行为克隆(End to End Learning for Self-Driving Cars 论文翻译)
摘要:我们训练了一个卷积神经网络(CNN)来将原始像素从一个向前倾斜的摄像头直接映射到转向指令。事实证明,这种端到端的方法非常强大。通过最少的人类训练数据,该系统学会了在有或没有车道标记的地方道路和高速公路上驾驶。它还在一些视觉引导不清晰的区域开展业务,比如停车场和未铺设的道路上。
该系统只以人的转向角作为训练信号,自动学习必要的过程步骤的内部表示,如检测有用的道路特征。我们从未明确地训练它去探测,例如,道路的分界线。
相对于车道标记、路径规划和控制等问题的显式分解,我们的端到端系统同时优化了所有处理步骤。我们认为这将最终导致更好的性能和更小的系统。更好的性能将产生,因为内部组件自我优化,以最大限度地提高整个系统的性能,而不是人工选择的中间标准,如车道检测。可以理解的是,选择这样的标准是为了便于人工解释,而不是自动地保证最大的系统性能。较小的网络是可能的,因为系统学会用最少的处理步骤来解决问题。
我们使用了NVIDIA DevBox和Torch 7进行培训,使用了NVIDIA DRIVE TM PX自动驾驶汽车计算机,也使用了Torch 7来决定去哪里驾驶。该系统以每秒30帧(FPS)的速度运行。
1介绍
CNNs[1]已经彻底改变了模式识别[2]。在CNNs被广泛采用之前,大多数模式识别任务都是使用手工制作的特征外向性的初始阶段和随后的分类器来完成的。CNNs的突破是通过训练实例自动学习特征。在图像识别任务中,CNN方法尤其强大,因为卷积运算可以捕获图像的二维性质。此外,通过使用卷积核扫描整个图像,相对于操作的总数,需要学习的参数相对较少。
虽然具有学习功能的CNNs已经在商业上使用了20多年的[3],但由于最近的两个发展,它们的采用在过去几年出现了爆炸性增长。首先,大型标记数据集,如大规模视觉识别挑战(ILSVRC)[4]已经成为培训和验证的有用工具。其次,CNN学习算法已经在大规模并行图形处理单元(gpu)上实现,极大地加速了学习和推理。
在本文中,我们描述了一个超越模式识别的CNN。它学习驾驶汽车所需的整个处理过程。这个项目的基础工作是在10多年前的一个国防高级研究计划局(DARPA)的幼苗项目中完成的,该项目被称为DARPA自动车辆(DAVE)[5],在这个项目中,一辆亚规模的无线电控制(RC)车行驶在一条垃圾填埋场的小路上。戴夫在类似但不完全相同的环境中接受了数小时的人类驾驶训练。训练数据包括来自两个摄像头的视频,以及来自人类操作员的左右转向指令。
在很多方面,DAVE-2的灵感来自于波默劳[6]的开创性工作,他在1989年在一个神经网络(ALVINN)系统中建立了自动陆地交通工具。它证明了末端训练的神经网络可以独立于方向盘和公共道路。25年的进步让我们可以在这项任务中运用更多的数据和计算能力。此外,我们在CNNs方面的经验使我们能够利用这一强大的技术。(ALVINN使用了一个全连通的网络,但以今天的标准来看,这个网络很小。)
虽然DAVE展示了端到端学习的潜力,并且确实被用来证明启动应用于地面机器人(LAGR)项目[7]的DARPA学习是合理的,但DAVE的表现还不够可靠,不足以提供一个完整的替代更模块化的越野驾驶方法。DAVE表示,在复杂环境下,两次碰撞的平均距离约为20米。
9个月前,英伟达(NVIDIA)启动了一项新计划,试图在DAVE的基础上建立一个强大的公共道路驾驶系统。这项工作的主要动机是避免识别人类指定的特定特性,例如车道标记、护栏或其他车辆,并避免根据对这些特性的观察创建if, then, else规则集合。本文描述了这项新工作的初步结果。
2 DAVE-2系统概述
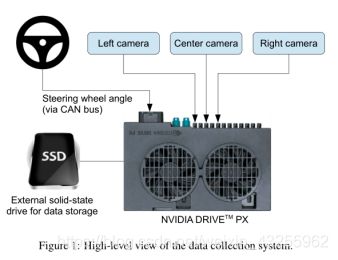
图像为两个特定的偏离中心位移可以获得从左和右相机。通过对距离最近的摄像机图像进行视点变换,来模拟摄像机之间的位移和所有转动。精确的视点转换需要三维场景知识,而我们没有。因此,我们通过假设视界以下的所有点都在平坦的地面上,而视界以上的所有点都无限远来近似这个变换。这对于平坦的地形很有效,但是它会对地面上的物体造成变形,比如汽车、杆子、树和建筑物。幸运的是,这些扭曲并没有给网络培训带来大问题。转换后的图像的转向标签被调整到一个,将引导车辆回到所需的位置和方向在两秒内。
我们的培训系统框图如图2所示。图像被输入到CNN中,然后CNN计算出一个建议的控制命令。将建议的命令与图像所需的命令进行比较,调整CNN的权值,使CNN输出更接近所需的输出。权重调整是使用Torch 7机器学习包中实现的反向传播来完成的
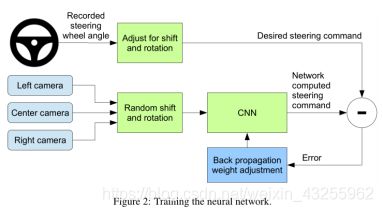
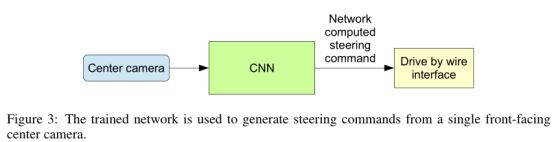
一旦训练,网络可以从一个单中心摄像机的视频图像生成转向。此配置如图3所示。
3 数据收集
通过在各种各样的道路上以及在各种照明和天气条件下行驶来收集训练数据。 尽管公路数据也来自伊利诺伊州,密歇根州,宾夕法尼亚州和纽约,但大多数公路数据是在新泽西州中部收集的。 其他道路类型包括两车道道路(带和不带车道标记),带停放的汽车,隧道和未铺砌道路的住宅道路。 白天和黑夜都在晴朗,多云,有雾,下雪和下雨的天气中收集数据。 在某些情况下,太阳在天空中较低,导致眩光从路面反射并从挡风玻璃上散射。
这些数据是通过我们的线控驱动测试车(2016年的林肯MKZ)或2013年的福特福克斯(Ford Focus)获得的。该系统不依赖于任何特定的车辆制造或模型。司机们被鼓励保持全神贯注,但其他方面则照常开车。截至2016年3月28日,共收集了约72小时的驾驶数据。
4网络体系结构
我们训练网络的权重,以最小化网络输出的转向命令与人类驾驶员的命令或针对偏心和旋转图像调整后的转向命令之间的均方误差(请参见第5.2节)。 我们的网络体系结构如图4所示。该网络由9层组成,包括标准化层,5个卷积层和3个完全连接的层。 输入图像被拆分为YUV平面并传递到网络。
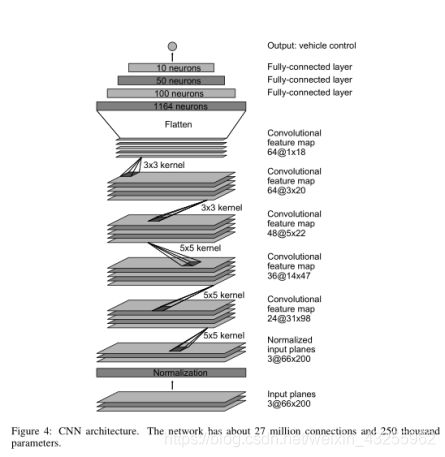
网络的第一层执行图像归一化。 规范化器是硬编码的,在学习过程中不会进行调整。 在网络中执行规范化可以使规范化方案随网络体系结构进行更改,并可以通过GPU处理来加速。
卷积层被设计用来执行特征提取,并通过一系列改变层配置的实验进行经验选择。 我们在前三个卷积层中使用步幅卷积,步幅为2×2,内核为5×5,在最后两个卷积层中使用非卷积卷积为3×3内核。
我们在五个卷积层之后加入三个完全连接的层,得到一个输出控制值,即反向转弯半径。完全连接的层被设计成控制方向的控制器,但是我们注意到,通过端到端训练系统,不可能在网络的哪些部分主要作为特征提取器和哪些部分作为控制器之间做出明确的区分。
5训练细节
5.1 数据选择
训练神经网络的第一步是选择要使用的帧。我们收集的数据被标记为道路类型、天气状况和驾驶员的活动(保持车道、换车道、转弯等)。为了训练CNN进行车道跟踪,我们只选择司机所在车道的数据,而放弃其他数据。然后我们以10fps的速度采样。较高的采样率将导致包含高度相似的图像,因此不能提供太多有用的信息。
为了消除直线驾驶的偏差,训练数据包含了更高比例的表示道路曲线的帧。
5.2 增加数据量(特殊情况)
在选择了最后一组帧之后,我们通过添加人工移位和旋转来增强数据,以教导网络如何从不良的位置或方向中恢复。 这些扰动的大小是随机选择的,而不是正态分布。 分布的平均值为零,标准偏差是我们使用人工驾驶员测量的标准偏差的两倍。 随着幅度的增加,人为地增加数据的确增加了不希望的假象(参见第2节)。
6模拟
在对训练好的CNN进行路试之前,我们首先在仿真中评估网络性能。仿真系统的简化框图如图5所示。

