如何配置一台高效的GPU(深度学习)服务器
目前GPU深度学习服务器在AI、视频处理、科学计算等领域都有广泛应用。随着NVIDIA推出更多的GPU硬件和工具软件,如何配置一台属于自己的GPU服务器,在开发者的工作中成为了重中之重。

文章大概:
1、硬件平台的搭建
o 深度学习服务器的性能需求
o NVIDIA GPU的性能特点
o 硬件环境的配置搭配要点
2、软件环境的配置
o 深度学习环境的系统配置,环境搭建
o NVIDIA CUDA的安装
o 介绍NVIDIA Deep Learning 相关SDK工具,包括类似于Transfer Learning Toolkit,CuDNN,CuBlas, TesnorRT…
o NVIDIA GPU Cloud 介绍
o 成熟的解决方案或者案例
最近开始学习深度学习(Deep Learning)技术,特别是google的Tensorflow深度学习包开源后,深度学习已经成为大数据领域的重大计算革命,配合Teras顶层框架,使得Deep learning的学习成本降低。(百度也开源了飞桨开源平台也不错)
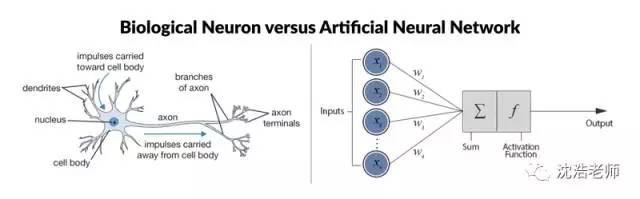
目前Deep learning技术应用越来越广,一切数据都是图,CNN卷积神经网络技术充满了神奇的计算魅力。DL技术广泛应用于:图像处理、人脸识别、自动驾驶、聊天机器人、AI人工智能、机器语言翻译、图片推荐系统、声音处理、音乐作曲、机器写作等领域。
现今,日益完善的深度学习技术和-AI-服务愈加受到市场青睐。与此同时,数据集不断扩大,计算模型和网络也变得越来越复杂,这对于硬件设备也提出了更为严苛的需求。如何利用有限的预算,最大限度升级系统整体的计算性能和数据传输能力成为了最为重要的问题。
由于,做深度学习,需要很多科学计算学习包。以及深度学习框架(tensorflow)
我这里选择的是下载Anaconda(集成环境。Anaconda installer archive https://repo.anaconda.com/archive/)。
推荐配置
如果您是高校学生或者高级研究人员,并且实验室或者个人资金充沛,建议您采用如下配置:
-
主板:X99型号或Z170型号
-
CPU: i7-5830K或i7-6700K 及其以上高级型号
-
内存:品牌内存,总容量32G以上,根据主板组成4通道或8通道
-
SSD: 品牌固态硬盘,容量256G以上
-
显卡:NVIDIA GTX 1080ti、NVIDIA GTX TITAN、NVIDIA GTX 1080、NVIDIA GTX 1070、NVIDIA GTX 1060 (顺序为优先建议,并且建议同一显卡,可以根据主板插槽数量购买多块,例如X99型号主板最多可以采用×4的显卡)
-
电源:由主机机容量的确定,一般有显卡总容量后再加200W即可
最低配置
如果您是仅仅用于自学或代码调试,亦或是条件所限仅采用自己现有的设备进行开发,那么您的电脑至少满足以下几点:
-
CPU:Intel第三代i5和i7以上系列产品或同性能AMD公司产品
-
内存:总容量4G以上
如果是先可以玩玩Keras文档说明中的几个案例,都有详细的代码和说明。
【经费充足的情况下另外也可以购买云厂商(BATH的几家)的专用GPU服务器,需要单独购买英伟达授权。】
Keras文档关于计算机的硬件配置说明- https://keras-cn.readthedocs.io/en/latest/for_beginners/keras_linux/
一般我们也可以将这台配置的GPU电脑作为服务器,通过设置SSH Key和SSH tunnel用平时的苹果电脑远程访问进行深度学习算法建模,通过模型训练后将模型save后,在不带GPU的电脑调用load模型或weights模型,进行预测和分类。
GPU ——Nvidia GTX 1080 Ti
GPU的重要性在于:
-
DL中的大多数计算是矩阵运算,如矩阵乘法。如果在CPU上完成,它们可能很慢。
-
由于我们在一个典型的神经网络中进行了数千次这样的操作,因此慢速度真的加起来就更慢了。
-
GPU相当方便地能够并行运行所有这些操作。它们有大量的内核,可以运行更多的线程。
-
GPU还具有更高的内存带宽,使其能够一次对一堆数据执行这些并行操作。

