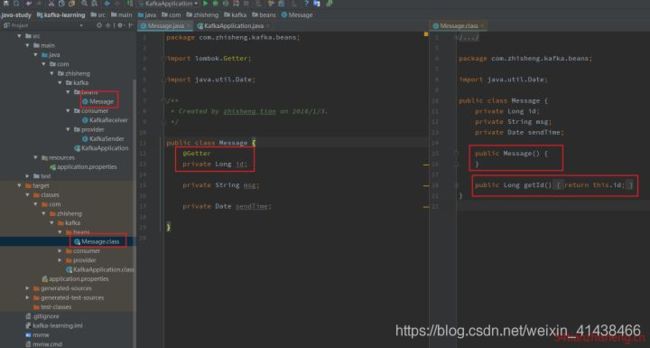
3.3 @Getter
注解在 属性 上;为单个属性提供 get 方法;
注解在 类 上,为该类所有的属性提供 get 方法,都提供默认构造方法。
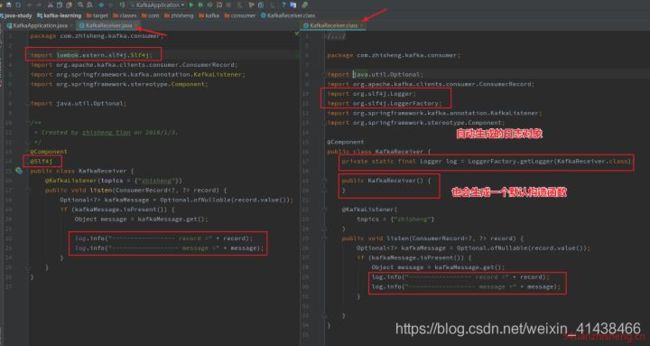
3.4 @Slf4j
注解在 类 上;为类提供一个 属性名为 log 的 slf4j 日志对象,提供默认构造方法。
3.5 @AllArgsConstructor
注解在 类 上;为类提供一个全参的构造方法,加了这个注解后,类中不提供默认构造方法了。
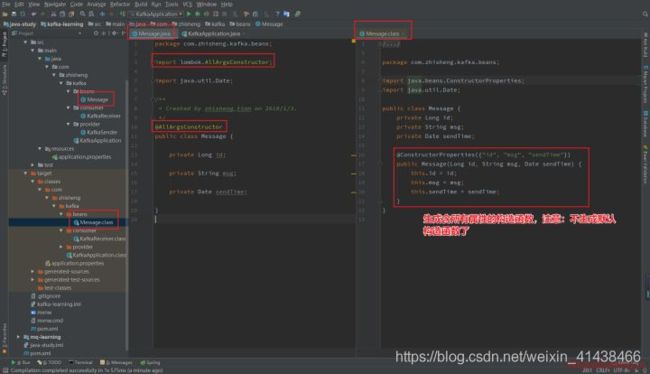
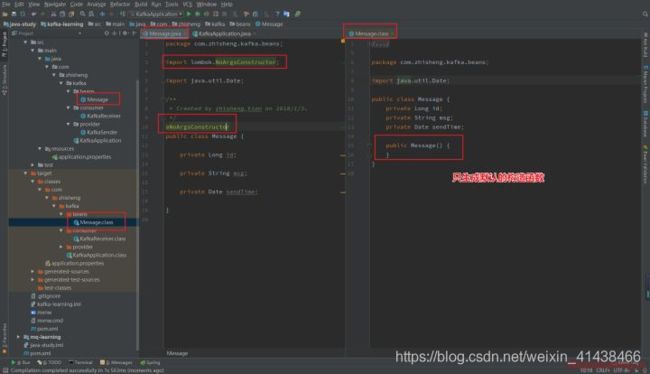
3.6 @NoArgsConstructor
注解在 类 上;为类提供一个无参的构造方法。
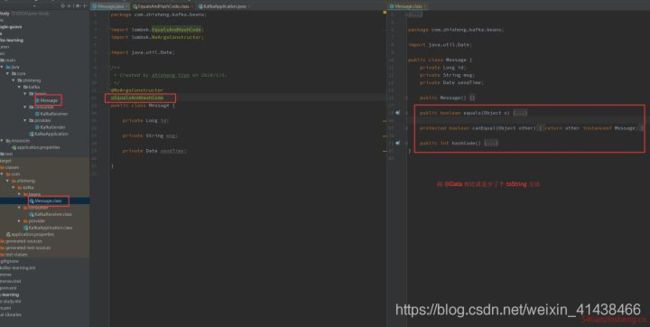
3.7 @EqualsAndHashCode
注解在 类 上, 可以生成 equals、canEqual、hashCode 方法。
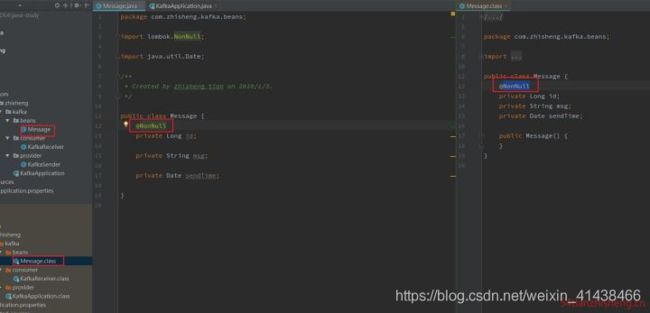
3.8 @NonNull
注解在 属性 上,会自动产生一个关于此参数的非空检查,如果参数为空,则抛出一个空指针异常,也会有一个默认的无参构造方法。
3.9 @Cleanup
这个注解用在 变量 前面,可以保证此变量代表的资源会被自动关闭,默认是调用资源的 close() 方法,如果该资源有其它关闭方法,可使用 @Cleanup(“methodName”) 来指定要调用的方法,也会生成默认的构造方法
