MapReduce中,从HDFS读取数据计算后写入HBase
基于上个例子。做一下简单的改造。
http://blog.csdn.net/demonxyy/article/details/79320628
在原本的例子中,从HDFS中读取数据计算之后再写会HDFS里,现在讲Reducer类改造一下,把计算后的数据。写入到HBase当中,写完之后我们会使用HBase的命令查询一下写入数据。
打开原有的Reducer类,代码如下:
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapred.OutputCollector
import org.apache.hadoop.mapred.Reporter
import org.apache.hadoop.mapreduce.Reducer
class TempReducer : Reducer() {
override fun reduce(key: Text?, values: Iterable?, context: Context?) {
var maxValue : Int = Int.MIN_VALUE
var sb : StringBuffer = StringBuffer()
//取values的最大值
if (values != null) {
for (value in values) {
maxValue = Math.max(maxValue, value.get())
sb.append(value).append(", ")
}
}
print("Before Reduce:" + key + ", " + sb.toString())
if (context != null) {
context.write(key, IntWritable(maxValue))
}
print("After Reduce:" + key + ", " + maxValue)
}
} 现在将代码改成如下:
import org.apache.hadoop.hbase.mapreduce.TableReducer
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.util.Bytes
//把原本继承Reducer改成继承TableReducer
class TempReducer : TableReducer() {
override fun reduce(key: Text?, values: Iterable?, context: Context?) {
var maxValue : Int = Int.MIN_VALUE
var sb : StringBuffer = StringBuffer()
//取values的最大值
if (values != null) {
for (value in values) {
maxValue = Math.max(maxValue, value.get())
sb.append(value).append(", ")
}
}
print("Before Reduce:" + key + ", " + sb.toString())
if (context != null) {
val put = Put(Bytes.toBytes(key.toString()))
//一个数据存进一行,列族为content,列为count,列值为数目
put.add(Bytes.toBytes("content"), Bytes.toBytes("count"),
Bytes.toBytes(maxValue.toString()))
context.write(key, put)
}
print("After Reduce:" + key + ", " + maxValue)
}
} 将继承类改变一下,使Reducer类继承TableReducer,对应的KV也跟着修改下。然后原本write的地方跟着实例代码改变一下。
接着改变Main类,原有的Main类代码如下:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
fun resource(name: String) = TempMain::class.java.getResource(name)
object TempMain{
fun run (input : String?, outPut : String?) {
var hadoopConfig : Configuration = Configuration()
hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem::class.java.name)
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem::class.java.name)
//Hadoop的配置文件
hadoopConfig.addResource(resource("/hdfs-conf/core-site.xml"))
hadoopConfig.addResource(resource("/hdfs-conf/hdfs-site.xml"))
var job : Job = Job(hadoopConfig)
//如果需要打成jar运行,需要下面这句
job.setJarByClass(TempMain::class.java)
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, Path(input))
FileOutputFormat.setOutputPath(job, Path(outPut))
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.mapperClass = TempMapper::class.java
job.reducerClass = TempReducer::class.java
//设置最后输出结果的Key和Value的类型
job.outputKeyClass = Text::class.java
job.outputValueClass = IntWritable::class.java
//执行job,直到完成
job.waitForCompletion(true)
print("Finished")
}
}
fun main(args: Array) {
//输入路径 这边的IP是Hadoop的Master地址
val dst = "hdfs://172.16.134.251:9000/test/input.txt"
//输出路径
val dstOut = "hdfs://172.16.134.251:9000/test/output3"
TempMain.run(dst, dstOut)
} 其中。改后的所有代码如下:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.HColumnDescriptor
import org.apache.hadoop.hbase.HTableDescriptor
import org.apache.hadoop.hbase.client.HBaseAdmin
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import java.io.IOException
fun resource(name: String) = TempMain::class.java.getResource(name)
object TempMain{
fun run (input : String?, outPut : String?) {
var hadoopConfig : Configuration = Configuration()
hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem::class.java.name)
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem::class.java.name)
hadoopConfig.addResource(resource("/hdfs-conf/core-site.xml"))
hadoopConfig.addResource(resource("/hdfs-conf/hdfs-site.xml"))
val tableName = "TempResult"
hadoopConfig.set(TableOutputFormat.OUTPUT_TABLE, tableName)
val conf = HBaseConfiguration.create()
TempMain.createHBaseTable(tableName)
var job : Job = Job(hadoopConfig, "TempResult table ")
//如果需要打成jar运行,需要下面这句
job.setJarByClass(TempMain::class.java)
job.setNumReduceTasks(3);
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.mapperClass = TempMapper::class.java
job.reducerClass = TempReducer::class.java
//指定输出的键值类型
job.mapOutputKeyClass = Text::class.java
job.mapOutputValueClass = IntWritable::class.java
//指定格式化输入的类型
job.inputFormatClass = TextInputFormat::class.java
//指定格式化出入的类型
job.outputFormatClass = TableOutputFormat::class.java
//设置最后输出结果的Key和Value的类型
// job.outputKeyClass = Text::class.java
// job.outputValueClass = IntWritable::class.java
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, Path(input))
//结果已写入HBase中,注释掉一下代码
// FileOutputFormat.setOutputPath(job, Path(outPut))
//执行job,直到完成
job.waitForCompletion(true)
print("Finished")
}
@Throws(IOException::class)
fun createHBaseTable(tableName: String) {
val htd = HTableDescriptor(tableName)
val col = HColumnDescriptor("content")
htd.addFamily(col)
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "172.16.134.251,172.16.134.250,172.16.134.249,172.16.134.252")
val admin = HBaseAdmin(conf)
if (admin.tableExists(tableName)) {
println("该表已存在!请重新新建其他表...")
