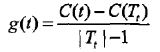【统计学习方法-李航-笔记总结】五、决策树
本文是李航老师《统计学习方法》第五章的笔记,欢迎大佬巨佬们交流。
主要参考博客:
https://blog.csdn.net/u014248127/article/details/78971875
https://www.cnblogs.com/YongSun/p/4767085.html
主要内容包括:
1. 决策树模型与学习
2. 特征选择
3. 决策树的生成
4. 决策树的剪枝
5. CART算法
决策树(decision tree)是一种基本的分类与回归方法。本章主要讨论用于分类的决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是:模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
1. 决策树模型与学习
(1)决策树的认识: 这本书中提出的机器学习的三要素:模型、策略、算法。
模型: 分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node )和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。(简单说就是用我们熟悉的树结构去做分类,从根结点出发,对某一特征测试,将实例分到相应的子结点,指导所选的特征都测试完,到达叶结点的类中)如下图所示:其中圆代表内部节点(特征),方框代表叶结点(类)。

策略:决策树的学习本质上是从训练集数据中归纳出一组分类规则,这个规则不仅对训练数据有很好的描述,而且对未知数据有很好的预测 。学习决策树的策略,也就是决策树的损失函数在原文决策树剪枝部分介绍。简单理解就是:决策树的损失函数是正则化的极大似然函数,也就是模型对数据的拟合程度与模型复杂度(叶子的个数)的和。决策树的学习策略是以损失函数为目标函数的最小化。
算法: 决策树的学习算法分为三步:首先递归的选择特征、用选择的特征构造一个决策树、解决过拟合进行决策树剪枝。
(2)if-then规则与条件概率分布
if-then规则:可以将决策树看成一个if-then规则的集合,转换成if-then规则的过程:由决策树的根结点到叶结点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树的路径或其对应的if-then规则集合具有一个重要的性质:互斥并且完备,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。这里所谓覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件。
条件概率分布:决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分(partition)上,将特征空间划分为互不相交的单元(cell)或区域(region),并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的一条路径对应于划分中的一个单元。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。条件概率分布可以表示为P(Y|X),X取值于给定划分下单元的集合,Y取值于类的集合。各叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大。决策树分类时将该结点的实例强行分到条件概率大的那一类去。决策树与特征空间与条件概率分布的对应关系如下图所示:

其中,(b)图的x(1)-x(2)平面(底面)可以看做是(a)图顺时针旋转90度得到的,所以条件概率可以对应于(a)图的特征空间划分,并且看作是(a)图在空间上的延伸。
2. 特征选择
特征选择问题:特征选择在于选取对训练数据具有分类能力的特征。通常特征选择的准则是信息增益或信息增益比。
(1)信息增益:
信息熵H(x):代表的是随机变量不确定的度量,熵是平均信息量,熵越大,不确定性越大,信息量就越大。
X是一个取有限个离散值的随机变量,其概率分布为:![]() ,
,
则随机变量X的熵的定义为:![]()
由上式知,熵只依赖于X的分布,与X的取值无关,也可记作H(p),即:
例子如下:

设随机变量(X,Y),其联合概率分布为:![]()
条件熵H(Y|X):表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望: ,
,![]()
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵( empirical entropy)和经验条件熵(empirical conditional entropy )。
信息增益:表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。定义为:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:![]()
一般地,熵H(Y)与条件熵H(Y|X)之差称为互信息,决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
对信息增益公式的理解:对于给定数据集D和特征A,经验熵H(D)表示对数据集D分类的不确定性,条件经验熵H(D|A)表示在特征A的条件下对数据集D进行分类的不确定性,那么它们的差,即信息增益,表示由于特征A是的数据集D的分类的不确定性减少的程度。显然,对于数据集D,信息增益依赖于特征,不同特征往往具有不同的信息增益,信息增益大的特征分类能力强。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。信息增益的算法如下:


其中,|D|表示其样本容量,即样本个数。设有K个类Ck,k=1,2,...,K,|Ck|为属于类Ck的样本个数。根据特征A的取值将D划分为n个子集D1,D2,...,Dn,|Di|为Di的样本个数。记子集Di中属于类Ck的样本的集合为Dik。
(2)信息增益比
信息增益值的大小是相对训练数据而言的,并没有绝对意义,在分类问题困难时,也就是在训练集数据集的经验熵大的时候,信息增益值会偏大,反而会偏小,因此用信息增益比校正这一问题。
信息增益比:特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验H(D)之比:
3. 决策树的生成
(1)ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树,具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,对子结点递归调用上述方法,构建决策树,直到所有特征的信息增益都很小或者没有特征选择为止。ID3相当于用极大似然法进行概率模型的选择。算法流程如下:


ID3算法只有树的生成,因此很容易产生过拟合。
(2)C4.5的生成算法
C4.5与ID3算法相似,不同是用信息增益比来选择特征。算法流程如下:

4. 决策树的剪枝
决策树的生成算法容易构建过于复杂的决策树,产生过拟合。、
剪枝:在决策树学习中将已生成的树进行简化的过程称为剪枝(pruning)。具体地,剪枝从已生成的树上裁掉一些子树或叶结点,并将其根结点或父结点作为新的叶结点,从而简化分类树模型.
决策树的剪枝往往通过极小化决策树整体的损失函数(loss fimction)或代价函数( cost function)来实现。
设树T的叶结点个数为|T|, t是树T的叶结点,该叶结点有Nt个样本点,其中k类的样本点有Ntk个,k=1,2,...,K,Ht(T)为叶结点t上的经验熵,a>=0为参数,则决策树学习的损失函数可以定义为:
其中,经验熵为 ,在损失函数中,将第一项记作:
,在损失函数中,将第一项记作: ,则有:
,则有:![]() ,式中,C(T)表示模型对训练数据的预测误差,即模型与训练数据的拟合程度,|T|表示模型复杂度,参数α控制两者之间的影响,大点促使选择简单的模型,小点促使选择复杂的模型。
,式中,C(T)表示模型对训练数据的预测误差,即模型与训练数据的拟合程度,|T|表示模型复杂度,参数α控制两者之间的影响,大点促使选择简单的模型,小点促使选择复杂的模型。
剪枝,就是当α确定时,选择损失函数最小的模型,即损失函数最小的子树。损失函数正好表示了对模型的复杂度和训练数据的拟合两者的平衡。
决策树生成只考虑了通过提高信息增益(或信息增益比)对训练数据进行更好的拟合,学习局部的模型;
决策树剪枝通过优化损失函数还考虑了减小模型复杂度,学习整体的模型。
利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择。
剪枝算法流程如下:


5. CART算法
分类与回归树(classification and regression tree, CART)模型同样由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。 CART算法由以下两步组成:
(1)决策树生成:基于训练数据集生成决策树,牛成的决策树要尽量大;
(2)决策树剪枝:用验证数据集对己生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
5.1 CART生成
决策树的生成就是递归构建二叉决策树的过程,对回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择。
(1)回归树的生成:它每次选择的是一个空间划分(j,s),j代表第j个特征,s是这个特征取的值,然后根据选择划分构建树。

(2)分类树的生成
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点.
基尼指数:分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为: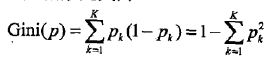
对于二分类问题,若样本点属于第一个类的概率为p,则基尼指数为:![]()
对于给定的样本集合D,其基尼指数为: ,Ck是D中属于第k类的样本子集,K是类个数。
,Ck是D中属于第k类的样本子集,K是类个数。
如果样本集合D根据特征A是否取某一可能值a被分割成D1和D2两部分,则在特征A的条件下,集合D的基尼指数定义为:

基尼指数Gini(D)表示集合D的不确定性,Gini(D,A)表示经A = a分割后集合D的不确定性,基尼指数越大,样本的不确定性越大,因此想要分割后不确定性尽量小,基尼系数也得尽量小,也就是说基尼系数小的特征更适合划分样本。
下图显示二分类中,Gini、熵之半(1/2H(p))和分类误差率的关系,可以看出基尼系数和熵之半的曲线很接近,都可以近似分类误差率:

CART生成算法流程如下:


5.2 CART剪枝
CART剪枝算法由两步组成:首先从生成算法产生的决策树T0底端开始不断剪枝,直到T0的根结点,形成一个子树序列代{T0,T1,...,Tn};然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。
(1) 剪枝,形成一个子树序列
在剪枝过程中,计算子树的损失函数:![]()
可以用递归的方法对树进行剪枝,将a从小增大,a0 对T0中每一内部结点t,计算: 表示剪枝后整体损失函数减少的程度,在T0中剪去g(t)最小的Tt,将得到的子树作为T1,同时将最小的g(t)设为a1,T1为区间[a1,a2)的最优子树。如此剪枝下去,直至得到根结点。在这一过程中,不断地增加a的值,产生新的区间。 (2) 在剪枝得到的子树序列T0, T1, ... , Tn中通过交叉验证选取最优子树Ta 具体地,利用独立的验证数据集,测试子树序列T0, T1, ... , Tn中各棵子树的平方误差或基尼指数。平方误差或基尼指数最小的决策树被认为是最优的决策树。在子树序列中,每棵子树T0, T1, ... , Tn都对应于一个参数a0, a1, ... , an。所以,当最优子树Tk确定时,对应的ak也确定了,即得到最优决策树Ta。 算法流程如下: 关于熵、条件熵、信息增益、信息增益比、基尼系数的专题对比可见博客: https://blog.csdn.net/bitcarmanlee/article/details/51488204