28_多易教育之《yiee数据运营系统》附录:扩展知识点汇总系列一
目录
一、日志工具log4j
二、高德地图服务
1、导论
2、高德地图服务申请
3、高德地图服务API
三、HanLP中文分词
四、hive多重插入语法
五、hive动态分区
一、日志工具log4j
log4j是一个java系统中用于输出日志信息的工具
log4j可以将日志定义成多种级别:ERROR / WARN / INFO / DEBUG
log4j通过获取到一个logger对象来输出日志:
val logger = Logger.getLogger(“logger名称”);
logger.info(“日志内容”)
所拿到的这些logger对象之间是有“父子”关系的
所有logger都是rootLogger的子!
“org.apache” 这个名字的logger是 "org"这个名字的logger的子!
log4j的日志输出格式和目的地,都是可以通过参数配置的;
目的地的控制用Appender输出组件
常用的Appender组件:
log4j.appender.xx=org.apache.log4j.ConsoleAppender
log4j.appender.rollingFile=org.apache.log4j.RollingFileAppender
格式的控制用LayOut布局组件
常用的LayOut组件:
og4j.appender.xx.layout=org.apache.log4j.PatternLayout
log4j.appender.xx.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n
# 完整配置文件示例:
# 定义一个根logger
log4j.rootLogger=DEBUG,xx
log4j.appender.xx=org.apache.log4j.ConsoleAppender
log4j.appender.xx.Threshold=DEBUG
log4j.appender.xx.ImmediateFlush=true
log4j.appender.xx.Target=System.out
log4j.appender.xx.layout=org.apache.log4j.PatternLayout
log4j.appender.xx.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n
# 定义一个子logger,名字叫abc
log4j.logger.abc = INFO
# 定义一个子logger,名字叫roll
log4j.logger.roll = INFO,rollingFile
log4j.additivity.roll=false
log4j.appender.rollingFile=org.apache.log4j.RollingFileAppender
log4j.appender.rollingFile.Threshold=DEBUG
log4j.appender.rollingFile.ImmediateFlush=true
log4j.appender.rollingFile.Append=true
log4j.appender.rollingFile.File=g:/logs/2019-10-29/doit.mall.access.log
log4j.appender.rollingFile.MaxFileSize=120MB
log4j.appender.rollingFile.MaxBackupIndex=50
log4j.appender.rollingFile.layout=org.apache.log4j.PatternLayout
log4j.appender.rollingFile.layout.ConversionPattern=%m%n
二、高德地图服务
补充需求:
如果某条日志中的gps地理位置无法从公司内部字典中匹配信息,则将这些gps坐标,输出到一个专门的文件中;
1、导论
由于公司自己的地理位置知识库是不完备的,每日的流量数据预处理中,有一些gps坐标是解析不出地理位置信息的;
我们可以将这些解析不出来的gps坐标,单独过滤出来,然后通过请求高德地图服务来解析,并将解析结果追加到我们的地理位置知识库中,知识库就可以日益充实和完善!
高德地图,提供各类地理位置处理功能的web服务接口!
我们的流量数据中,有一些gps坐标无法从公司内部的地理位置字典中查询到位置信息,就可以把这些gps拿去请求高德的web服务,获取地理位置信息,并丰富公司内部的地理位置知识字典!
2、高德地图服务申请
高德开发者开放平台网址webAPI:
- https://lbs.amap.com/
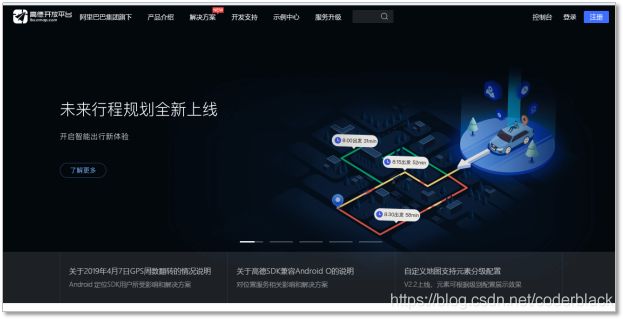
开发者接口文档入口:选Web服务API
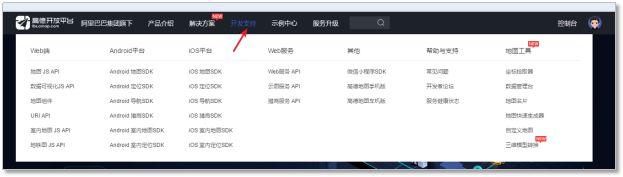
申请应用Key
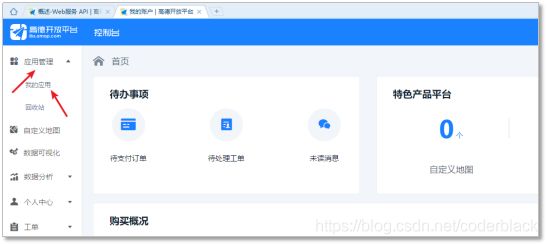
从控制台,新建应用
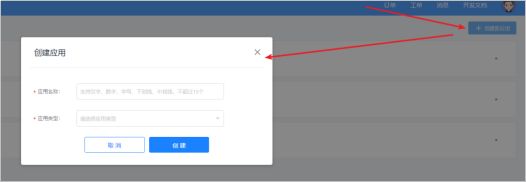
添加key给应用

3、高德地图服务API
API文档地址:
- https://lbs.amap.com/api/webservice/summary/
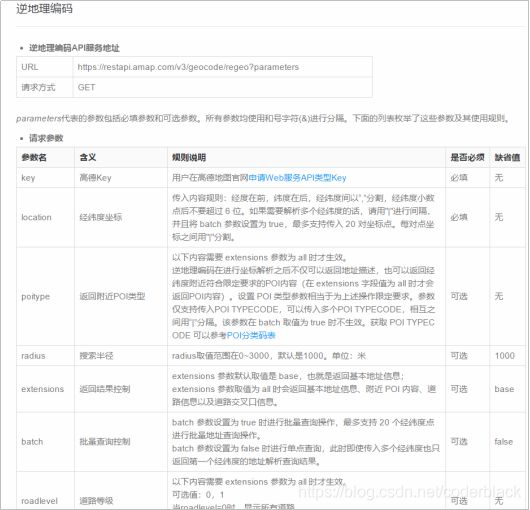
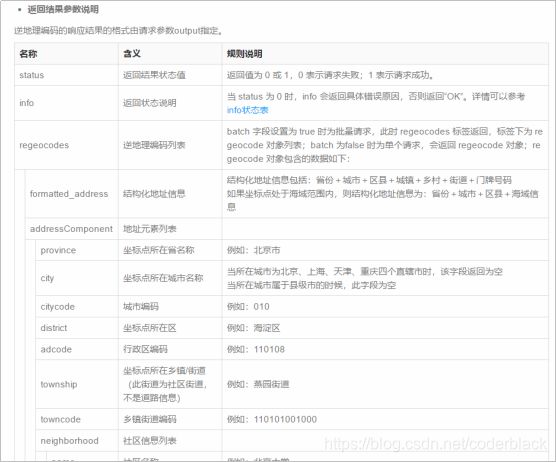
返回结果解析说明
{
