说话人识别中训练通用背景模型(UBM)的研究
摘要:
以高斯分布为基础的说话人识别系统使用通用背景的模型(UBM)需要广泛的数据资源尤其是多信道和多个麦克风种类下采集语音。本研究主要是对训练UBM模型数据的选择对整个系统性能的影响做一个系统的分析,训练UBM模型时选择的数据的方式主要涉及下面几个方面:数据数目的改变、特征帧的子样本结构、说话人数量的改变。UBM的协方差矩阵和系统性能有高度相关性,因此主要通过计算UBM协方差矩阵看系统性能,主要在下面几种情况下计算UBM的协方差矩阵:保持训练UBM模型的数据集合不变,总的数据数量改变;保持数据总量不变,改变训练UBM的说话人数量。讨论了特征子样本选择在提升计算速度方面的优点。一个新颖有效的基于距离的语音帧的选择方法(phonetic distance-based frame selection method)被提出。子样本的方法在仅仅使用1%的原始UBM训练数据的情况下能够跟基线系统保持一致,这样就能使得训练时间巨幅减少。打破了数据越多越好的迷信。在保持数据总量不变的情况下,增加训练UBM模型的说话人的数量可以提升系统性能。最后,基于不同说话人种类的两种说话人选择方案被提出后,实验发现,通过选择UBM说话人多样性,在使用少于原始UBM模型训练数据30%的情况下,系统性能仍然能保持基线系统水平。
I.介绍
基于GMM的说话人识别模型历久不衰,最基础的基于GMM的说话人识别方法包括GMM-UBM(通用模型参数的后验概率自适应)和GMM超矢量的支持向量机模型(GMM-SVM)。所有这些方法得到完善通过使用额外的归一化方案,如因子分析,eigenvoice(语音本征)或者nuisance attribute projection(NAP)(?滋扰性映射)。
说话人识别系统中基本都有一个共同元素就是UBM,本质是一个大GMM,通常训练出来用来表示所有说话人的语音帧的与说话人无关的分布,作为the expected alternative speaker model(预期的说话人替代模型)同时也用于开源集合的说话人识别系统(open-set speaker recognition ).在GMM-SVM,GMM-UBM中,所有说话人模型都依赖于UBM。关于UBM研究较少,训练UBM的通常想法是用尽可能多的说话人和涵盖各种环境的(信道和说话环境)语音来训练。没有考虑UBM训练对系统整体性能的影响。本文给出UBM训练过程和UBM训练数据组成与系统性能的关系。

本文研究主要集中于数据参数的部分改变对系统性能的影响。
之前学术界一致认为用越多的语音数据训练UBM越越能模拟真实世界的语音环境,但是没有证据表明是对的哟,【2】文献表明只要说话人的数量保持一致,少量语音数据依旧可以得到性能好的说话人识别系统。本文,系统分析UBM训练中这个方法的影响,从UBM参数中确定数据多样性的衡量标准,然后确定这些变化与系统性能的关系。
从给定语音信息中抽取特征向量子集从而减少数据量,抽取方式:随机抽取特征帧(没考虑语音内容不靠谱),本文使用an adaptive phoneme dependent feature sub-sampling scheme(自适应音素依赖特征子采样方案),来使用少量数据抓住每段语音特征的细微差别。说话人之间多样性与UBM相关,说话人自身语音音素多样性与UBM无关,一个说话人语音时间太长,有些音素会出现的很频繁或者持续时间较长,这就会导致这个音素在UBM模型中说话人自身的概率密度函数失衡(???)。通过选择特征矢量方式减少数据量对计算资源和系统性能都有好处。
UBM数据的说话人之间多样性与目前数据库中说话人数量直接相关。UBM训练数据的说话人数量对系统性能有影响。如何选择多样化的UBM说话人数据也是本文所讨论的。
II UBM定义 以及理想的UBM的参数设定
使用大量的说话人语音的声学特征训练的与说话人无关的高斯混合模型,这个模型代表了
III 基线系统
IV 改变UBM训练数据数量对系统性能影响
V 特征子采样方法
VI 分析改变说话人数量的影响
VII 说话人子采样方法
VIII 结论
UBM训练数据参数的改变可能对提升系统性能EER降低或者minDCF没啥影响,但是就使用少量数据就能训练处UBM模型节省计算资源和得到一个涵盖面更广的平衡的UBM很重要。
II 理想UBM
UBM是说话人无关的GMM,使用大量说话人的语音声学特征训练得到,用来表示特征的说话人无关的通用的概率分布。

A 数据平衡 B 数据量

III 基线系统
A 系统概述
没有错误匹配补偿和分数归一化的标准GMM-UBM模型
1.前端取39维MFCC
2.特征扰动(feature warping)
3. VAD
4.1024 mixtures
5.使用HTK Tools中的最大似然估计标准 进行15次迭代/per mixture split
6.选取期望log似然最佳20个分数
B.UBM数据库
1)NIST SRE 2004 1-s 126个男语音 5-min/per
2) NIST SRE 2006 和NIST SRE 2004 392个男发音 多信道和多麦克风
C 计算资源
IV UBM数据选择
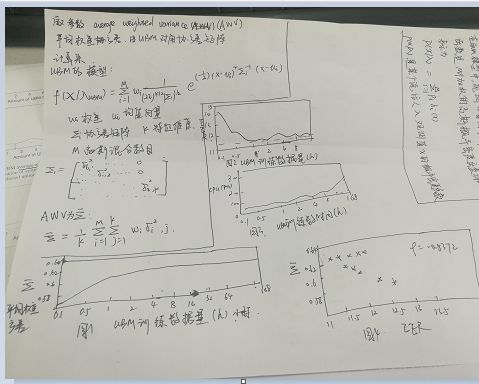
从上面的四幅图可知每个语音选取2.7s就足以得到较好的识别结果。
V 特征帧的子采样
LSF:选取一段语音的前几帧
UFS:均匀在这段语音上选取几帧
RFS:随机在这段语音上选取几帧
IFS:根据帧之间相似度(用距离测量)进行选取差异性大的帧
A。基于欧氏距离的特征帧选取

IFS方法太特么复杂我看了三遍没整明白,我打算后期再推,赶进度。。。不懂别怪别怪。。。无视上面的夹爪字。。。
B。性能比较
IFS的帧选择方案性能最好
VI 说话人数量影响
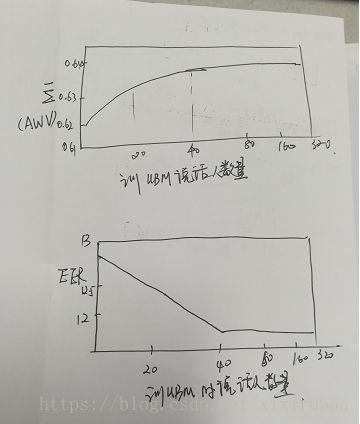
不多解释都在图里
VII 说话人数据选择
选择大量不相似的说话人能够提升系统性能。说话人之间的相似性会导致聚类的产生,从而在计算似然度的时候出现不平衡现象,这里说话人的选择依据就是对于相似的说话人只选择其中一个,差异性比较大的说话人都选择进来作为UBM模型训练的样本。选择方法有以下两种:
A. KL Divergence-Based Speaker Selection
比较两个说话人模型之间的KL差异

试验之后结论:如果训练UBM模型的说话人多样性进行仔细选择,很少的数据的训练就能达到基线系统水平
VIII 结论
适当减少语音量和仔细选择说话人数量能够达到基线系统识别水平。