可选择的是Nvidia的几张牌:
GTX 1070($ 360),GTX 1080($ 500),GTX 1080 Ti(700美元),最后是Titan X(1320美元)。
在性能方面:GTX 1080 Ti和Titan X类似,大致来说,GTX 1080比GTX 1070快25%,而GTX 1080 Ti比GTX 1080快约30%。
以下是作者提到采购GPU时要考虑的事项:
-
制造商:好像目前没得选,只能是Nvidia英伟达出品。英伟达多年来一直专注于机器学习,支撑GPU运算的CUDA工具包根深蒂固,它是DL从业者的唯一选择。
-
预算:泰坦X在这方面的表现非常糟糕,因为它提供与1080 Ti相同的表现约500美元。
-
一个或多个:我考虑挑选一些1070s而不是1080或1080 Ti。这样可以让我在两张卡上训练一个模型,或者一次训练两个模型。目前在多卡上训练一个模型有点麻烦,尽管随着PyTorch和Caffe 2的改变,GPU的数量几乎是线性缩放。另一个选择 - 同时训练两个模型似乎有更多的价值,但我决定现在获得一个更强大的卡,并在之后增加一个。
-
GPU内存:更多内存更好。有更多的内存,我们可以部署更大的模型,并在训练期间使用足够大的批量(这有助于梯度流)。
-
内存带宽:这使得GPU能够在大量内存上运行。这是GPU的最重要的特征。
考虑到这一切,作者选择了GTX 1080 Ti,主要是为了提高训练速度。今后再添加第二个1080 Ti。
主板
在选择主板时,能够支持两个GTX 1080 Ti,包括PCI Express通道数(最小为2x8)和2个卡的物理尺寸。此外,请确保它与所选的CPU兼容。一个华硕TUF Z270为$ 130是选择。如果您拥有Intel Xeon CPU,MSI - X99A SLI PLUS应该会很好。
电源——750W
经验法则:它应该为CPU和GPU提供足够的电力,加上额外的100瓦特。
英特尔i5 7500处理器使用65W,GPU(1080 Ti)需要250W,75美元的价格获得了一个Deepcool 750W Gold PSU。这里的“Gold”是指功率效率,即消耗的功率是多少作为热量浪费。
软件设置
硬件到位后需要安装支撑深度学习的软件了。具体细节keras文档有描述。
安装Ubuntu
大多数DL框架被设计为首先在Linux上工作,也支持其他操作系统。在Ubuntu安装期间,默认选项一般都能正常工作,尽量先默认安装选项。选择了以前的版本(16.04)。
接下来安装:
-
支持GPU运算的深度学习驱动程序和深度学习软件包、
-
GPU driver — 操作系统支持GPU的驱动程序
-
CUDA — 支持GPU运行通用代码的驱动程序.
-
CuDNN —支持运行深度神经网络的算法程序
-
安装Python3.6 通过Anacoda4.2的安装方式推荐
-
安装Jupyter Notebook
-
安装numpy,scikit-learn,scikit-image,pandas,matplotlib等(一般都安装好了)
-
安装HDF5
-
安装Tensorflow
-
安装PyTorch
-
安装Theano(可选,按吧有些案例是用的)
-
安装Keras
-
其他包,随用随按吧
======以上就是个人学习推荐的选择步骤,以下就是企业级应用过程需要考量。======
GPU-的选择
熟悉深度学习的人都知道,深度学习是需要训练的,所谓的训练就是在成千上万个变量中寻找最佳值的计算。这需要通过不断的尝试识别,而最终获得的数值并非是人工确定的数字,而是一种常态的公式。通过这种像素级的学习,不断总结规律,计算机就可以实现像人一样思考。因而,更擅长并行计算和高带宽的-GPU,则成了大家关注的重点。
GPU-一个比较重要的优势就是他的内存结构。首先是共享内存。在-NVIDIA-披露的性能参数中,每个流处理器集群末端设有共享内存。相比于-CPU-每次操作数据都要返回内存再进行调用,GPU-线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存>>全局内存)。

