Object Detection in 20 Years: A Survey目标监测20年综述解读(更新至P13,2.3.5)
Object Detection in 20 Years: A Survey
- 写在前面
- 引言
- 二、目标检测的二十年
- 2.1 目标检测的路径图
- 2.1.1 传统的目标检测器
- · Viola Jones Detector
- · HOG Detector
- · 可变部件模型 DPM
- 2.1.2 基于CNN的两阶段检测器
- · RCNN
- · SPPNet
- · Fast RCNN
- · Faster RCNN
- · FPN
- 2.1.3 基于CNN的单阶段检测器
- · YOLO
- · SSD
- · RetinaNet
- 2.2 目标检测的数据集和指标
- 2.3 目标检测的技术演进
- 2.3.1 早期的黑暗中摸索
- · 部件、形状、边缘
- · 早期的CNN
- 2.3.2 多尺度检测的演进
- · 特征金字塔+滑窗(-2014)
- · 目标提议框(2010-2015)
- · 深度回归,单阶段检测器(2013-2016)
- · 多尺度参考/多分辨率检测(2015-)
- 2.3.3 边界框回归的技术演进
- · Without BB regression (before 2018)
- · From BB to BB (2008-2013)
- · From features to BB (after 2013)
- 2.3.4 语义提取的技术演进
- · 局部语义
- · 全局语义
- · 语义交互
论文链接: https://arxiv.org/pdf/1905.05055v2.pdf
写在前面
这是一篇2019年5月的综述类论文,用39页的篇幅,调研了400篇论文,将目标检测20年的发展有广度有深度地进行整理和阐述。无论是对于初入门的不久想在目标检测任务上摸爬滚打的,还是已经是CV高玩,甚至是大佬,都可以从中得到收获。本文是我阅读论文时自己的整理记录,如有理解错误,请不吝指出,谢谢。
引言
目标检测是一个探究What objects are where的问题,是计算机视觉的基础任务之一,可以细分为通用目标检测和特定场景的目标检测。由于深度学习近几年的迅猛发展,目标检测也收益于此,得到了巨大的进步。
目标检测的综述论文也不只是这一篇,那么这一篇相对于其他综述类论文有什么区别呢?
- 时间跨度大。
- 深入剖析关键技术。
- 综合分析模型加速方法。
目标检测的困难与挑战,困难与挑战不同任务差异大:
- 计算机视觉的共同挑战:不同视角,光照,类内差异。
- 目标检测本身:目标旋转,尺度变换(小目标),目标准确定位,密集/遮挡目标检测,加速方法等。
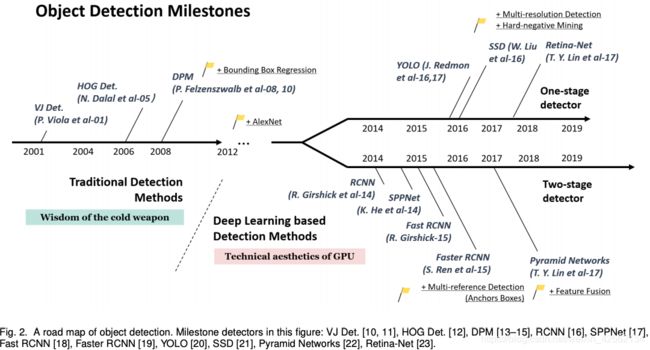
二、目标检测的二十年
过去的20年,以2014年为界,前为传统的目标检测阶段,后为基于深度学习的目标检测阶段。
