hive中简单的表格数据清洗操作(实例+图解+代码 一看就懂 一做就废)
数据清洗
- 创建项目
- 1、第一步导入json
- 2、上传csv表格至hdfs
- 3、创建hdfs文件夹
- 4、上传表格
- 5、清理库
- 6、修改interpreter
- 7、创建原始数据表并且上传csv文件
- 数据问题分析.
- 表格处理
- 问题1:8001-8100数据的有重复
- 问题2:过滤掉store_review中没有评分的数据
- 问题3:credit_no的加密
- 问题4:transaction数据按照日期YYYY-MM做分区
创建项目
在清洗之前先介绍环境:hive 、beeline、Zeppelin 同时所需的文件在下面的链接中,我祝你心情好:
链接:https://pan.baidu.com/s/123qr-BuTa7nxLxd1LXvH8A 提取码:cz12
1、第一步导入json
按照下图操作:

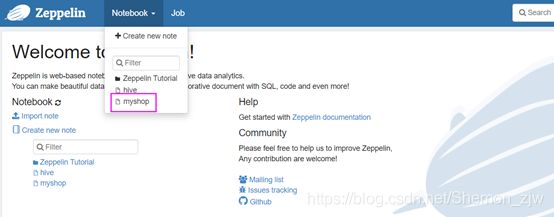
如图在Zeppelin的note中已经添加了项目json
2、上传csv表格至hdfs
先将文件上传到linux中然后下指令上传至hdfs:

3、创建hdfs文件夹

# hdfs dfs -mkdir -p /tmp/shopping/data/customer
# hdfs dfs -mkdir -p /tmp/shopping/data/transaction
# hdfs dfs -mkdir -p /tmp/shopping/data/store
hdfs dfs -mkdir -p /tmp/shopping/data/review
一句一句执行。
4、上传表格

hdfs dfs -put /opt/shop/customer_details.csv /tmp/shopping/data/customer
hdfs dfs -put /opt/shop/transaction_details.csv /tmp/shopping/data/transaction
hdfs dfs -put /opt/shop/store_details.csv /tmp/shopping/data/store
hdfs dfs -put /opt/shop/store_review.csv /tmp/shopping/data/review
可一次性执行
5、清理库

%hive
drop database if exists shopping cascade
%hive
create database shopping
6、修改interpreter
此为Zeppelin的一个缺点 在创建库之后需要修改url 否则创建的所有表都会在default的库中。
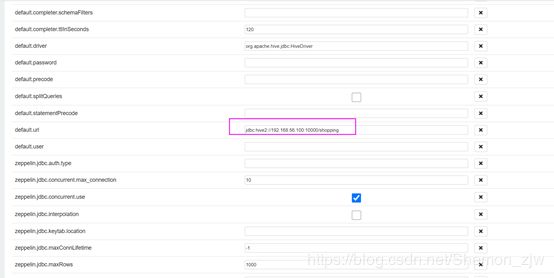
在url地址后添加创建的库shopping,之后才会真正的进入shopping库中创建表格。
7、创建原始数据表并且上传csv文件
建表:
%hive
create external table if not exists ext_customer_details(
customer_id string,
first_name string,
last_name string,
email string,
gender string,
address string,
country string,
language string,
job string,
credit_type string,
credit_no string
)
row format delimited fields terminated by ','
location '/tmp/shopping/data/customer'
上传:
%hive
load data inpath '/tmp/shopping/data/customer/customer_details.csv' overwrite into table ext_customer_details
简单查询
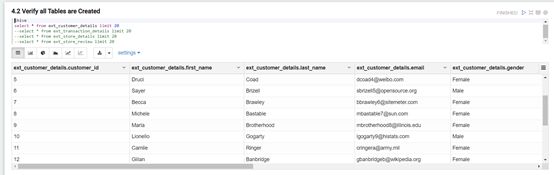
将另外的三个表并且分别上传数据
%hive
create external table if not exists ext_transaction_details(
transaction_id string,
customer_id string,
store_id string,
price string,
product string,
`date` string,
time string
)
row format delimited fields terminated by ','
stored as textfile tblproperties("skip,header.line.count"="1")
%hive
create external table if not exists ext_store_details(
store_id string,
store_name string,
employee_number int
)
row format delimited fields terminated by ','
stored as textfile tblproperties("skip.header.line.count"="1")
%hive
create external table if not exists ext_store_review(
transaction_id string,
store_id string,
review_score string
)
row format delimited fields terminated by ','
stored as textfile tblproperties("skip,header.line.count"="1")
上传:
%hive
-- load data inpath '/tmp/shopping/data/transaction/transaction_details.csv' overwrite into table ext_transaction_details
-- load data inpath '/tmp/shopping/data/store/store_details.csv' overwrite into table ext_store_details
load data inpath '/tmp/shopping/data/review/store_review.csv' overwrite into table ext_store_review
分别查询表是否有数据
%hive
select * from ext_transaction_details limit 20
--select * from ext_transaction_details limit 20
--select * from ext_store_details limit 20
--select * from ext_store_review limit 20

