PyTorch torch.optim.lr_scheduler 学习率设置 调参-- CyclicLR
torch.optim.lr_scheduler 学习率设置 – CyclicLR
学习率的参数调整是深度学习中一个非常重要的一项,Andrew NG(吴恩达)认为一般如果想调参数,第一个一般就是学习率。
作者初步学习者,有错误直接提出,热烈欢迎,共同学习。(感谢Andrew ng的机器学习和深度学习的入门教程)
【来源: https://pytorch.org/docs/stable/optim.html】
基本内容
CyclicLR循环学习率
这个学习方式是《Cyclical Learning Rates for Training Neural Networks》2017论文中提出;
这篇论文是从学习率的角度来谈怎么训练深度网络的。
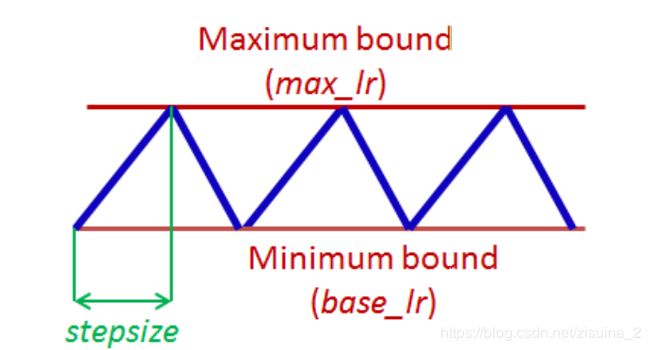
提出了一种新的学习率方法,叫cyclical learning rates,简称CLR。和从前的学习率不同,或者固定(fixed)或者单调递减,这是周期性变化。有三个参数,max_lr,base_lr, stepsize,即上下边界和步长。
论文中给出了三个参数的设定办法。方法取名为triangular;stepsize=(样本个数/batchsize)*(2~10)
先将max_lr设置为stepsize同样的值,base_lr为原架构的初始值,然后以此迭代5到10个epoch,画学习率与准确率之间的关系图,找最开始收敛的点和收敛后第一个下降的点,记录下来作为base_lr和max_lr的值。
并将CLR方法做了两个变异,分别是triangular2和exp range。
triangular2:同triangular非常相似,除了在每一迭代周期结束时,学习率差减小一半,即每个周期后学习率差异下降。
exp_range(指数范围):学习率在最大和最小边界内变化,每一个边界值通过一个指数因子下降。
【引用: https://blog.csdn.net/guojingjuan/article/details/53200776】
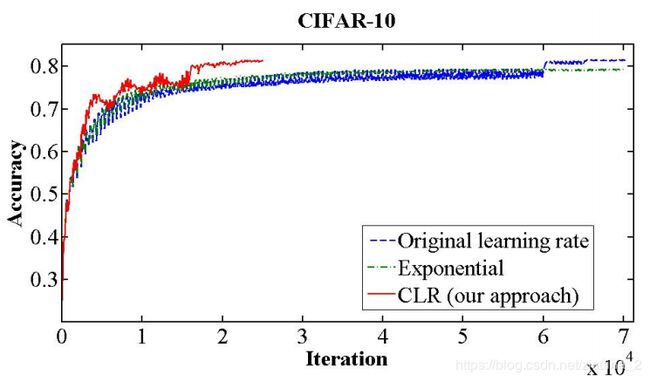
哇塞,用三种方法对比,怎么感觉有点厉害啊!
