Python文本特征提取 DictVectorizer CountVectorizer TfidfVectorizer 附代码详解
文章目录
- DictVectorizer 对使用字典储存的数据进行特征提取与向量化
- CountVectorizer / TfidfVectorizer 处理无特殊数据结构存储的数据
- 词袋模型(Bag of Words)
- CountVectorizer
- TfidfVectorizer
- CountVectorizer TfidfVectorizer 朴素贝叶斯分类实例
- 参考文献
文本特征提取:将文本数据转化成特征向量的过程。
python-sklearn库的模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。
【注】特征特征提取与特征选择有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到机器学习中。
DictVectorizer 对使用字典储存的数据进行特征提取与向量化
因为字典本身的key-value存储特点,这种情况实际上属于分类变量特征提取,scikit-learn的DictVectorizer类可以用来将Python字典(dict)对象列表的要素数组转换为 scikit-learn 估计器使用的 NumPy/SciPy 表示形式。
在下面的例子,”城市” 是一个类别属性,而 “温度” 是传统的数字特征。其中类别型特征无法直接数字化表示,通常用独热编码(One-of-K or One-Hot Encoding):借助原特征的名称,组合产生新的特征,并采用0/1二值方式进行量化;相比用单独的数值来表示分类,这种方法看起来很直观。而数值型特征,一般情况下只需要维持原始特征值即可。
# 从sklearn.feature_extraction 导入 DictVectorizer
from sklearn.feature_extraction import DictVectorizer
# 定义一组字典列表,用来表示多个数据样本(每个字典代表一个数据样本)。
measurements = [{'city': 'Dubai', 'temperature': 33.}, {'city': 'London', 'temperature': 12.}, {'city': 'San Fransisco', 'temperature': 18.}]
# 初始化DictVectorizer特征抽取器
vec = DictVectorizer()
# 输出转化之后的特征矩阵。
print (vec.fit_transform(measurements).toarray())
# 输出各个维度的特征含义。
print (vec.get_feature_names())
输出结果为
[[ 1. 0. 0. 33.]
[ 0. 1. 0. 12.]
[ 0. 0. 1. 18.]]
[‘city=Dubai’, ‘city=London’, ‘city=San Fransisco’, ‘temperature’]
这里的类别型变量city有三个值:Dubai, London,San Francisco;独热编码方式就是用三位二进制数,每一位表示一个城市。 【注】:编码的顺序不是由字典中城市排列的顺序决定,城市并没有自然数顺序,编码数值的大小并没有实际意义。例如,改变字典中的key-value顺序后,第一个city“London”的编码是[ 0. 1. 0.],用第二个元素为1表示,对应输出结果为
# 定义一组字典列表,用来表示多个数据样本(每个字典代表一个数据样本)。
measurements = [{'city': 'London', 'temperature': 12.}, {'city': 'Dubai', 'temperature': 33.}, {'city': 'San Fransisco', 'temperature': 18.}]
[[ 0. 1. 0. 12.]
[ 1. 0. 0. 33.]
[ 0. 0. 1. 18.]]
