DPDK — PMD,DPDK 的核心优化
目录
文章目录
- 目录
- 前文列表
- PMD,DPDK 的核心优化
- PMD 与 UIP 的交互实现
- PMD 的应用层实现
- 参考文章
前文列表
《DPDK — 安装部署》
《DPDK — 数据平面开发技术》
《DPDK — 架构解析》
《DPDK — IGB_UIO,与 UIO Framework 进行交互的内核模块》
PMD,DPDK 的核心优化
我们知道,Linux 内核在收包时有两种方式可供选择,一种是中断方式,另外一种是轮询方式。
从哲学的角度来说,中断是外界强加给你的信号,你必须被动应对,而轮询则是你主动地处理事情。前者最大的影响就是打断你当前工作的连续性,而后者则不会,事务的安排自在掌握。
中断对性能的影响有多大?在 x86 体系结构中,一次中断处理需要将 CPU 的状态寄存器保存到堆栈,并运行中断服务程序,最后再将保存的状态寄存器信息从堆栈中恢复。整个过程需要至少 300 个处理器时钟周期。
轮询对性能的提升有多大?网卡收到报文后,可以借助 DDIO(Direct Data I/O)技术直接将报文保存到 CPU 的 Cache 中,或者保存到内存中(没有 DDIO 技术的情况下),并设置报文到达的标志位。应用程序则可以周期性地轮询报文到达的标志位,检测是否有新报文需要处理。整个过程中完全没有中断处理过程,因此应用程序的网络报文处理能力得以极大提升。
故此,想要 CPU 执行始终高效,就必然需要一个内核线程去主动 Poll(轮询)网卡,而这种行为与当前的内核协议栈是不相容的,即便当前内核协议栈可以使用 NAPI 中断+轮询的方式,但依旧没有根本上解决问题。除非再重新实现一套全新的内核协议栈,显然这并不现实,但幸运的是,我们可以在用户态实现这一点。
针对 Intel 网卡,DPDK 实现了基于轮询方式的 PMD(Poll Mode Drivers)网卡驱动。该驱动由用户态的 API 以及 PMD Driver 构成,内核态的 UIO Driver 屏蔽了网卡发出的中断信号,然后由用户态的 PMD Driver 采用主动轮询的方式。除了链路状态通知仍必须采用中断方式以外,均使用无中断方式直接操作网卡设备的接收和发送队列。
PMD Driver 从网卡上接收到数据包后,会直接通过 DMA 方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。
PMD 极大提升了网卡 I/O 性能。此外,PMD 还同时支持物理和虚拟两种网络接口,支持 Intel、Cisco、Broadcom、Mellanox、Chelsio 等整个行业生态系统的网卡设备,以及支持基于 KVM、VMware、 Xen 等虚拟化网络接口。PMD 实现了 Intel 1GbE、10GbE 和 40GbE 网卡下基于轮询收发包。
UIO+PMD,前者旁路了内核,后者主动轮询避免了硬中断,DPDK 从而可以在用户态进行收发包的处理。带来了零拷贝(Zero Copy)、无系统调用(System call)的优化。同时,还避免了软中断的异步处理,也减少了上下文切换带来的 Cache Miss。
值得注意的是,运行在 PMD 的 Core 会处于用户态 CPU 100% 的状态,如下图:
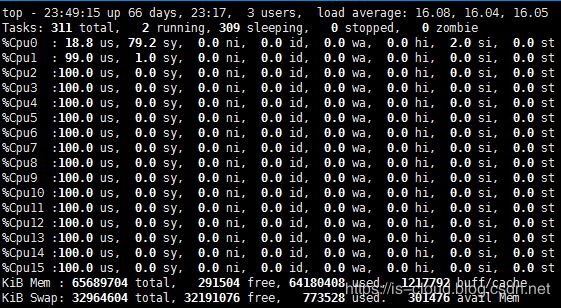
由于,网络空闲时 CPU 会长期处于空转状态,带来了电力能耗的问题。所以,DPDK 引入了 Interrupt DPDK(中断 DPDK)模式。Interrupt DPDK 的原理和 NAPI 很像,就是 PMD 在没数据包需要处理时自动进入睡眠,改为中断通知,接收到收包中断信号后,激活主动轮询。这就是所谓的链路状态中断通知。并且 Interrupt DPDK 还可以和其他进程共享一个 CPU Core,但 DPDK 进程仍具有更高的调度优先级。