2.1 目标检测的路径图
2.1.1 传统的目标检测器
· Viola Jones Detector
2001年,人脸检测,在700MHz奔腾3处理器上跑出实时性能。
基于滑窗:从图像所有可能的位置和尺度的图块中,寻找是否包含人脸。这个计算量是很大的,而VJ Detector提出了三种方法大大提升了检测速度:
- 图像整合(Integral image):提取HAAR特征,加速窗的过滤和卷积,使计算复杂度和窗尺寸无关。
- 特征选择(Feature selection):Adaboost算法选择特征集合中最有帮助的的小子集。
- 级联检测(Detection cascade):多阶段检测减少在背景滑窗上的检测时间。
· HOG Detector
方向梯度直方图(Histogram of Oriented Gradients, HOG)特征提取器在2005年提出,是一种尺度无关变换和形状语义方法的改进,对变换、大小、光章和其他非线性因素鲁棒,并且通过保持检测窗不变的基础上,缩放输入图像,来检测多尺度目标。
· 可变部件模型 DPM
DPM是VOC检测挑战07-09年三年的冠军,是当时的最好方法。
“divide and conquer”:训练被看成是一种目标合适分解方法的学习,测试是检测出的不同目标部件的集成。
一个经典的DPM由一个root-filter和许多part-filter组成,使用弱监督方法取代手动配置part-filters,并进而提出了Multi-Instance Learning,同时,现在非常流行的难例挖掘、边界框回归等也在当时提出。使用了一种“编译”检测器模型的方法达到了比级联更快的检测速度,且不损失精度。
2.1.2 基于CNN的两阶段检测器
2010-2012年,基于传统方法的目标检测进入瓶颈,而深度卷积神经网络给目标检测注入了新的动力。
· RCNN
RCNN的思想很简单:先用selective search抽取一系列目标的候选框,将每个候选框都缩放到固定尺寸送到ImageNet训练好的CNN模型中,抽取每个候选框对应的特征,最后使用线性SVM分类器来预测候选框中目标类别。
RCNN和传统方法相比取得了极大的进步,但是计算量太大,一张图会获得超过2000个候选框,并且每个候选框单独送入网络,导致整个模型非常慢,GPU上14s/image。
· SPPNet
2014年何恺明提出了Spatial Pyramid Pooling Networks,可以将不同候选框通过SPP layer产生固定尺寸的特征图,并且不需要缩放,这样每张图的所有候选框只要前向计算一次,避免了重复计算,使SPP比RCNN在不损失精度的前提下快了20倍。
同样,SPP仍然是多阶段的检测器,而且SPP只fine-tune全连接层而忽略之前的层。而这个问题在Fast RCNN得到了解决。
· Fast RCNN
RCNN的作者R. G在RCNN和SPP的基础上提出了Fast RCNN。Fast RCNN同时训练检测器和回归器,比RCNN快了200倍。