[‘city=Dubai’, ‘city=London’, ‘city=San Fransisco’, ‘temperature’]
CountVectorizer / TfidfVectorizer 处理无特殊数据结构存储的数据
对于没有使用特殊数据结构进行存储的文本数据,如一系列的字符串、一篇文档,常用的文本特征表示方法为词袋模型。
-
词袋模型(Bag of Words)
词袋模型不考虑文本中词汇出现的顺序和上下文关系,仅仅考虑词的权重(在文本中出现的频率)。【注】词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。
一批文本的集合称为文集(corpus),词袋模型首先会进行分词,把训练文本(文集)中的每个出现过的词汇单独视作一列特征,这些不重复的词汇就组成了词表(Vocabulary)。然后统计每个词在每条训练文本中出现的次数,将词与对应的词频放在一起,就是我们常说的向量化,最终每条训练文本的内容都会映射为词表的一个特征向量。
在词袋模型统计词频的时候,可以使用 sklearn 的如下两种方法:
- CountVectorizer
只考虑每个词汇(Term)在该条训练文本中出现的频率(Term Frequency)
- TfidfVectorizer
除了考量某一词汇在当前文本中出现的频率 TF(Term Frequency)之外,同时关注包含这个词汇的所有文本条数的倒数,即逆文本频率指数 IDF(Inverse Document Frequency),这样可以削减一些高频大众词汇对分类决策的干扰(它们对文本特点刻画的贡献很小)。文本条目越多,Tfid的优势越显著。
下面使用简单的文集和CountVectorizer方法来演示词袋模型

该文集由两个文本组成,词表(vocabulary)共含有8个词:UNC, played, Duke, in, basketball, lost, the, game,用字典(dictionary)的形式来表示特征(词)与特征索引的对应关系。 词袋模型用文集词表中 词的特征向量来表示每个文本,所以在本例中每个文本对应着一个8维的特征向量。【注】构成特征向量的元素数量称为维度(dimension)
在大多数词袋模型中,特征向量的每一个元素是用二进制数表示单词是否在文本中,有点类似于独热编码。例如,词汇表第一个单词(索引为0)是basketball,第一个文本和第二个文本中均出现了basketball,因此第一个特征向量和第二个特征向量的第一个元素均为1,即词频矩阵的第一列为[1;1]。而词汇表的最后一个词(索引为7)是unc,只在第一个文本中出现过,那么第一个特征向量和第二个特征向量的最后一个元素就分别为1和0,即词频矩阵的最后一列为[1;0]。
再增加一个文本到文集里

通过CountVectorizer类可以得出上图中的结果。词汇表总共有10个单词,a不在词汇表里,因为a的长度不符合CountVectorizer 类的默认要求。词汇表第一个词(索引为0)是ate,只在第三个文本中出现过,因此第一个特征向量为[0;0;1],以此类推。
【注】对比可知,相比第三个文本,前两个文本之间更为相似。两个语义最相似的文本其特征向量在空间中也是最接近的,scikit-learn里面的euclidean_distances函数可以计算特征向量间的欧式距离。
-
CountVectorizer
由前例可知,CountVectorizer 类会将文本中的词语转换为词频矩阵,矩阵中的元素a[i][j] 表示索引为 j 的词在第 i 个文本下的词频。CountVectorizer 类常用的数据输入形式为列表,列表元素为字符串,一个字符串代表一篇文本,字符串是已经分割好的,同样适用于中文。
总的来说,CountVectorizer有三个处理步骤:preprocessing、tokenizing、n-grams generation;它包含的参数非常多,一般需要设置的参数是:ngram_range,max_df,min_df,max_features等。常用函数 fit_transform 学习词表然后返回词频矩阵,get_feature_names()可获取词袋中所有的特征关键字,fit仅学习原始文档的词汇表但不返回,可结合 transform()或者 toarray()得到词频矩阵。
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
# “dog cat fish” 为输入列表的第0个(字符串)元素,该字符串代表了第一个文本
cv = CountVectorizer()
#创建词袋模型
cv_fit=cv.fit_transform(texts)
#上述代码等价于下面两行
#cv.fit(texts)
#cv_fit=cv.transform(texts)
print(cv.get_feature_names())
# Outputs:
#['bird', 'cat', 'dog', 'fish']
#文集的词特征,以列表形式呈现
print(cv.vocabulary_)
