深度学习|反向传播算法(BP)原理推导及代码实现
请点击上面公众号,免费订阅。
《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!
01
—
回顾
昨天,分析了手写字数据集分类的原理,利用神经网络模型,编写了SGD算法的代码,分多个epochs,每个 epoch 又对 mini_batch 样本做多次迭代计算,详细的过程,请参考:
深度学习|神经网络模型实现手写字分类求解思路
这其中,非常重要的一个步骤,便是利用反向传播(BP)算法求权重参数的梯度,偏置量的梯度。下面根据以下几个问题展开BP算法:
什么是BP算法?
为什么叫做反向传播?
如何构思BP算法的切入点?
误差是如何传播开的?
如何求出权重参数的梯度和偏置量的梯度?
链式规则是怎么一回事?
02
—
统一符号表达
神经网络每个神经元的连接关系,用符合如何表达呢? 下面定义一种表达方式,如下图所示,含有一个隐含层的神经网络,图中标出的w的含义为:第三层的第2个神经元与第二层的第4个神经元间的权重参数。
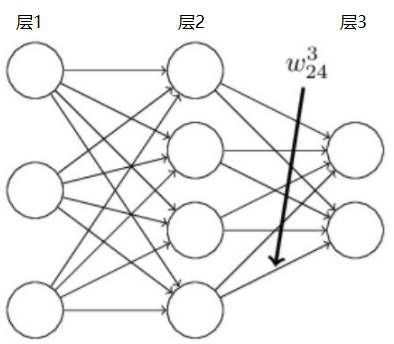
再看下,标红色箭头的神经元的偏移量 b,如图所示进行标记,第二层中第3个神经元的偏移量;标绿色箭头的神经元的输出 a 为如下图所示标记,为第三层中第一个神经元的输出。

第 L 层第 j 个神经元的输出等于,前1层即 L-1 层中所有神经元的带权的输入和,然后再映射到sigmoid激活函数中,得到如下公式所述:
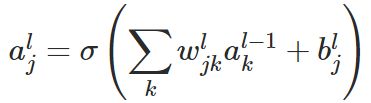
一定要仔细理解这种上述公式的各个符号表达,它是理解以下对 BP 算法论述的前提。
03
—
BP算法推导
3.1 公式1
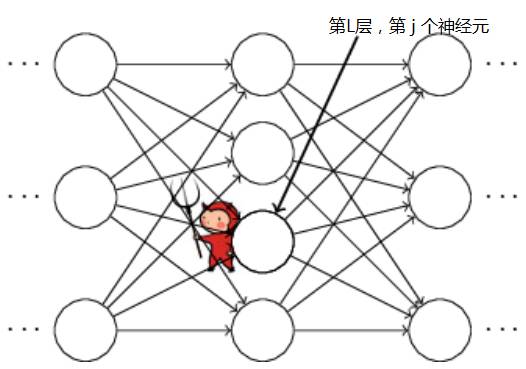
如下图所示,有个精灵跑到了网络中,假设位于第L层,第 j 个神经元的门口处,它引起了一点扰动,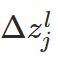 ,
,
z的含义是加权输入项,容易得出这个扰动项对成本函数造成的损失可以定义为:
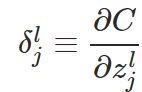
那么,类推的,可以看出在输出层 L, 误差项的定义表达为如下,第一个公式
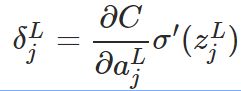
上式是根据链式规则可以推导得出,成本函数的改变首先是有第L层第j个神经元的输出项影响的,然后第 j 个神经元的输出又受到第 L层第 j 个神经元的干扰 z 影响,因此得到上式。这个式子的意义是定义了第 L层第 j个神经元的误差项怎么求,注意这里L可是输出层哦,那么如何求出第 L-1层中某个神经元的损失项(误差项)呢?
3.2 公式2
这就用到第二个公式,它给出了怎么由第 L层的误差推导出第L-1层的误差,先给出第二个公式:
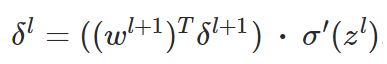
那么,这个公式,是如何得出的呢?这里面,这个公式是相对最难想的,推导过程如下:
还是从损失项的定义入手,
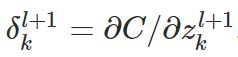

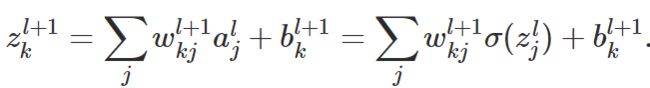
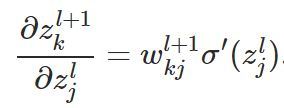
由以上这几个式子,就可以得出公式2 。
3.3 公式3
那么有了以上的分析,我们便能求解处任意层的损失项了,可以得出成本函数对某层某个神经元的梯度为,这是第三个公式:

还是可以由链式规则得出吧,如下推导过程:
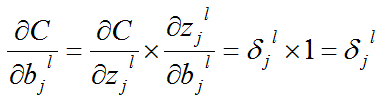
3.4 公式4
成本函数对权重参数的梯度为,这是第四个公式:

那么这个公式还是可以由链式规则得出,对其推导如下:
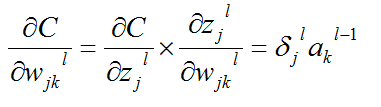
推导第三,四个公式,都用到了以下这个基本知识:

3.5 反向传播代码
根据这四个公式,可以得出BP算法的代码,每个步骤将公式放到上面,方便查看。
def backprop(self, x, y):
01 占位
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
02 前向传播求出每个神经元的输出项
activation = x
activations = [x] # 分层存储每层的输出项(对应上文中的 a)
zs = [] # 分层存储每层的 z 向量(对应上文中的 z)
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
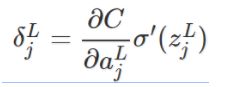 #activations[-1] 必须是最后一层
#activations[-1] 必须是最后一层
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
03 求偏置量的梯度

nabla_b[-1] = delta
04 求权重参数的梯度
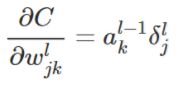
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
05 反向传播,依次更新每层的每个神经元的权重和偏移量
# L = 1 表示最后一层神经元, L = 2 倒数第二层神经元
for layer in range(2, self.num_layers):
z = zs[-layer]
sp = sigmoid_prime(z) #sigmoid函数的导数
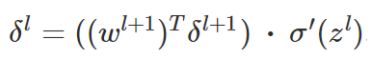
delta = np.dot(self.weights[-layer+1].transpose(), delta) * sp
nabla_b[-layer] = delta
nabla_w[-layer] = np.dot(delta, activations[-layer-1].transpose())
return (nabla_b, nabla_w)
def cost_derivative(self, output_activations, y):
"""
"""
return (output_activations-y)
好了,以上就是,BP算法的详细推导过程,谢谢您的阅读!
请记住:每天一小步,日积月累一大步!

《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!