方法一(蓝色 original learning rate):学习率不变
方法二(绿色 exponential): 指数衰减;例如【0.1, 0.001, 0.0001】
方法二(红色 cyclical learning rates):虽然曲折,但是收敛很快,而且准确率也高。
我要用自己的数据集试一试了,两天后再添加结果:
其余注意事项:
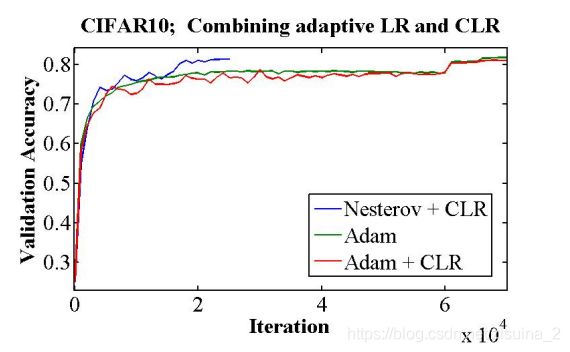
上图是对两个优化器,以及加不加CLR进行对比
方法一(蓝色 Nesterov+CLR)
方法二(绿色 Adam)
方法二(红色 Adam+CLR)
这里蓝色最好啊,推荐Nesterov Momentum+CLR?默默地改了自己的优化器。
作者论文中的参数设置
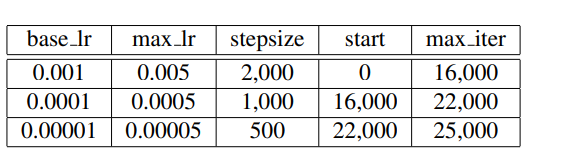
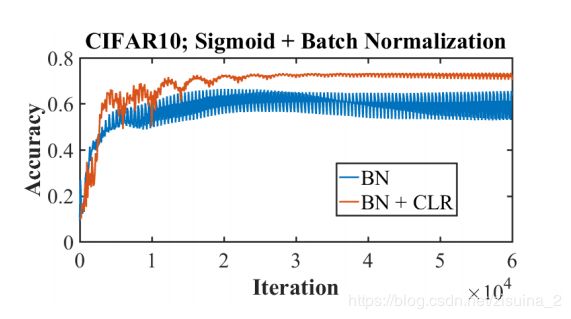
有BN的CLR更好,嗯哼!!
使用案例 torch
#设置优化器
optimizer = torch.optim.SGD(model.parameters(), lr=opt.lr, momentum=0.9)
base_lr = 1e-4
max_lr = 5e-4
#设置 学习率调节方法
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=500, step_size_down=500, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)
for epoch in range( opt.num_epochs ):
train(...)
validate(...)
scheduler.step()
| 项目 | Value |
|---|---|
| base_lr | 基础学习率 |
| max_lr | 学习率的上限 |
| step_size_up | 学习率上升的步数 |
| step_size_down | 学习率下降的步数 |
| mode | 三种模式:triangular,triangular2和exp_range,和之前的几个参数交互所用,如果scale_fn不是None则忽略 |
| gamma | exp_range中的常量gamma**(cycle iterations) |
| scale_fn | 自定义的缩放策略保证所有x>=0的情况下scale_fn(x)的值域是[0,1] |
| scale_mode | :两种模式cycle和iterations决定scale_fn函数以何种方式作用 |
| cycle_momentum | 如果为True,则动量与’base_momentum’和’max_momentum之间的学习率成反比 |
| base_momentum | 初始动量,即每个参数组的循环中的下边界。 |
| max_momentum | 每个参数组的循环中的上动量边界。 在功能上,它定义了循环幅度(max_momentum - base_momentum)。 任何周期的动量都是max_momentum和幅度的一些比例的差异; 因此,实际上可能无法达到base_momentum,具体取决于缩放功能。 |
原文链接:https://blog.csdn.net/GrayOnDream/article/details/98518970
相关内容
该论文作者是Leslie N. Smith;实验室:U.S. Naval Research Laboratory (https://www.nrl.navy.mil/ , 可以的可以去看看,我腿短,翻不过去 /(ㄒoㄒ)/~~)

作者PHD(1976 – 1979):University of Illinois at Urbana-Champaign;传说中的博士后? Post DoctoralQuantum Chemistry(1979 – 1980): Princeton University;看起来有一定’历史’地位了。_ linkin的链接甩给你们: https://www.linkedin.com/in/drlesliensmith
美国海军研究实验室(NRL)是美国海军和美国海军陆战队的企业研究实验室,从事基础科学研究,应用研究,技术开发和原型制作。 实验室的专业包括等离子体物理,空间物理,材料科学和战术电子战。(传说中的国企??厉害,厉害)
ERROR
这么设置对吗?额(⊙o⊙)…,等我看看结果再更新!
base_lr = 1e-6
max_lr = 4e-4
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=30, step_size_down=30, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)
ValueError: optimizer must support momentum with `cycle_momentum` option enabled
这里的优化器是adam, 所以cycle_momentum=True, 改为 cycle_momentum=False
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=30, step_size_down=30, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)