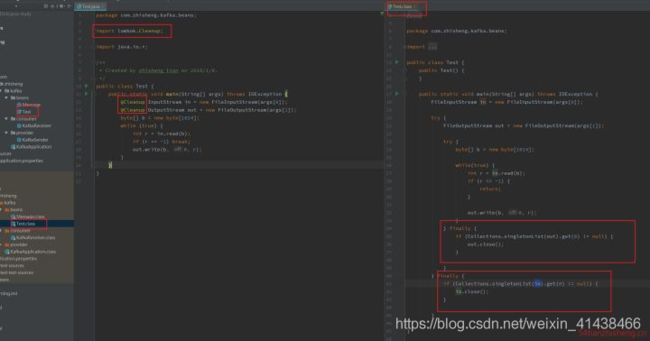
3.10 @ToString
这个注解用在 类 上,可以生成所有参数的 toString 方法,还会生成默认的构造方法。
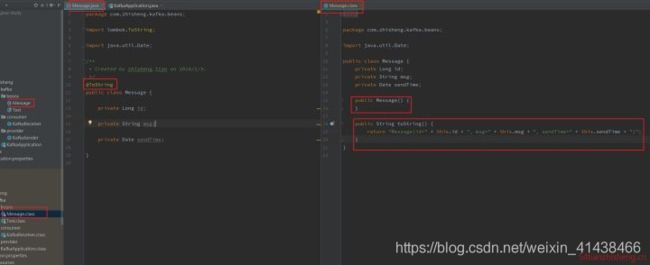
3.11 @RequiredArgsConstructor
这个注解用在 类 上,使用类中所有带有 @NonNull 注解的或者带有 final 修饰的成员变量生成对应的构造方法。

3.12 @Value
这个注解用在 类 上,会生成含所有参数的构造方法,get 方法,此外还提供了equals、hashCode、toString 方法。

3.13 @SneakyThrows
这个注解用在 方法 上,可以将方法中的代码用 try-catch 语句包裹起来,捕获异常并在 catch 中用 Lombok.sneakyThrow(e) 把异常抛出,可以使用 @SneakyThrows(Exception.class) 的形式指定抛出哪种异常,也会生成默认的构造方法。

3.14 @Synchronized
这个注解用在 类方法 或者 实例方法 上,效果和 synchronized 关键字相同,区别在于锁对象不同,对于类方法和实例方法:
- synchronized 关键字的锁对象分别是类的 class 对象和 this 对象,
- 而 @Synchronized 的锁对象分别是 私有静态 final 对象 lock 和 私有 final 对象 lock,当然,也可以自己指定锁对象,此外也提供默认的构造方法。
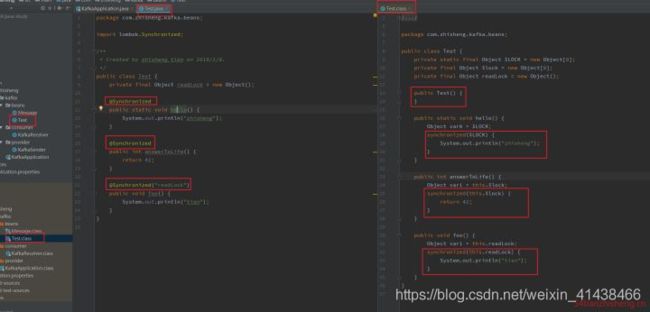
4 总结
以上注解可根据需要一起搭配使用!