但是Fast RCNN的检测速度仍然受限于候选框的数量。
· Faster RCNN
2015年任少卿在微软研究院实习的时候,做出的一篇成果。Faster RCNN是第一个端到端的、近乎实时的深度学习检测器。其主要贡献是Region Proposal Network,RPN,使网络能够自己生成候选框。
尽管Faster RCNN突破了Fast RCNN的计算瓶颈,但是仍然有计算冗余。RFCN和Lighthead RCNN都对此作出了一些改进。
· FPN
2017年,Lin提出了Feature Pyramid Network, FPN,在Faster RCNN的基础上。在FPN之前,许多检测模型都只提取网络的最后一层特征图用于后续处理,尽管最后一层特征图有最丰富的语义信息,但是缺少位置信息。FPN从最高层特征图不断向上上采样融合,得到不同尺度的特征图。FPN的优点是多尺度的检测,并且直到如今也是主流的特征提取网络。
2.1.3 基于CNN的单阶段检测器
· YOLO
You Only Look Once, YOLO于2015年提出,是第一个单阶段的目标检测器。YOLO非常快,在较少精度损失的前提下甚至达到了155fps的速度。作者完全抛弃了“候选框+验证”的模式,而是采用了另一种方法:用单个神经网络处理整个图像。网络将图像分割成不同的region,并且同时预测边界框和对应的目标概率。并且在之后陆续提出了YOLO v2,v3,在保持高速度的前提下进一步提高了检测精度。
尽管YOLO速度很快,但是和两阶段的检测器相比,准确度仍然不足,尤其是对于小目标。后续的YOLO版本和SSD关注了这个问题。
· SSD
Single Shot MultiBox Detector, SSD是第二个单阶段的检测器。SSD的主要贡献是多尺度。
· RetinaNet
2017,RetinaNet提出,主要贡献是为解决训练样本不平衡而提出了focal loss,使单阶段的模型达到了双阶段模型的准确度。
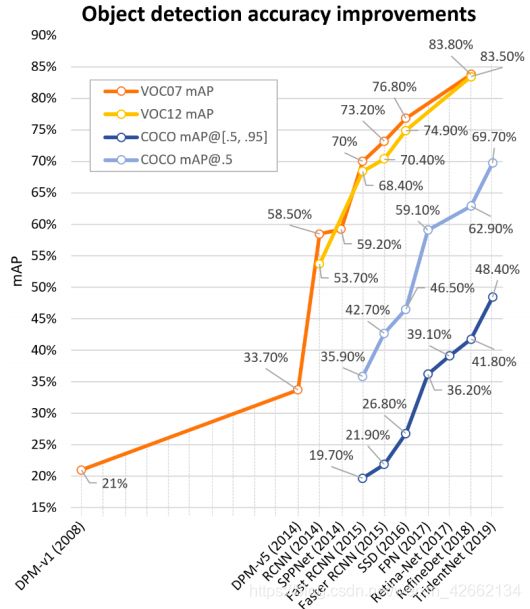
2.2 目标检测的数据集和指标
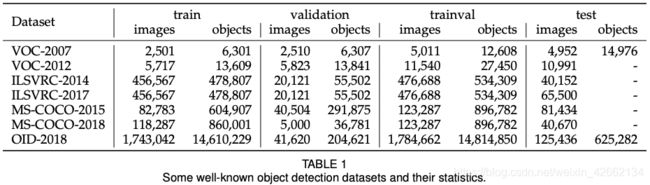
数据集:
- Pascal VOC
· 分类、检测、语义分割、行为检测
· #images = 11k,#annotations = 27k, #classes = 20
· 2005-2012,多用于ablation study,as test-bed - ILSVRC
· 检测
· #images = 517k,#annotations = 534k, #classes = 200
· 2010-2017,ImageNet - MS-COCO
· 检测、语义分割、实例分割、全景分割
· #images = 164k,#annotations = 897k, #classes = 80