admin.disableTable(tableName)
admin.deleteTable(tableName)
}
println("create new table:" + tableName)
admin.createTable(htd)
}
}
fun main(args: Array) {
//输入路径
val dst = "hdfs://172.16.134.251:9000/test/input.txt"
//输出路径
val dstOut = "hdfs://172.16.134.251:9000/test/output4"
TempMain.run(dst, dstOut)
} 同样根据之前的例子打包,然后传到Hadoop服务器,解压后运行程序,一下为日志:
[root@Master bin]# ./mapdemo
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/runfile/mapdemo-1.0-SNAPSHOT/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/runfile/mapdemo-1.0-SNAPSHOT/lib/mapdemo-1.0-SNAPSHOT.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
create new table:T_Temp_Result
Before Mapper:0, 2014010114After Mapper:2014, 14
Before Mapper:11, 2014010216After Mapper:2014, 16
Before Mapper:22, 2014010317After Mapper:2014, 17
Before Mapper:33, 2014010410After Mapper:2014, 10
Before Mapper:44, 2014010506After Mapper:2014, 6
Before Mapper:55, 2012010609After Mapper:2012, 9
Before Mapper:66, 2012010732After Mapper:2012, 32
Before Mapper:77, 2012010812After Mapper:2012, 12
Before Mapper:88, 2012010919After Mapper:2012, 19
Before Mapper:99, 2012011023After Mapper:2012, 23
Before Mapper:110, 2001010116After Mapper:2001, 16
Before Mapper:121, 2001010212After Mapper:2001, 12
Before Mapper:132, 2001010310After Mapper:2001, 10
Before Mapper:143, 2001010411After Mapper:2001, 11
Before Mapper:154, 2001010529After Mapper:2001, 29
Before Mapper:165, 2013010619After Mapper:2013, 19
Before Mapper:176, 2013010722After Mapper:2013, 22
Before Mapper:187, 2013010812After Mapper:2013, 12
Before Mapper:198, 2013010929After Mapper:2013, 29
Before Mapper:209, 2013011023After Mapper:2013, 23
Before Mapper:220, 2008010105After Mapper:2008, 5
Before Mapper:231, 2008010216After Mapper:2008, 16
Before Mapper:242, 2008010337After Mapper:2008, 37
Before Mapper:253, 2008010414After Mapper:2008, 14
Before Mapper:264, 2008010516After Mapper:2008, 16
Before Mapper:275, 2007010619After Mapper:2007, 19
Before Mapper:286, 2007010712After Mapper:2007, 12
Before Mapper:297, 2007010812After Mapper:2007, 12
Before Mapper:308, 2007010999After Mapper:2007, 99
Before Mapper:319, 2007011023After Mapper:2007, 23
Before Mapper:330, 2010010114After Mapper:2010, 14
Before Mapper:341, 2010010216After Mapper:2010, 16
Before Mapper:352, 2010010317After Mapper:2010, 17
Before Mapper:363, 2010010410After Mapper:2010, 10
Before Mapper:374, 2010010506After Mapper:2010, 6
Before Mapper:385, 2015010649After Mapper:2015, 49
Before Mapper:396, 2015010722After Mapper:2015, 22
Before Mapper:407, 2015010812After Mapper:2015, 12
Before Mapper:418, 2015010999After Mapper:2015, 99
Before Mapper:429, 2015011023After Mapper:2015, 23
Before Reduce:2012, 19, 12, 32, 9, 23,
After Reduce:2012, 32
Before Reduce:2015, 49, 22, 12, 99, 23,
After Reduce:2015, 99
Before Reduce:2001, 29, 11, 10, 12, 16,
After Reduce:2001, 29
Before Reduce:2007, 19, 12, 99, 23, 12,
After Reduce:2007, 99
Before Reduce:2010, 14, 16, 17, 10, 6,
After Reduce:2010, 17
Before Reduce:2013, 23, 29, 12, 22, 19,
After Reduce:2013, 29
Before Reduce:2008, 5, 16, 37, 14, 16,
After Reduce:2008, 37
Before Reduce:2014, 6, 10, 17, 16, 14,
After Reduce:2014, 17
Finished在服务器中。使用以下命令打开HBase的命令行:
hbase shell
使用命令:
scan TempResult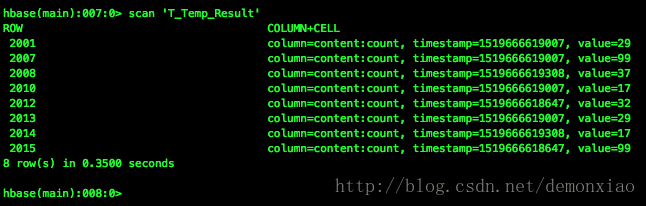
可以查看到我们原本写在hdfs中的结果已经存入到了HBase当中了。
以上