在关于报表生成的领域,在不使用jcaob等插件的时候,纯粹使用java来做生成报表的工作,大多数时候非常的不好用或者说只能完成某一个方面的工作。
我比较了一下几个纯java的报表处理工具
poi:比较老的方案了,现在来说还是比较好用的,但是没有找到它可以替换表格和图片的功能。它只能在文档的最后添加表格或者图片。也就是说它可以用程序生成一个比较完善的报告(需要在程序里设定格式,复杂的话会有些麻烦),但是不支持模板,至少是支持有限。
itext:和poi有些类似不过它更加趋向于pdf,但是新版本itextpdf5取消了对rtf格式的支持,所以不能转成word格式了。
freemaker:使用word2003可以直接把模板转换成xml格式,通过对xml的修改,可以直接生成word;问题是word的本质上依旧是xml,而且不符合一些格式要求;如果仅仅是生成word的话倒是可以考虑。因为对复杂格式的word支持都比较好。
推荐的是docx4j,基本上都很好了。
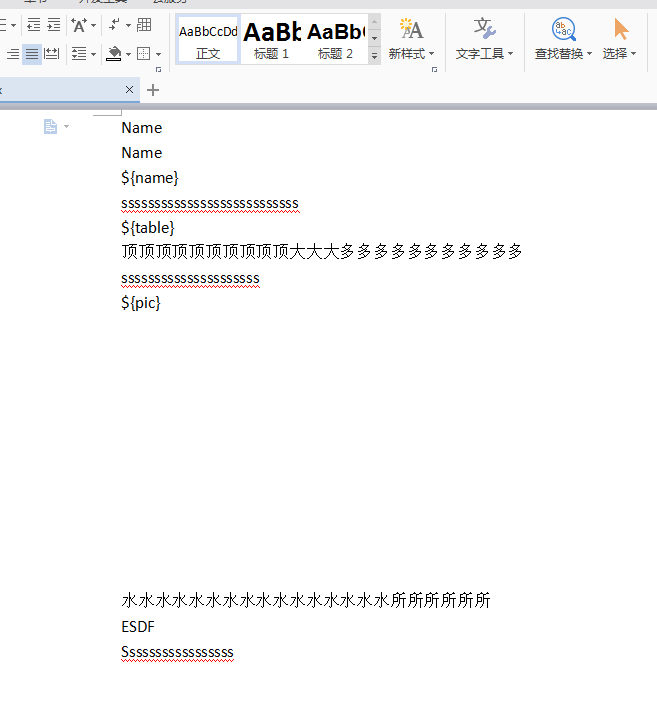
这是我谁便写的模板,这里有5个测试的东西:
1.替换文字 2.替换变量为表格 3.替换变量为图片 4.中文支持 5.转换为pdf
第一步的替换文字,在它给出的方法中,我们可以直接替换
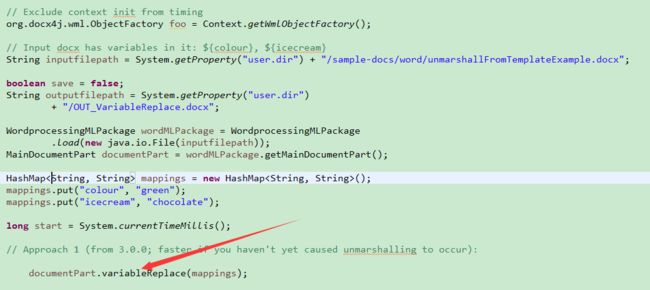
variableReplace方法,在例子中可以找到详细的用法
https://github.com/plutext/docx4j/blob/master/src/samples/docx4j/org/docx4j/samples/VariableReplace.java
第二步,替换表格
根据以前大佬的一些代码,我找到了一个比较好的方案
我们知道word的格式其实可以用xml来表现,而docx4j也应该是基于xml来操作docx文档的
观察表格的格式

tb表格是和p段落一级的
当我们把变量独自写在一行是,他就会独自占用一个p标签,把这个p内容全部换掉,我们就实现了替换表格的目的;
首先是找到p
http://blog.csdn.net/sishenkankan/article/details/53107195
里面有个方法
/**
* 遍历所有的Text,或者Table,或者R或者P等等
*
* @param obj
* @param toSearch
* @return
*/
private static List它可以返回所有的Text,R,P中一种标签的所有元素(element),我这里是调用查询关键词${table}
可以找到他的父亲R,然后又可以找到R的父亲P,P的父亲不确定,可能是Body可能是Document,所以设置P的父亲ContentAccessor;
doc.getContent().set(doc.getContent().indexOf(p), table);
getContent(),可以找到它的所有儿子,list格式;
set,给list赋值;
doc.getContent().indexOf(p),找到当前p的index;
替换之,完成表格的替换了;
/**
* 把关键词替换成表格
* 注意:关键词最好是单独占用一行
* 需要测试合格后再把模板投入使用
* @param mlPackage
* @param replace
* @param list
*/
public static void replaceTable(WordprocessingMLPackage mlPackage, String replace, List list) {
List
然后是替换图片:和替换表格类似,也是找到变量的位置
然后生成一个r,r里面包含了图片,把变量的r替换成图片的r
public static org.docx4j.wml.R newImage( WordprocessingMLPackage wordMLPackage,
byte[] bytes,
String filenameHint, String altText) throws Exception {
int id1=(int) ((Math.random()*1000)*(Math.random()*1000));
int id2=(int) ((Math.random()*1000)*(Math.random()*1000));
// BinaryPartAbstractImage imagePart = BinaryPartAbstractImage.createImagePart(wordMLPackage, new File(file));
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage.createImagePart(wordMLPackage, bytes);
Inline inline = imagePart.createImageInline( filenameHint, altText,
id1, id2, false);
// Now add the inline in w:p/w:r/w:drawing
org.docx4j.wml.ObjectFactory factory = Context.getWmlObjectFactory();
org.docx4j.wml.R run = factory.createR();
org.docx4j.wml.Drawing drawing = factory.createDrawing();
run.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
bytes=null;
imagePart=null;
return run;
}https://github.com/plutext/docx4j/blob/master/src/samples/docx4j/org/docx4j/samples/ImageAdd.java
具体是这样做得
public static void replaceImage(WordprocessingMLPackage wordMLPackage,
String replace,
byte[] bytes,
String filenameHint, String altText) throws Exception{
List完成。我们完整的替换了模板里面的文字,图片和表格了;
生成表格和图片的以及格式之类的,你们可以去自己研究。
下一步,转换成pdf:
直接用一个方法就基本上ok了
Docx4J.toPDF(mlPackage, new java.io.FileOutputStream("D:/iText/test/1.pdf"));https://github.com/plutext/docx4j/blob/master/src/samples/docx4j/org/docx4j/samples/ConvertOutPDF.java
,但是需要注意的是,转换pdf的资源占用稍微有点高,速度也会因为批量转换的数量越多越慢,有内存溢出的风险;
经过测试,中文也是完美支持的