PMD 与 UIP 的交互实现
对于 PMD 的实现来说,重点是处于用户态的 PMD 驱动程序如何通过 igb_uio 内核驱动模块与 UIO 进行交互,从而实现数据包处理的内核旁路。
- 调用 igbuio_setup_bars,设置 uio_info 的 uio_mem 和 uio_port。这一步骤的细节在前文中已有提到,igb_uio 内核模块在发现了 PCI 设备的 Memory BAR 和 IO BAR 之后会将这些 resources 的信息保存到 uioX 设备的 maps 中,这样处于用户态的 PMD 就可以访问这些原本只能被内核访问的 BAR 空间了。

- 设置 uio_info 的其他成员。
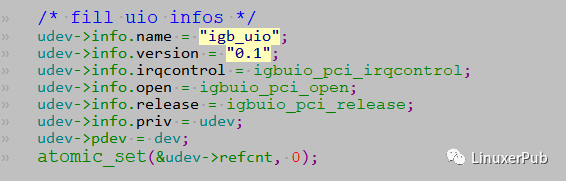
- 调用 uio_register_device,注册 uioX 设备。PMD 通过 uioX 设备与 igb_uio 内核驱动模块进行交互。

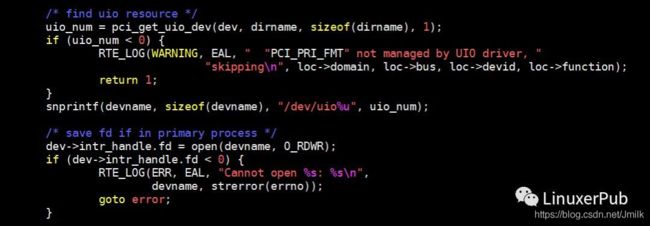
- 打开 uioX 设备,应用层已经可以使用 uioX 设备了。DPDK 的应用层代码,会打开 uioX 设备。在函数 pci_uio_alloc_resource 中。
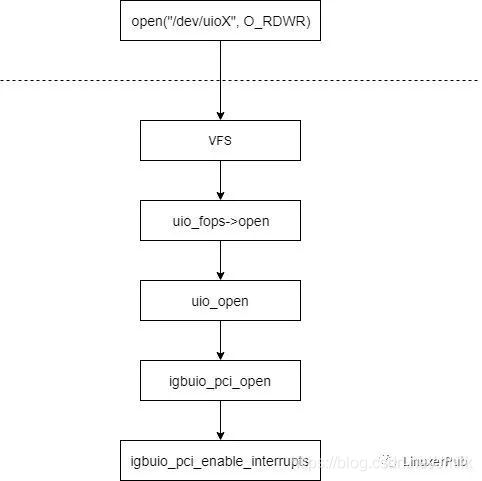
打开对应的 uioX 设备时,对应的内核操作为 uio_open(),其又会调用 igb_uio 的 open(),流程图如下:
- 设置中断信息,igb_uio 默认的中断模式为 RTE_INTR_MODE_MSIX,在 igbuio_pci_enable_interrupts 的关键代码如下:
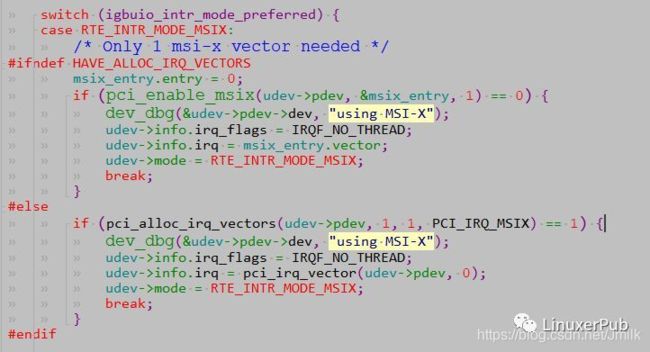
- 注册中断。当打开 uio 设备时,igb_uio 就会注册了一个中断。