"status": "1",
"regeocode": {
"addressComponent": {
"city": [],
"province": "北京市",
"adcode": "110105",
"district": "朝阳区",
"towncode": "110105026000",
"streetNumber": {
"number": "6号",
"location": "116.481977,39.9900489",
"direction": "东南",
"distance": "62.165",
"street": "阜通东大街"
},
"country": "中国",
"township": "望京街道",
"businessAreas": [
{
"location": "116.470293,39.996171",
"name": "望京",
"id": "110105"
},
{
"location": "116.494356,39.971563",
"name": "酒仙桥",
"id": "110105"
},
{
"location": "116.492891,39.981321",
"name": "大山子",
"id": "110105"
}
],
"building": {
"name": "方恒国际中心B座",
"type": "商务住宅;楼宇;商务写字楼"
},
"neighborhood": {
"name": "方恒国际中心",
"type": "商务住宅;楼宇;商住两用楼宇"
},
"citycode": "010"
},
"formatted_address": "北京市朝阳区望京街道方恒国际中心B座方恒国际中心"
},
"info": "OK",
"infocode": "10000"
}
高德API请求demo
object GaodeLBSDemo {
def main(args: Array[String]): Unit = {
import scala.collection.JavaConversions._
// 构造一个http客户端
val client = HttpClientBuilder.create().build()
// 构造也给get协议请求
val get = new HttpGet("https://restapi.amap.com/v3/geocode/regeo?key=66f3031018c358750fa6295eb576e718&location=116.481488,39.990464")
// 用客户端去执行请求
val response = client.execute(get)
val entity = response.getEntity
val in = entity.getContent
val lines: util.List[_] = IOUtils.readLines(in)
// 后续 TODO 解析响应回来的json,取出省、市、区、街道、商圈
}
}
三、HanLP中文分词
HanLP是由一系列模型与算法组成的工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点;提供词法分析(中文分词、词性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
HanLP已经被广泛用于Lucene、Solr、ElasticSearch、Hadoop、Android、Resin等平台,有大量开源作者开发各种插件与拓展,并且被包装或移植到Python、C#、R、JavaScript等语言上去。详见项目主页。
英文的词,是有空格或标点来天然分隔的,很容易实现分词
中文分词,由于中文的语言特点,词和词之间是没有天然分隔的。要想正确分词,需要一些复杂的算法和一些辅助的词典!
比如有一种非常简单的分词算法,就是2字分词法(CJKAnalyzer工具包):
“我有一头小毛驴我从来也不骑”
=>:我有 有一 一头 头小 小毛 毛驴 驴我 我从 从来
真正在实践中能拿来作为分词工具的有:
庖丁分词
IKAnalyzser
HanLP – 是一个高级的NLP(自然语言处理)工具套件
HanLp自然语言处理包的使用示例:
导入依赖:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.1</version>
</dependency>
分词api调用:
val terms: util.List[Term] = HanLP.segment("我有一头小毛驴我从来也不骑,有一天我心血来潮骑着去赶集")
println(terms.map(t => t.word).filter(_.size>1))
四、hive多重插入语法
从一个表中,写多种查询逻辑,并将结果输出到多个不同表(分区)
语法:
from t_x
insert into t_dest partition(p=’p1’)
select …… where …….
insert into t_dest partition(p=’p2’)
select …… where …….
五、hive动态分区
指定一个目标分区时,不用写死,而是用查询出来的某个字段的值作为分区值
注意,有一个分区严格模式开关:关闭严格模式!
set hive.exec.dynamic.partition.mode=nonstrict
insert into table t_x partition(dt)
select id,name,dt from t_y;
注意,动态分区字段应该作为select中最后一个字段