SparseArray源码分析
在上一篇博客中,我们分析了Java中一种很常见的散列数据结构HashMap的原理(地址 http://blog.csdn.net/batmanbrucewayne/article/details/49638437)。但熟悉Android的朋友应该知道,当我们要使用Integer类型作为Map里的key时,在Android SDK中,提供了一种叫做SparseArray的数据结构来代替。原话是:Use new SparseArray instead for better performance。一直以来,我也是这么做的,但没有去深究SparseArray是如何有better performance的。
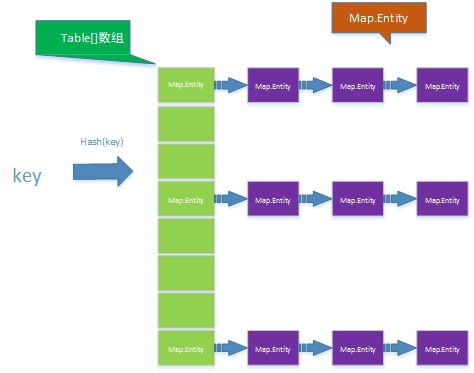
首先来回顾一下HashMap的实现原理(这里指的是Java 1.7版本的,HashMap在Java 1.8又有了比较大的改动,暂时先不讨论),总体来说HashMap是通过数组与链表的组合来实现的。数组中保存的是一个个HashMapEntry,这个HashMapEntry又可以保存另一个HashMapEntry的实例引用,为的是当key存在冲突时,能够在一个数组索引里保存一个链表结构,以解决冲突。以下是在网上找到的一张图,清晰明了。
回顾完HashMap的原理之后,我们来探究SparseArray性能更优的原因。源码中的注释,给了我们一些提示。
/**
* SparseIntArrays map integers to integers. Unlike a normal array of integers,
* there can be gaps in the indices. It is intended to be more memory efficient
* than using a HashMap to map Integers to Integers, both because it avoids
* auto-boxing keys and values and its data structure doesn't rely on an extra entry object
* for each mapping.
*/ 翻译过来,SparseArray性能的优势在于两方面。第一,它避免了对int类型的装箱拆箱的过程,第二,它不依赖其余的数据结构(Map.Entry)。知道了原因了以后,我们通过分析源码的方式来探究SparseArray的实现原理。
通过分析源码得知,SparseArray内部有两个数组mKeys与mValues,mKeys用于保存key,并且是有序的,mValues用于保存value。下面分析SparseArray关键的put与get方法。
public void put(int key, E value) {
//首先通过二分查找的方式判断此key是否存在于mKeys数组中
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
//如果存在,则直接将value修改
mValues[i] = value;
} else {
//获得该key需要插入mKeys数组的索引!
i = ~i;
//特殊情况,找到应该放置的位置,并且mValues保存的是被删除的对象,那么直接替换
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//如果需要gc并且数组长度不够了,则调用gc方法,并且再重新二分查找
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
//调用System#arraycopy方法,将key和value插入的数组当中!!
//这个地方是个关键,因为可以得知SparseArray的使用场景
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}经过分析得知,SparseArray源码的关键点在于保证mKeys数组有序,调用二分查找方法之后,如果是正数说明此key存在,可以直接更新。如果key不存在,二分查找的返回值是此key需要插入mKeys数组的索引再取反。获得该索引后,如果需要gc并且数组长度不够了,那么调用gc方法,并且再二分查找获得索引。之后,在GrowingArrayUtils#insert中,调用System#arraycopy方法,将key和value插入到数组中。这里有个关键的地方,由于插入key和value需要将索引之后的数据一一往后偏移,因此可以发现,SparseArray不适合有大量数据的情形!!
public static int[] insert(int[] array, int currentSize, int index, int element) {
assert currentSize <= array.length;
//可以看到,插入数据时,需要将array数组中所有index之后的数据一一往后偏移一个位置
if (currentSize + 1 <= array.length) {
//增加一个不越界的情况
System.arraycopy(array, index, array, index + 1, currentSize - index);
array[index] = element;
return array;
}
int[] newArray = ArrayUtils.newUnpaddedIntArray(growSize(currentSize));
System.arraycopy(array, 0, newArray, 0, index);
newArray[index] = element;
System.arraycopy(array, index, newArray, index + 1, array.length - index);
return newArray;
}再分析SparseArray的get方法。
public E get(int key, E valueIfKeyNotFound) {
//这个方法就简单很多了,直接在mKeys数组中二分查找,查找不到则返回默认值
//查找到了,直接从mValues数组中取出value
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}以上是对SparseArray源码的简单分析。可以得知,SparseArray使用了两个数组来保存key和value,mKeys数组是有序,调用put方法时,通过二分查找在mKeys数组中找到正确的索引,然后将数据保存在mKeys和mValues数组中。由于put方法是一个往数组里插入的过程,因此SparseArray不适用于大量的、无序的数据的场景。