数据问题分析.
在开始之前先简单分析数据的问题,
- 解决以下有问题的数据
- 对transaction_details中的重复数据生成新ID
- 过滤掉store_review中没有评分的数据
- 可以把清洗好的数据放到另一个表或者用View表示
- 找出PII (personal information identification) 或PCI (personal confidential information) 数据进行加密或hash
- 重新组织transaction数据按照日期YYYY-MM做分区
表格处理
对于transaction_details表格需要进行如下处理:
- 对transaction_details中的重复数据生成新ID
- 过滤掉store_review中没有评分的数据
- 通过Zepplin实现交易数据按月分区
首先先创建一个新表存储清洗后的数据:
%hive
create table if not exists transaction_details(
transaction_id string,
customer_id string,
store_id string,
price string,
product string,
`date` string,
time string
)
partitioned by (year int,month int)
row format delimited fields terminated by ','
stored as textfile
问题1:8001-8100数据的有重复
解决方案: 先用窗口函数排序 然后将id+(排序号-1)*10000
代码实现:
with
t1 as (select *,row_number() over(partition by transaction_id) as sq from ext_transaction_details where transaction_id>8000)
select (sq-1)*10000+transaction_id as transaction_id,
customer_id,
store_id,
price,
product,
date,
time,
year(date) as year,
month(date) as month
from t1
但是在实现过程中发现数据的分割出现了问题 如图

解决方案:见我的博客csv处理。
重新建表清洗之后:

问题2:过滤掉store_review中没有评分的数据
解决方案:清理无用数据并把数据重新导入至新表
代码实现:
首先创建新表以接收数据清洗之后的数据:
建表
create table store_review
%hive
create table if not exists store_review(
transaction_id string,
store_id string,
review_score string
)
row format delimited fields terminated by ','
stored as textfile
清理无用数据:
思路:
select * from ext_store_review s where
exists (select * from ext_transaction_details t where cast(s.transaction_id as int)=cast(t.transaction_id as int) and cast(s.store_id as int)=cast(t.store_id as int)) and s.review_score !=""
如图就将所需的有评论并且id对应双表都有的数据筛选出来的

在写hql语句时候,并不止一个写法,但是第一个写法是优化的:
select * from (select * from ext_store_review s where exists(select * from ext_transaction_details t where s.transaction_id=t.transaction_id )) as a where a.review_score >0
接下来将数据导入:
insert overwrite table store_review select * from ext_store_review s where
exists
(select * from ext_transaction_details t where cast(s.transaction_id as int)=cast(t.transaction_id as int)
and
cast(s.store_id as int)=cast(t.store_id as int)) and s.review_score !=""
问题3:credit_no的加密
解决方案:md5单向加密,当然有需求的话可以采用双向的base64式双向加密解密法.
代码实现
%hive
create table if not exists customer_details as
select customer_id,first_name,last_name,email,gender,address,country,job,credit_type,md5(credit_no) credit_no from ext_customer_details
问题4:transaction数据按照日期YYYY-MM做分区
解决方案 开启分区 并且按照年月分区
代码实现
set hive.exec.dynamic.partition=true //开启动态分区
insert overwrite table transaction_details partition(year,month)
select (sq-1)*10000+transaction_id as transaction_id,
customer_id,
store_id,
price,
product,
date,
time,
year(date) as year,
month(date) as month from (select *,row_number() over(partition by transaction_id) as sq from ext_transaction_details ) t1