Quartz框架(一)—Quartz的基本配置
Quartz框架(二)—jobstore数据库表字段详解
Quartz框架(三)—任务的并行/串行执行
Quartz框架(四)—misfire处理机制
Quartz框架(五)— 有状态的job和无状态job
Quartz框架(六)— Trigger状态转换
Quartz框架(七)— Quartz集群原理
Quartz框架(八)— Quartz实现异步通知
Quartz框架(九)— 动态操作Quartz定时任务
Quartz框架(十)监听
1. Quartz集群
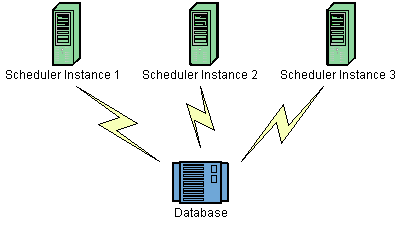
Quartz急群众每个节点是一个独立的Quartz任务应用,它又管理者其他节点。该集群需要分别对每个节点分别启动或停止,独立的Quartz节点并不与另一个节点或是管理节点通信。Quartz应用是通过共有相同数据库表来感知到另一应用。也就是说只有使用持久化JobStore存储Job和Trigger才能完成Quartz集群。
Quartz的集群部署方案是分布式的,没有负责集中管理的节点,而是利用数据库杭锁的方式来实现集群环境下的并发控制。
一个scheduler实例在集群模式下首先获取{0}LOCKS表中的行锁;
向Mysql获取杭锁的语句:
select * from {0}LOCKS where sched_name = ? and lock_name = ? for update
{0}会替换为配置文件默认配置的QRTZ_。sched_name为应用集群的实例名,lock_name就是行级锁名。Quartz主要由两个行级锁。
| lock_name | desc |
|---|---|
| STATE_ACCESS | 状态访问锁 |
| TRIGGER_ACCESS | 触发器访问锁 |
Quartz集群争用触发器行锁,锁被占用只能等待,获取触发器行锁之后,先获取需要等待触发的其他触发器信息。数据库更新触发器状态信息,及时是否触发器行锁,供其他调度实例获取,然后在进行触发器任务调度操作,对数据库操作就要先获取行锁。
#集群中应用采用相同的Scheduler实例
org.quartz.scheduler.instanceName: wenqyScheduler
#集群节点的ID必须唯一,可由quartz自动生成
org.quartz.scheduler.instanceId: AUTO
#通知Scheduler实例要它参与到一个集群当中
org.quartz.jobStore.isClustered: true
#需持久化存储
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#数据源
org.quartz.jobStore.dataSource=myDS
#quartz表前缀
org.quartz.jobStore.tablePrefix=QRTZ_
#数据源配置
org.quartz.dataSource.myDS.driver: com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL: jdbc:mysql://localhost:3306/ncdb
org.quartz.dataSource.myDS.user: root
org.quartz.dataSource.myDS.password: 123456
org.quartz.dataSource.myDS.maxConnections: 5
org.quartz.dataSource.myDS.validationQuery: select 0
同一集群下,instanceName必须相同,instanceId可自动生成,isClustered为true,持久化存储,指定数据库类型对应的驱动类和数据源连接。
2. 集群故障转移
每个服务器会定时(org.quartz.jobStore.clusterCheckinInterval这个时间)更新SCHEDULER_STATE表中的LAST_CHECK_TIME(将服务器的当前时刻更新为最后更新时刻)字段,遍历集群各兄弟节点的实例状态,检测集群各个兄弟节点的健康状态。
2.1 如何检测故障节点
当集群的一个节点的Scheduler实例执行CHECKIN时,他会查看是否有其他节点Scheduler实例在到达他们预期的时间还未CHECKIN,则认为该节点故障。
LAST_CHECK_TIME+CHECKIN_INTERVAL源码请参考org.quartz.impl.jdbcjobstore.JobStoreSupport下的
/**
* Get a list of all scheduler instances in the cluster that may have failed.
* This includes this scheduler if it is checking in for the first time.
*/
protected List findFailedInstances(Connection conn)
throws JobPersistenceException {
// find failed instances...
if (calcFailedIfAfter(rec) < timeNow) {
}
protected long calcFailedIfAfter(SchedulerStateRecord rec) {
return rec.getCheckinTimestamp() +
Math.max(rec.getCheckinInterval(),
(System.currentTimeMillis() - lastCheckin)) +
7500L;
}
那么则认为该节点故障。
2.2 如何处理故障节点
集群管理线程检测到故障节点,就会更新触发器的状态,状态更新如下:
| 故障节点触发器更新前状态 | 更新后状态 |
|---|---|
| BLOCK | WAITING |
| PAUSED_BLOCK | PAUSED |
| ACQUIRED | WAITING |
| COMPLETE | 无,删除Trigger |
需要注意的是:若qrtz_fired_triggers不是ACQUIRED状态,而是执行状态,且jobRequestRecovery=true:
- 创建一个SimpleTrigger,存储到triggers表中;
- status=waiting,MISFIRE_INSTR=MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY。
然后删除firedTrigger。恢复故障的任务。
集群管理线程会删除故障节点的实例状态(qrtz_scheduler_state表),即重置了所有故障节点触发任务一般,原先故障任务和正常任务一样就交由了调度处理线程处理。
3. 注意问题
1. 时间同步问题
Quartz实际并不关心你是在相同还是不同的机器上运行节点。当集群放置在不同的机器上时,称之为水平集群。节点跑在同一台机器上时,称之为垂直集群。对于垂直集群,存在着单点故障的问题。这对高可用性的应用来说是无法接受的,因为一旦机器崩溃了,所有的节点也就被终止了。对于水平集群,存在着时间同步问题。
节点用时间戳来通知其他实例它自己的最后检入时间。假如节点的时钟被设置为将来的时间,那么运行中的Scheduler将再也意识不到那个结点已经宕掉了。另一方面,如果某个节点的时钟被设置为过去的时间,也许另一节点就会认定那个节点已宕掉并试图接过它的Job重运行。最简单的同步计算机时钟的方式是使用某一个Internet时间服务器(Internet Time Server ITS)。
2. 节点争抢Job问题
因为Quartz使用了一个随机的负载均衡算法,Job以随机的方式由不同的实例执行。Quartz官网上提到当前,还不存在一个方法来指派(钉住) 一个 Job 到集群中特定的节点。
推荐阅读
Quartz管中窥豹之集群管理