而在传统的CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在-CPU-中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在-60GB/s-左右徘徊。与之相比,大显存带宽的-GPU-具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
另一方面,如果要充分利用-GPU-资源处理海量数据,需要不断向-GPU-注入大量数据。目前,PCIe-的数据传输速度还无法跟上这一速度,如果想避免此类“交通拥堵”,提高数据传输速度可以选择应用-NVlink-技术的--GPU-卡片。
NVLink-是目前最快的-GPU-高速互联技术,借助这种技术,GPU-和-CPU-彼此之间的数据交换速度要比使用PCIe 时快-5-到-12-倍,应用程序的运行速度可加快两倍。通过-NVLink 连接两个-GPU-可使其通信速度提高至-80-GB/s,比之前快了-5-倍。
其中-Nvidia-的-Volta-架构计算卡使用的-NVLink-2.0-技术速度更快(20-25Gbps),单通道可提供-50-GB/S-的显存带宽。

而且就目前而言,越来越多的深度学习标准库支持基于-GPU-的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据-GPU-所具有的线程/Core-数,去自动分配数据的处理策略,从而达到优化深度学习的时间。而这些软件上的全面支持也是其它计算结构所欠缺的。
简单来看,选择-GPU-有四个重要参数:浮点运算能力、显存、数据传输与价格。
对于很多科学计算而言,服务器性能主要决定于-GPU-的浮点运算能力。特别是对深度学习任务来说,单精浮点运算以及更低的半精浮点运算性能则更为重要。如果资金充足的情况下,可以选择应用-NVLink-技术单精计算性能高、显存大的-GPU-卡片。如果资金有限的话,则要仔细考量核心需求,选择性价比更高的-GPU-卡片。

内存大小的选择
心理学家告诉我们,专注力这种资源会随着时间的推移而逐渐耗尽。内存就是为数不多的,让你保存注意力资源,以解决更困难编程问题的硬件之一。与其在内存瓶颈上兜转,浪费时间,不如把注意力放在更加紧迫的问题上。如果你有更多的内存,有了这一前提条件,你可以避免那些瓶颈,节约时间,在更紧迫问题上投入更多的生产力。
所以,如果资金充足而且需要做很多预处理工作,应该选择至少和-GPU-内存大小相同的内存。虽然更小的内存也可以运行,但是这样就需要一步步转移数据,整体效率上则大打则扣。总的来说内存越大,工作起来越舒服。

强大的性能
R4220-8GX 是一款基于Intel® Xeon® 可扩展处理器的高性能计算平台,支持8个NVLINK GPU加速器和6TB的内存,单精度浮点计算224TFLOPS、双精度浮点计算112TFLOPS, 让用户体验强大的计算性能。
灵活的配置
为更加贴切的满足各种应用需求,客户可根据需求选择支持16个2.5寸SATA/SAS硬盘,网络选择多样化,可选择支持双千兆、四千兆、双千兆+双万兆搭配,所有网络支持管理复用,满足各种不同的网络应用场景。
优化的散热
整机结构布局充分考虑优化散热和节约功耗,支持高温环境。关键部件根据发热量采用特殊设计,在保持性能的同时可以降低风扇转速,从而减低功耗和噪音。
合理的扩展
在支持4-8块NVLINK的同时,还可有1个PCI-E插槽可用,可扩展100Gb infiniband HCA、Nvme SSD等、具有非常好的灵活性和兼容性。
便捷的管理
具备IPMI 远程管理功能,实现非现场即可监控管理服务器要求,具有监控系统各部件的运行状况、远程安装操作系统、故障报警等功能。极大的缩减了维护开销。
也可以企业采购浪潮等公司的GPU一体化方案服务器来实施部署学习训练应用,从而使得数据私有化和安全化。
结合实例介绍使用TensorFlow开发机器学习应用的详细方法和步骤,着重讲解了用于图像识别的卷积神经网络和用于自然语言处理的循环神经网络的理论知识及其TensorFlow实现方法,并结合实际场景和例子描述了深度学习技术的应用范围与效果。