那么为什么作为轮询模式的 PMD 驱动需要注册中断呢?这是因为,即使应用层可以通过 UIO 来实现设备驱动,但是设备的某些事件还是需要内核进行响应,然后通知应用层的。当然,PMD 的中断处理已经非常简单了。

其中的关键步骤是调用 uio_event_notify。

这个函数很简单:
- 增加 uioX 设备的 “事件” 数;
- 唤醒在 idev->wait 等待队列中的 task;
- 使用信号异步通知 async_queue 队列中的进程;
注意,因为目前 DPDK 没有使用异步 IO 的方式,所有对于 DPDK PMD 来说,只有前两个语句有用。
- 调用 UIO 的 mmap(),将注册的 uioX 设备的 “内存空间” 映射到应用空间,让 PMD 得以真正的从用户态中去访问内存。其 mmap 函数为 uio_mmap(),关键代码如下:

至此,UIO 框架和 igb_uio 内核模块已经可以让 PMD 访问 PCI 设备的大部分资源了。
PMD 的应用层实现
当 DPDK Application 启动时,会首先进行 EAL 初始化,如下图:

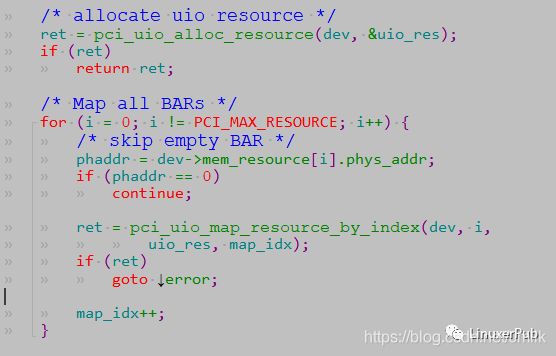
在 pci_uio_alloc_resource 中,主要是打开 DPDK Application 要管理的 uioX 设备。

同时,DPDK App 还需要把 PCI 设备的 BAR 映射到应用层。在 pci_uio_map_resource() 中,除了调用上图中的 pci_uio_alloc_resource,还会调用 pci_uio_map_resource_by_index 做资源映射。
下面就是 PMD 在应用层的驱动实现了。以最简单的 e1000 驱动为例,其初始化函数 eth_igb_dev_init 如下。

上面我们提到了,当 uioX 设备有事件触发时,由 eth_igb_interrupt_handler() 负责处理,实现了用户态的中断处理。

eth_igb_interrupt_handler 的实现非常简单,只是处理设备的状态变化事件,如:Link Status。
接下来,就是最重要的了,PMD 如何读取网卡数据。DPDK App 会调用 rte_eth_rx_burst 读取数据报文。

在这个函数中,会调用驱动 dev->rx_pkt_burst 来做实际的操作。以 e1000 为例,即 eth_igb_recv_pkts。
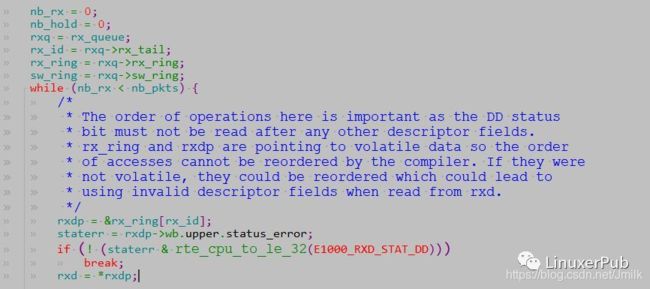

这里的实现很简单。如果网卡接收 buffer descriptor 表示已经完成一个报文的接收,有 E1000_RXD_STAT_DD 标志,则 rte_mbuf_raw_alloc 一个 mbuf,进行处理。如果没有报文,直接跳出循环。
对应 RTC 模型的 DPDK App 来说,就是不断的调用 rte_eth_rx_burst 去 “询问” 网卡是否有新的报文。如果有,就取走所有的报文或达到参数 nb_pkts 的上限。然后进行报文处理,处理完毕,再次循环。
参考文章
https://cloud.tencent.com/developer/article/1411982