虽说轮子好,但是我们不仅要知其然,也要知其所以然!
Lombok注解原理
说道 Lombok,我们就得去提到 JSR 269: Pluggable Annotation Processing API (www.jcp.org/en/jsr/deta…) 。JSR 269 之前我们也有注解这样的神器,可是我们比如想要做什么必须使用反射,反射的方法局限性较大。首先,它必须定义**@Retention为RetentionPolicy.RUNTIME**,只能在运行时通过反射来获取注解值,使得运行时代码效率降低。其次,如果想在编译阶段利用注解来进行一些检查,对用户的某些不合理代码给出错误报告,反射的使用方法就无能为力了。而 JSR 269 之后我们可以在 Javac的编译期利用注解做这些事情。所以我们发现核心的区分是在 运行期 还是 编译期。

从上图可知,Annotation Processing 是在解析和生成之间的一个步骤。具体详细步骤如下:
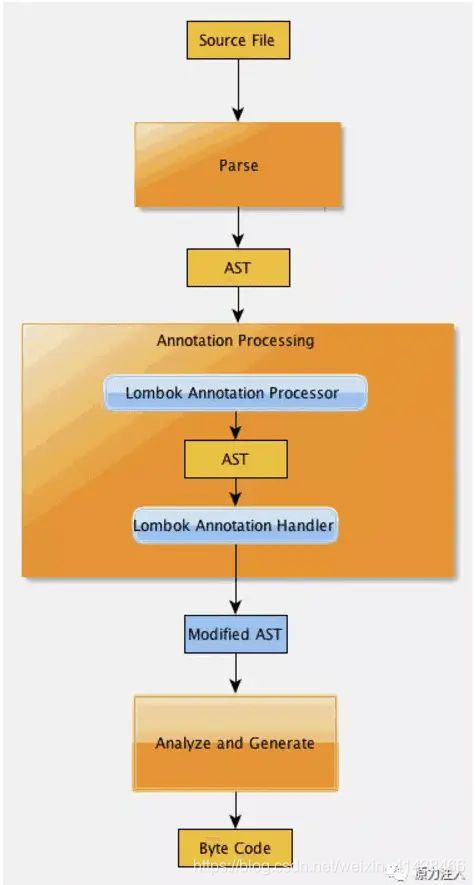
上图是 Lombok 处理流程,在Javac 解析成抽象语法树之后(AST), Lombok 根据自己的注解处理器,动态的修改 AST,增加新的节点(所谓代码),最终通过分析和生成字节码。
自从Java 6起,javac就支持“JSR 269 Pluggable Annotation Processing API”规范,只要程序实现了该API,就能在javac运行的时候得到调用。
5 扩展
自定义支持JSR269的注解
一般javac的编译过程,java文件首先通过进行解析构建出一个AST,然后执行注解处理,最后经过分析优化生成二进制的.class文件。我们能做到的是,在注解处理阶段进行一些相应处理。首先我们在META-INF.services下创建如下文件:
文件中指定我们的注解处理器:com.alipay.kris.other.lombok.MyAnnotaionProcessor,然后我们接可以编写自己的注解处理器,一个简单的实例代码如下:
@SupportedSourceVersion(SourceVersion.RELEASE_8)
@SupportedAnnotationTypes("com.alipay.kris.other.lombok.*")
public class MyAnnotaionProcessor extends AbstractProcessor {
public MyAnnotaionProcessor() {
super();
}
@Override
public boolean process(Set<? extends TypeElement> annotations,RoundEnvironment roundEnv) {
for (Element elem : roundEnv.getElementsAnnotatedWith(MyAnnotation.class)) {
MyAnnotation annotation = elem.getAnnotation(MyAnnotation.class);
String message = "annotation found in " + elem.getSimpleName()
+ " with " + annotation.value();
addToString(elem);
processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, message);
}
return true; // no further processing of this annotation type
}
}