· de facto standard,事实上的标准 - Open Images
· 检测、成对目标关联、分割
· #images = 1910k,#annotations = 15440k, #classes = 600
· 数据集大! - Others
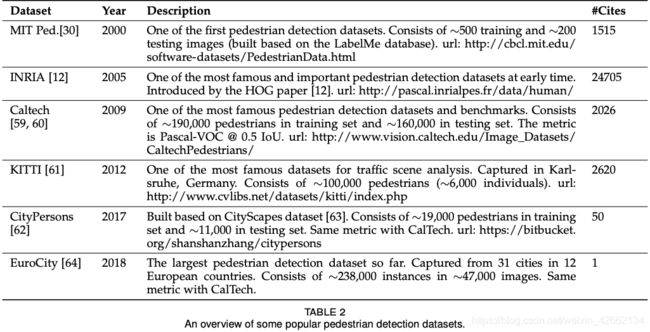
· 见表2-6
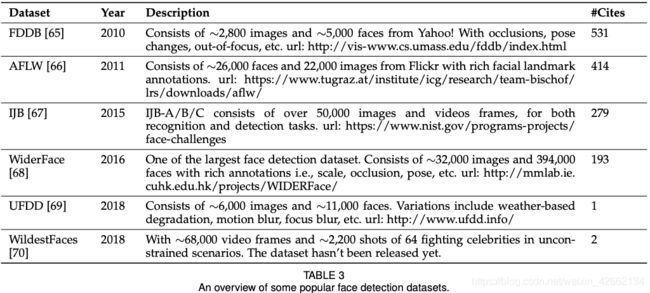
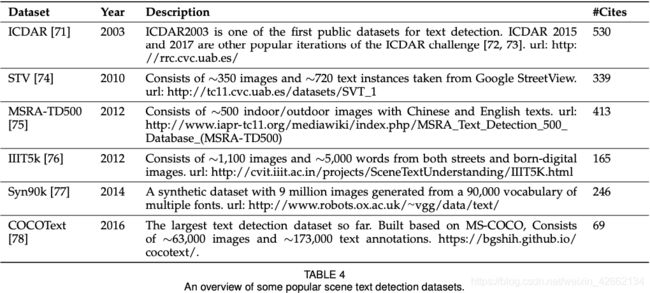
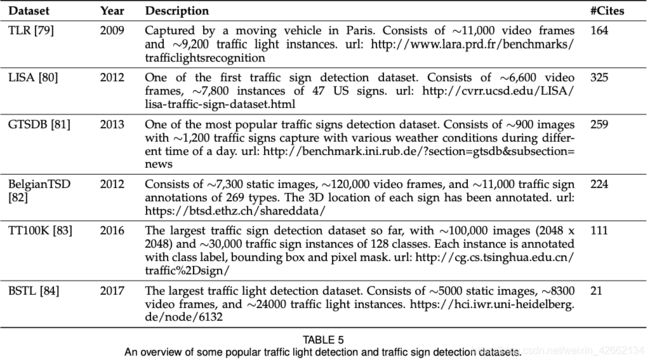
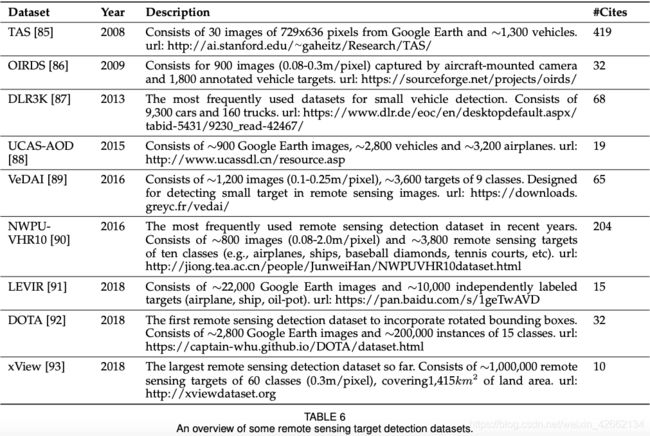
指标:
早期指标:
- FPPW:miss rate vs. false positives per-window,无法反映全图上的性能。
- FPPI:miss rate vs. false positives per-image,全图性能。
后来:
- AP:average precision,VOC2007提出,代表不同召回recall下的平均检测精度precision,用于多个类别的话,对每个类别进行平均,总体性能为mean AP,即mAP。使用交并比(Intersection over Union, IoU)判断是否召回,假设IoU_th=0.5,那么检测框和gt框IoU大于0.5的,即认为召回“successfully detected”,否则为漏检“missed”,以0.5为阈值的mAP(mAP0.5)多年来都作为目标检测领域的标准。
2014年后:
- AP0.5:0.05:0.95:随着MS-COCO数据集的流行,COCO将原IoU固定为0.5改为了从0.5到0.95,步长为0.05的一系列AP,阈值从小到大分别对应了粗糙定位和精确定位,也就是阈值越大难度越高,召回出的框也越接近ground truth。
最近:
- 虽然提出了一些如localization recall precision等的替代指标,但是VOC/COCO为代表的mAP仍然是使用最广泛的目标检测指标。
2.3 目标检测的技术演进
2.3.1 早期的黑暗中摸索
· 部件、形状、边缘
核心理念:“Recognition-by-components” —— Distance Transforms,Shape Contexts,Edgelet,etc. —— 复杂环境中效果不好。
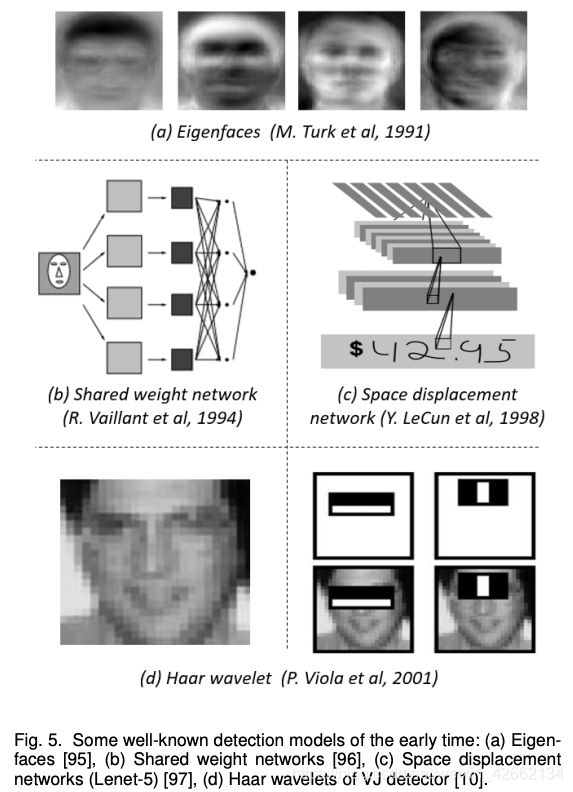
机器学习助阵。1998年之前:数据模型(Eigenfaces),1998-2005:小波表征(Haar),2005-2012:梯度表征。
· 早期的CNN
1990年Y. LeCun最早尝试用CNN做目标检测,但是受限于计算资源,CNN非常浅。但在当时,仍然提出了许多加速的方法(shared-weight replicated neural network,space displacement network)。当时的CNN网络可以看作是如今全卷积网络FCN的雏形。
