Java Jsoup使用详解
1.Jsoup介绍
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。——引自百度百科对Jsoup的介绍
前置
引入Jsoup依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
2.使用Jsoup解析HTML
以下代码是使用Jsoup对html进行解析,这里的html只是一个小测试,可以使用HttpClient请求并获取响应的HTML,再通过Jsoup完成解析。
这里选择的是两个参数的解析,第二个参数为HTML的URL路径,当我们的HTML中有相对路径时,我们可以通过URL路径将相对路径转换为绝对路径。
此外,Jsoup还提供了其他参数的解析,如设置解析超时时间,还可以自定义解析器,设置解析的一些参数,如允许标签或属性的大小写。—— 一般这两个参数就够了。
StringBuilder htmlSB = new StringBuilder();
htmlSB.append("")
.append("")
.append("标题 ")
.append("")
.append("")
.append(" ")
.append("")
.append("");
Document document = Jsoup.parse(htmlSB.toString(), "http://www.baidu.com");
")
.append("")
.append("");
Document document = Jsoup.parse(htmlSB.toString(), "http://www.baidu.com");
解析过程:简单来说就是按字符不断遍历HTML,解析成一个个Element并追加到Document对象。
以下一整块可以认为是一个Document,
<html>...</html>
----<head>...</head>
--------<title>...</title>
----<body>...</body>
--------<img>...</img>
比如我们要获取HTML中所有图片的链接。这里使用的是cssQuery选择器语法,搜索文档中img带有src属性的Element,再打印图片路径(实际情况肯定要对路径处理,这里偷懒了)。
for (Element element : document.select("img[src]")) {
System.out.println(element.baseUri() + element.attr("src"));
}
Jsoup还提供给我们类似JavaScript的一些方法,能让我们方便的筛选出需要的元素。
document.getElementsByTag("");
document.getElementsByClass("");
document.getElementById("");
document.getElementsByAttribute("");
3.使用Jsoup发送HTTP请求
3.1GET请求
以下两种方式均可实现GET请求调用,主要两个方法返回的类型不同,这里将请求返回的HTML打印出来。
String url = "http://www.baidu.com";
Connection.Response response = Jsoup.connect(url).execute();
System.out.println(response.body());
Document document = Jsoup.connect(url).get();
System.out.println(document.html());
携带参数的GET请求,这里写了一个本地接口
@RequestMapping("/user")
@RestController
public class UserController {
@GetMapping("/myself")
public String myself(String name, int age) {
return "姓名:" + name + ",年龄:" + age;
}
}
String url = "http://localhost:8080/user/myself";
Connection.Response response = Jsoup
.connect(url)
.data("name", "张三")
.data("age", "20")
.execute();
System.out.println(response.body());
3.2POST请求
携带参数的POST请求,这里写了一个本地接口
@RequestMapping("/user")
@RestController
public class UserController {
@PostMapping("/login")
public ResponseVo login(@RequestBody UserLoginReq userLoginReq) {
return ResponseVo.getSuccess(userLoginReq);
}
}
注意这里有一个ignoreContentType(true),意思是忽略响应返回的类型,这儿不加会抛出org.jsoup.UnsupportedMimeTypeException异常
String url = "http://localhost:8080/user/login";
Connection connection = Jsoup.connect(url);
connection
.ignoreContentType(true)
.header("Content-Type", "application/json")
.requestBody("{\"username\": \"123123\",\"password\": \"123123\"}");
System.out.println(connection.post().text());
3.3额外请求属性
除了可以设置请求头,请求体,参数等,Jsoup还支持设置代理、请求超时、Cookie等。
下面模拟一个请求,请求简书需要登录的页面https://www.jianshu.com/my/paid_notes
(1)登录简书后,进入到该页面。
(2)按F12后刷新页面,请求头有一个remember_user_token,拥有这个值就可以认为我们已经登录了简书
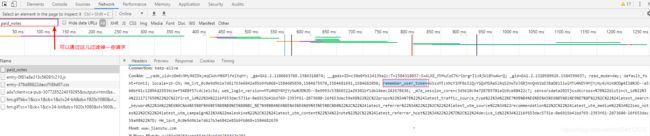
String url = "https://www.jianshu.com/my/paid_notes";
Connection.Response response = Jsoup
.connect(url)
.cookie("remember_user_token", "我这儿省略了!!!")
.execute();
System.out.println(response.body());
如果我们注释掉这个cookie,那么简书就会响应给我们一个登录页面要求我们进行登录。
4.Jsoup提供的另外两个方法
clean:支持两个功能,第一个就是讲HTML的body体中的相对路径转换为绝对路径,第二个就是可以过滤掉一些HTML标签和属性,可以通过使用白名单设置保留的标签和属性。
StringBuilder htmlSB = new StringBuilder();
htmlSB.append("")
.append("")
.append("标题 ")
.append("")
.append("")
.append("")
.append("")
.append("");
Whitelist whitelist = new Whitelist()
.addTags("head", "body", "img")
.addAttributes("img", "src")
.addProtocols("img", "src", "http", "https");
String html = Jsoup.clean(htmlSB.toString(), "http://www.baidu.com/", whitelist);
System.out.println(html);
打印结果,注意这里是没有的,因为是对body里面的内容进行处理。
<body>
标题
<img src="http://www.baidu.com/test.png">
</body>
isValid:这个方法是判断HTML的body是否符合白名单
public static boolean isValid(String bodyHtml, Whitelist whitelist) {
return new Cleaner(whitelist).isValidBodyHtml(bodyHtml);
}
完结,以上内容如果有误,欢迎指正!