# Outputs:
# {‘dog’:2,'cat':1,'fish':3,'bird':0}
# 文集的词汇表,以字典形式呈现
# 其中,key:词表中的词,value:特征索引
# sklearn官方解释如下 .vocabulary_ : dict; A mapping of terms to feature indices.
print(cv_fit)
# Outputs:
#(0,1)1 第0个列表元素(代表第一个文本),词典中索引为1的特征词‘cat’,词频
#(0,2)1
#(0,3)1
#(1,1)2
#(1,2)1
#(2,0)1 第2个列表元素(代表第三个文本),词典中索引为0的特征词‘bird’,词频
#(2,3)1
#(3,0)1
print(cv_fit.toarray())
# Outputs:
#[[0 1 1 1]
# [0 2 1 0]
# [1 0 0 1]
# [1 0 0 0]]
#.toarray() 是将文本在词表上的映射结果转化为稀疏矩阵的形式
print(cv_fit.toarray().sum(axis=0))
# Outputs:
#[2 3 2 2]
#每个特征(词)在所有文档中的总词频
【参数】

【属性】

【方法】

【停用词过滤】
如果我们用新闻报道内容做文集,词汇表就可以用成千上万个单词。每篇新闻的特征向量都会有成千上万个元素,很多元素都会是0。体育新闻不会包含财经新闻的术语,同样文化新闻也不会包含财经新闻的术语。有许多零元素的高维特征向量成为稀疏向量(sparse vectors)。
用高维数据可以量化机器学习任务时会有一些问题,不只是出现在自然语言处理领域。第一个问题就是高维向量需要占用更大内存。NumPy提供了一些数据类型只显示稀疏向量的非零元素,可以有效处理这个问题。第二个问题就是著名的维度灾难(curse of dimensionality,Hughes effect),维度越多就要求更大的训练集数据保证模型能够充分学习。如果训练样本不够,那么算法就可以拟合过度导致归纳失败。
特征向量降维的一个基本方法是单词全部转换成小写。这是因为单词的大小写一般不会影响意思。而首字母大写的单词一般只是在句子的开头,而词库模型并不在乎单词的位置和语法。
另一种方法是去掉文集的停用词(Stop-word),像a,an,the,助动词do,be,will,介词on,around,beneath等。停用词通常是构建文档意思的功能词汇,其字面意义并不体现。CountVectorizer类可以通过设置stop_words参数过滤停用词,默认是英语常用的停用词。
-
TfidfVectorizer
一般来说,一个文本中某个词多次出现,相比只出现过一次的单词更能体现反映文本的意思,但有些词虽然在两个文本中出现的频率一样,但是两个文本的长度差别很大,一个文档比另一个文档长很多倍,这就需要特征向量归一化来实现不同文本向量的可比性。scikit-learn的TfdfTransformer类可以解决这个问题,默认情况下,TfdfTransformer类用L2范数对特征向量进行归一化:

f(t,d)是第d个文档(document)第t个单词(term)的频率, 是频率向量的L2范数。另外,还有对数词频调整方法(logarithmically scaled term frequencies),把词频调整到一个更小的范围,或者词频放大法(augmented term frequencies),适用于消除较长文档的差异。对数词频公式如下:
![]()
TfdfTransformer类计算对数词频调整时,需要将参数sublinear_tf设置为True。词频放大公式如下:
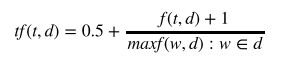
归一化,对数调整词频和词频放大都可以消除文档不同大小对词频的影响。然而,仍然存在另一个问题:特征向量里高频词的权重更大,但有些词在文集内其他文本里也经常出现,这些词并不能突出单个文本的特点,就可以被看成是该文集的停用词。比如,一个文集里大多数文本都是关于杜克大学篮球队的,那么高频词就是basketball,Coach K,flop,它们对于区分文本几乎没有任何作用。逆向文件频率(inverse document frequency,IDF)可用来度量文集中的词频率。
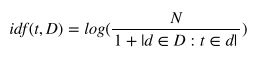
其中, 是文集中文本数量,表示包含单词 的文本数量。单词的TF-IDF值就是其频率与逆向文件频率的乘积。
TfdfTransformer类默认返回TF-IDF值,其参数use_idf默认为True。由于TF-IDF加权特征向量经常用来表示文本,所以scikit-learn提供了TfidfVectorizer类将CountVectorizer和TfdfTransformer类封装在一起。
-
CountVectorizer TfidfVectorizer 朴素贝叶斯分类实例