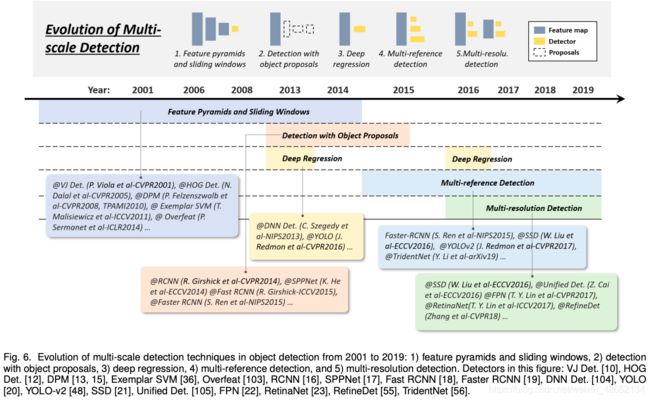
2.3.2 多尺度检测的演进
总体来说,多尺度检测经历了以下几个阶段:
- 2014以前:特征金字塔和滑窗
- 2010-2015:基于提议/候选框的检测
- 2013-2016:深度回归
- 2015以后:多尺度参考
- 2016以后:多分辨率检测
· 特征金字塔+滑窗(-2014)
VJ检测器需要大量计算,04-14年学者们提出了HOG、DPM、Overfeat等。
VJ和HOG用固定宽高比的滑窗检测目标,为了检测Pascal VOC中更复杂的目标,mixture model通过训练多个不同的模型来检测不同宽高比的目标。exemplar-based detection提供了一种基于范例的检测办法。
· 目标提议框(2010-2015)
随着MS-COCO这样具有挑战性的数据集的放出,人们开始希望有一种统一训练不同宽高比的多尺度方法。而提议框proposal则旨在解决这个问题。
提议框是类别无关的一组框,可以包含任何目标。它被第一次使用是在2010年,避免了滑窗方法带来的大量计算。
基于提议框的检测算法需要达到以下三个要求:
- 高召回率
- 高定位准确度
- 基于1、2,提升检测精度和速度
现代的提议框检测方法分成三大类:
- 分割聚类方法 segmentation grouping approaches
- 窗赋分方法 window scoring approaches
- 基于神经网络的方法 neural network approaches
从自底向上方法开始,慢慢演变为使用低层纹理、边缘特征,或人工提取的特征,提高定位准确度。2014年后,深度神经网络在检测任务上表现出色。
之后,学者们开始考虑,proposal的角色是什么?提高精度,还是速度?虽然做了一些弱化提议框的方法,但是效果都不尽如人意。
· 深度回归,单阶段检测器(2013-2016)
GPU算力的提升,人们开始使用更加直接粗暴的方式进行多尺度检测,于是就有了用深度神经网络直接回归出边界框的坐标的方法。这种方法的有点是简单且容易实现,但是定位不够准确。
· 多尺度参考/多分辨率检测(2015-)
多尺度参考Multi-reference的思想是在每个像素点上预定义一组不同尺寸和宽高比参考框(锚框anchor),接着基于anchor进行预测。
经典的损失函数为cross-entropy loss + L1/L2 loss,前者用于分类,后者用于回归,并且常有一个权重项平衡两者。若anchor box和gt box的交并比大于某一阈值,则将该anchor对应像素的回归损失回传,反之不回传。
另一种流行的方法是多分辨率检测,也就是通过在网络的不同特征层上检测不同尺度的目标,浅层检小目标,深层检大目标,如FPN、SSD等。