该模拟器从一辆由人驾驶的数据收集车上的一个前向机载摄像机中获取预先录制的视频,并生成图像,这些图像与CNN转向车辆时的图像大致相同。这些测试视频是与人类驾驶员产生的驾驶指令同步的。
由于人类驾驶员可能不会一直在车道中心行驶,所以我们需要手动校准模拟器使用的视频中与每一帧相关的车道中心。我们称这个位置为真实地面(“ground truth”)。
模拟器会转换原始图像,以说明与地面真实情况的偏差。 请注意,这种转换还包括人为驱动的路径与地面真理之间的任何差异。 转换是通过第2节中描述的相同方法完成的。
模拟器访问录制的测试视频以及在视频被捕获时发生的同步转向命令。模拟器将选择的测试视频的第一帧发送到训练好的CNN输入,并根据与地面真实情况的偏差进行调整。然后,CNN返回该帧的控制命令。将CNN转向命令和记录的人驾驶命令输入车辆动态模型[8],更新模拟车辆的位置和方向。
然后模拟器修改测试视频中的下一帧,使图像看起来就像车辆处于由CNN发出的转向指令所导致的位置。然后这个新的图像被输入到CNN,然后重复这个过程。
模拟器记录离中心的距离(从车到车道中心的距离)、偏航和虚拟车行驶的距离。当偏离中心距离超过1米时,触发虚拟人为干预,复位虚拟车辆的位置和方向,使其与原测试视频对应帧的地面真值匹配。
7 评估
评估我们的网络需要两个步骤,首先是模拟,然后是路上测试。
在模拟中,我们让网络在模拟器中为一系列预先录制的测试路线提供驾驶指令,这些路线相当于在新泽西州蒙茅斯县(Monmouth County)行驶约3小时100英里。测试数据取自不同的照明和天气条件,包括高速公路、当地道路和居民街道。
7.1 仿真
我们估计网络能够自动驾驶汽车的时间百分比。该度量是通过计算模拟的人为干预来确定的(参见第6节)。这些干预发生在模拟的车辆偏离中心线超过1米时。我们假设在现实生活中,一次实际的干预总共需要6秒钟:这是一个人重新控制车辆,重新调整中心,然后重新启动自动转向模式所需的时间。我们通过计算干预的数量,乘以6秒,除以模拟测试的运行时间,然后从1中减去结果,从而计算出百分比自主性:

因此,如果我们在600秒内进行10次干预,我们的自主价值就会是:
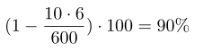

图6:交互模式下模拟器的屏幕截图。性能计量的解释见第7.1节。由于视点变换,左边的绿色区域是未知的。地平线下高亮的宽矩形是发送给CNN的区域。
7.2 路上测试
经过培训的网络在模拟器中表现出良好的性能后,将网络加载到我们测试车中的DRIVE TM PX上并进行路测。 对于这些测试,我们将性能测量为汽车执行自动转向的时间的一部分。 这段时间不包括车道变化和从一条道路转向另一条道路。 从新泽西州霍姆德尔办事处到大西洋高地,在新泽西州蒙茅斯县进行一次典型的驾车之旅,大约98%的时间我们都是自主的。 我们还沿着花园州立公园大道(多车道划分的高速公路,上下坡道)行驶了10英里,拦截次数为零。
7.3 CNN内部状态可视化
图7和图8显示了两个不同示例输入(未铺设的道路和森林)的前两个功能映射层的激活情况。在未铺路的情况下,feature map的激活可以清晰的显示出道路的轮廓,而在森林的情况下,feature map包含的噪声较多,即CNN在这张图片中没有找到有用的信息。
这说明CNN学会了自己去检测有用的道路特征,即,仅以人的转向角度作为训练信号。例如,我们从未明确地训练它探测道路轮廓。

图7:CNN如何看待未铺设的道路。顶部:发送到CNN的摄像机图像子集。左下:激活第一层feature map。右下角:激活第二层feature map。这说明CNN学会了自己去检测有用的道路特征,即,仅以人的转向角度作为训练信号。我们从未明确地训练它去探测道路的轮廓。

图8:没有道路的示例图像。 前两个特征图的激活似乎主要包含噪声,即CNN无法识别此图像中的任何有用特征。
8结论
我们已经通过实验证明,CNNs能够在不需要人工分解成道路或车道标记检测、语义抽象、路径规划和控制的情况下,学习车道和道路跟随的整个任务。从不足100小时的驾驶中得出的少量训练数据,就足以训练汽车在各种条件下,在阳光、多云和下雨的情况下,在高速公路、地方和居民区的道路上行驶。CNN能够从一个非常稀疏的训练信号(单独转向)中学习有意义的道路特征。
例如,系统在训练过程中不需要显式标签就可以检测道路轮廓。