# 从sklearn.datasets里导入20类新闻文本数据抓取器。
from sklearn.datasets import fetch_20newsgroups
# 从互联网上即时下载新闻样本,subset='all'参数代表下载全部近2万条文本存储在变量news中。
news = fetch_20newsgroups(subset='all')
# 从sklearn.cross_validation导入train_test_split模块用于分割数据集。
from sklearn.cross_validation import train_test_split
# 对news中的数据data进行分割,25%的文本用作测试集;75%作为训练集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
# 可看作 X_train, X_test, y_train, y_test = train_test_split(x_文本, y_对应标签, test_size=0.25,)
# 从sklearn.feature_extraction.text里导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 采用默认的配置对CountVectorizer进行初始化(默认配置不去除英文停用词),并且赋值给变量count_vec。
count_vec = CountVectorizer()
# 只使用词频统计的方式将原始训练和测试文本转化为特征向量。
X_count_train = count_vec.fit_transform(X_train)
X_count_test = count_vec.transform(X_test)
# 从sklearn.naive_bayes里导入朴素贝叶斯分类器。
from sklearn.naive_bayes import MultinomialNB
# 使用默认的配置对分类器进行初始化。
mnb_count = MultinomialNB()
# 使用朴素贝叶斯分类器,对CountVectorizer(不去除停用词)后的训练样本进行参数学习。
mnb_count.fit(X_count_train, y_train)
# 输出模型准确性结果。
print 'The accuracy of classifying 20newsgroups using Naive Bayes (CountVectorizer without filtering stopwords):', mnb_count.score(X_count_test, y_test)
# 将分类预测的结果存储在变量y_count_predict中。
y_count_predict = mnb_count.predict(X_count_test)
# 从sklearn.metrics 导入 classification_report。
from sklearn.metrics import classification_report
# 输出更加详细的其他评价分类性能的指标。
print classification_report(y_test, y_count_predict, target_names = news.target_names)

# 从sklearn.feature_extraction.text里导入TfidfVectorizer。
from sklearn.feature_extraction.text import TfidfVectorizer
# 采用默认的配置对TfidfVectorizer进行初始化(默认配置不去除英文停用词),并且赋值给变量tfidf_vec。
tfidf_vec = TfidfVectorizer()
# 使用tfidf的方式,将原始训练和测试文本转化为特征向量。
X_tfidf_train = tfidf_vec.fit_transform(X_train)
X_tfidf_test = tfidf_vec.transform(X_test)
# 依然使用默认配置的朴素贝叶斯分类器,在相同的训练和测试数据上,对新的特征量化方式进行性能评估。
mnb_tfidf = MultinomialNB()
mnb_tfidf.fit(X_tfidf_train, y_train)
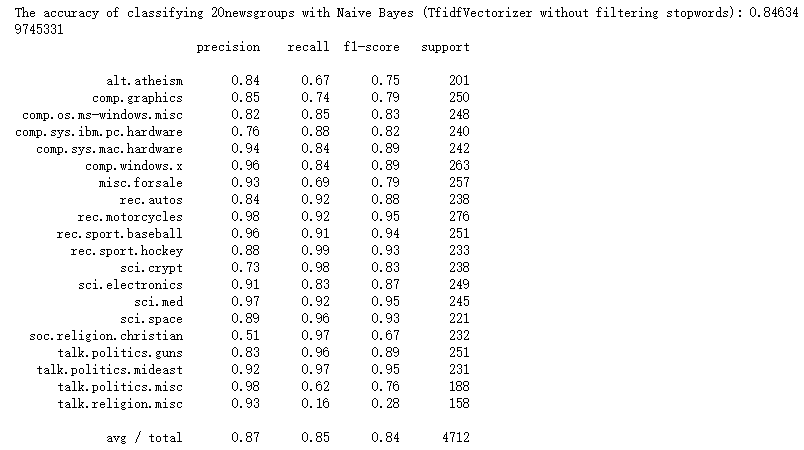
print 'The accuracy of classifying 20newsgroups with Naive Bayes (TfidfVectorizer without filtering stopwords):', mnb_tfidf.score(X_tfidf_test, y_test)