anchor和类FPN是当前最流行、最先进的检测思想。
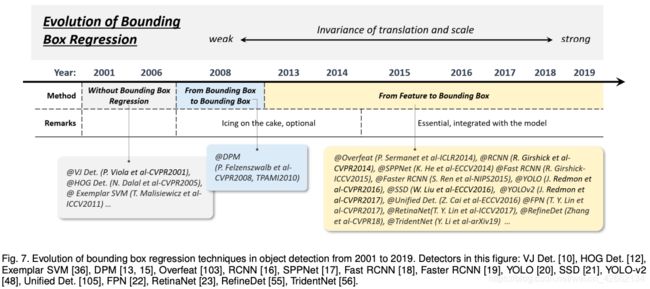
2.3.3 边界框回归的技术演进
2008年前:without BB regression
2008-2013:from BB to BB
2013-至今:from feature to BB
· Without BB regression (before 2018)
通常直接把滑窗作为检测结果,为了获得更精确的定位和尺寸,就需要设计非常密集的滑窗。典型方法:VJ检测器和HOG检测器。
· From BB to BB (2008-2013)
DPM是第一个采用边界框回归的方法。当时边界框回归是一种可以选择的后处理方法。
· From features to BB (after 2013)
2015年Faster RCNN将边界框的回归整合进了检测器中,并且实现了端到端。回归框直接通过卷积特征图得到,通常会使用smooth L1 Loss作为损失函数:
y = { 5 t 2 , ∣ t ∣ ≤ 0.1 ∣ t ∣ − 0.05 , else y= \begin{cases} 5t^2, & |t|\le0.1\\ |t|-0.05, & \text{else} \end{cases} y={5t2,∣t∣−0.05,∣t∣≤0.1else
也有学者用root-square函数:
L ( x , x ∗ ) = ( x − x ∗ ) 2 L(x,x^*)=(\sqrt{x}-\sqrt{x^*})^2 L(x,x∗)=(x−x∗)2
当然也有其他学者针对这个问题提出正则化坐标来获得更鲁棒结果的方法。
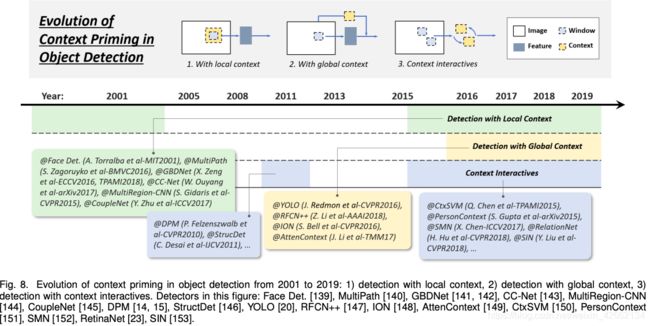
2.3.4 语义提取的技术演进
物体都是嵌入在周围环境中的,我们的大脑可以把物体和环境信息联系在一起,然后就能识别和理解物体。对于语义的提取,学界经历了三个阶段:
1)使用局部语义检测
2)使用全局语义检测
3)语义交互
· 局部语义
局部语义信息是指目标周围的有限区域的视觉信息,曾经把目标检测的能力提升了不少。21世纪早期,学者发现局部语义可以提升人脸检测的性能、可以提升行人检测的性能。最近的深度学习也从局部语义中获益,要么是通过增大感受野获得局部语义信息,要么是通过目标的提议框。
· 全局语义
全局语义可以挖掘额外的场景信息。早期的目标检测器的一种常用方法是将全局语义中的元素的统计信息整合进去,如Gist。现代的深度学习方法有两种手段:1)利用更大的感受野(甚至可以比原图大小还大),2)将全局的语义信息作为一种信息序列用于RNN中。
· 语义交互
语义交互指的是视觉元素的交互传达的部分信息,比如限制和依赖关系。对于大部分的检测器来说,目标是被分别检测的,没有考虑它们之间的关系。最近的研究将这种关系也考虑在内。可以分为两类:1)探索独立目标之间的关系,2)建模目标和环境之间的依赖关系。
to be continued…