y_tfidf_predict = mnb_tfidf.predict(X_tfidf_test)
print classification_report(y_test, y_tfidf_predict, target_names = news.target_names)
# 继续沿用代码56与代码57中导入的工具包(在同一份源代码中,或者不关闭解释器环境),分别使用停用词过滤配置初始化CountVectorizer与TfidfVectorizer。
count_filter_vec, tfidf_filter_vec = CountVectorizer(analyzer='word', stop_words='english'), TfidfVectorizer(analyzer='word', stop_words='english')
# 使用带有停用词过滤的CountVectorizer对训练和测试文本分别进行量化处理。
X_count_filter_train = count_filter_vec.fit_transform(X_train)
X_count_filter_test = count_filter_vec.transform(X_test)
# 使用带有停用词过滤的TfidfVectorizer对训练和测试文本分别进行量化处理。
X_tfidf_filter_train = tfidf_filter_vec.fit_transform(X_train)
X_tfidf_filter_test = tfidf_filter_vec.transform(X_test)
# 初始化默认配置的朴素贝叶斯分类器,并对CountVectorizer后的数据进行预测与准确性评估。
mnb_count_filter = MultinomialNB()
mnb_count_filter.fit(X_count_filter_train, y_train)
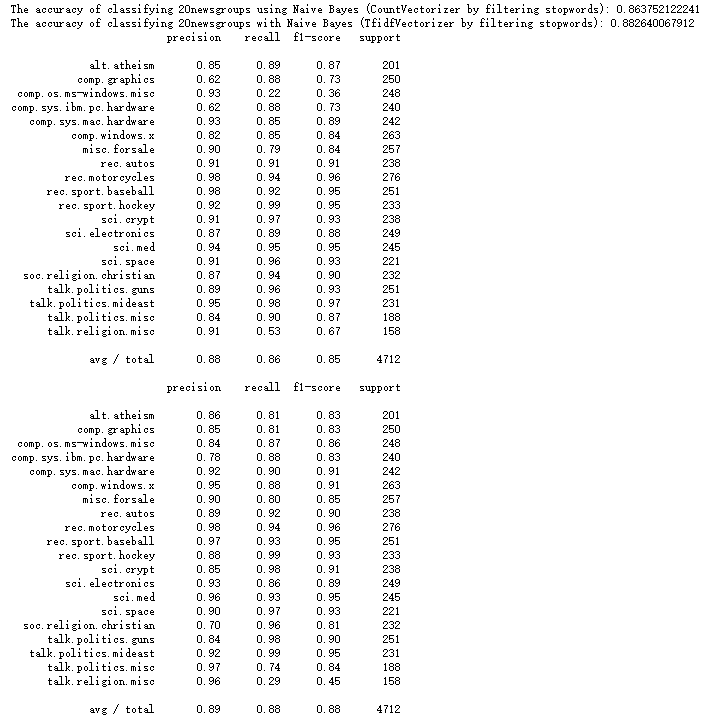
print 'The accuracy of classifying 20newsgroups using Naive Bayes (CountVectorizer by filtering stopwords):', mnb_count_filter.score(X_count_filter_test, y_test)
y_count_filter_predict = mnb_count_filter.predict(X_count_filter_test)
# 初始化另一个默认配置的朴素贝叶斯分类器,并对TfidfVectorizer后的数据进行预测与准确性评估。
mnb_tfidf_filter = MultinomialNB()
mnb_tfidf_filter.fit(X_tfidf_filter_train, y_train)
print 'The accuracy of classifying 20newsgroups with Naive Bayes (TfidfVectorizer by filtering stopwords):', mnb_tfidf_filter.score(X_tfidf_filter_test, y_test)
y_tfidf_filter_predict = mnb_tfidf_filter.predict(X_tfidf_filter_test)
# 对上述两个模型进行更加详细的性能评估。
from sklearn.metrics import classification_report
print classification_report(y_test, y_count_filter_predict, target_names = news.target_names)
print classification_report(y_test, y_tfidf_filter_predict, target_names = news.target_names)
参考文献
【1】官方文档 https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
【2】Python机器学习系列之特征提取与处理篇 http://www.10tiao.com/html/502/201607/2653283084/1.html
【3】python学习 文本特征提取系列 https://blog.csdn.net/m0_37788308/article/details/80933817
【4】sklearn——CountVectorizer详解 https://blog.csdn.net/weixin_38278334/article/details/82320307
【5】python 机器学习实战——从零开始通往Kaggle竞赛之路_Chapter_3.1.1.1.ipynb