Object基础方法:hashCode、clone、finalize
- Object基础方法
- registerNatives
- hashCode
- hashCode的作用
- hashCode()重写
- equals
- equals()重写
- toString
- clone
- finalize
- 参考文章
Object基础方法
Object 共有12个自带方法,notify、wait 类线程方法将会在线程相关章节涉及,getClass 在反射章节讲。
private static native void registerNatives();
public native int hashCode();
public boolean equals(Object obj) { return (this == obj); }
public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }
protected native Object clone() throws CloneNotSupportedException;
protected void finalize() throws Throwable { }
/
public final native Class<?> getClass();
public final native void notify();
public final native void notifyAll();
public final native void wait(long timeout) throws InterruptedException;
public final void wait(long timeout, int nanos) throws InterruptedException{...}
public final void wait() throws InterruptedException { wait(0); }
registerNatives
这是一个 private static native 方法,这里有个 native 关键字,忽然一脸懵逼,百度了下,顺便贴一下这个关键字的作用,开发中可以忽略。
Java有两种方法:Java方法和本地方法。
Java方法是由Java语言编写,编译成字节码,存储在class文件中。
本地方法是由其他语言(比如C,C++,或者汇编)编写的,编译成和处理器相关的机器代码,本地方法保存在动态连接库中,格式是各个平台专有的。
运行中的Java程序调用本地方法时,虚拟机装载包含这个本地方法的动态库,并调用这个方法,本地方法是联系Java程序和底层主机操作系统的连接方法。
Java Native Interface (JNI) 标准就成为java平台的一部分,它允许Java代码和其他语言写的代码进行交互。
简单地讲,一个用Native关键字修饰的方法就是一个java调用非java代码的接口;
registerNatives本质上就是一个本地方法,但这又是一个有别于一般本地方法的本地方法,从方法名我们可以猜测该方法应该是用来注册本地方法的。上述代码的功能就是先定义了registerNatives()方法,然后当该类被加载的时候,调用该方法完成对该类中本地方法的注册。
也就是说,凡是包含registerNatives()本地方法的类,同时也包含了其他本地方法。所以,当包含registerNatives()方法的类被加载的时候,注册的方法就是该类所包含的除了registerNatives()方法以外的所有本地方法。
hashCode
hashCode的作用
根据百度百科,hash实际上是一种散列算法,是将不同的输入散列程特定长度的输出;不同的输入可能会得到相同的输出,所以不能从散列值来判断出输入值。
hashCode()方法给对象返回一个int类型的 hash code 值。
在Java中,有一些哈希容器,比如Hashtable,HashMap等等。当我们调用这些容器的诸如get(Object obj)方法时,容器的内部肯定需要判断一下当前obj对象在容器中是否存在,然后再进行后续的操作。一般来说,判断是够存在,肯定是要将obj对象和容器中的每个元素一一进行比较,要使用equals()才是正确的。
但是如果哈希容器中的元素有很多的时候,使用equals()必然会很慢。这个时候我们想到一种替代方案就是hashCode():当我们调用哈希容器的get(Object obj)方法时,它会首先利用查看当前容器中是否存在有相同哈希值的对象,如果不存在,那么直接返回null;如果存在,再调用当前对象的equals()方法比较一下看哈希处的对象是否和要查找的对象相同;如果不相同,那么返回null。如果相同,则返回该哈希处的对象。
hashCode()被设计用来使得哈希容器能高效的工作。也只有在哈希容器中,才使用hashCode()来比较对象是否相等,但要注意这种比较是一种弱的比较,还要利用equals()方法最终确认。
我们把hashCode()相等看成是两个对象相等的必要非充分条件,把equals()相等看成是两个对象相等的充要条件。
在许多时候被认为 hash code 为内存位置,实际上,hashCode()作为一个native方法,它和对象地址确实有关系,实际上并不仅仅是对象地址。它代表的实际上是hash表中对应的位置。
hashCode()重写
以下约定摘自Object规范JavaSE 1.6
| 1.equals方法所比较的信息没有被修改,hashCode方法返回同一个整数。在同一个应用程序的多次执行过程中,hashCode每次返回的整数可以不一致。 |
| 2.如果两个对象equals方法比较相等,那么调用hashCode方法返回结果必须相等。 |
| 3.如果两个对象调用equals方法不相等,调用hashCode方法返回不一定相等。但是返回不相等的整数,有可能提高散列表(hash table)的性能 |
关于hashCode方法:
因此,重写equals方法而没有重写hashCode方法会违反第二条规范。
例如,测试类PhoneNumber()
public final class PhoneNumber {
private int areaCode;
private int prefix;
private int lineNumber;
//添加构造器
public PhoneNumber(int areaCode, int prefix, int lineNumber) {
this.areaCode = areaCode;
this.prefix = prefix;
this.lineNumber = lineNumber;
}
//重写equals方法
@Override
public boolean equals(Object obj) {
//判断是否为本对象的引用
if (this==obj) return true;
//判断是否和本对象类型相同
if (!(obj instanceof PhoneNumber)) return false;
//进行域对比
PhoneNumber p = (PhoneNumber) obj;
return p.areaCode == areaCode
&& p.lineNumber == lineNumber
&& p.prefix == prefix;
}
//尚未重写hashCode方法
// @Override
// public int hashCode() {
// return super.hashCode();
// }
}
试图将这个类和HashMap一起使用:
Map map = new HashMap();
map.put(new PhoneNumber(100,200,300),"Shiva");
//通过相同对象获取map.value
map.get(new PhoneNumber(100,200,300));
上面的测试中,map.get()期望获得"Shiva"字符串,然而实际上是null。因为这里的PhoneNumber涉及到了两个对象。new PhoneNumber()产生的是一个全新的对象。两张十块钱虽然等价,但是并不认为是同一张。
这里贴下HashMap.get()方法,基本就是对比散列码(哈希码),获取获取对应值。
//HashMap的get()方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//get()方法中调用的hash()方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
>>> : 无符号右移,忽略符号位,空位都以0补齐
如果重写了PhoneNumber()的HashCode方法。例如:
@Override
public int hashCode() {
return 42;
}
这样,在测试代码中就能得到"Shiva",而且这种写法是合法的,保证了相等对象具有相同的哈希码。但是,每个对象都具有相同的哈希码,因此,每个对象都会被映射到同一个散列桶中,是散列表退化为链表(linked list)。使得本该线性时间运行的程序变成以平方级时间运行。对大规模的散列表,会影响正常运行。
HashCode的重写方式:
一个好的HashCode方法倾向于“为不同对象产生不同的哈希码”。通过以下方式,可以尽可能做到这一点:
1.把某个非零的常数值,比如17,保存在一个名为result的int类型的变量中
2.对于对象中的每个域f(equals方法中涉及到的每个域),完成以下步骤:
a.为该域计算int类型的哈希码c:
i.如果该域是boolean类型,则计算(f ? 1 : 0)
ii.如果该域是byte,char,short或者int类型,则计算(int)f
iii.如果该域是long类型,则计算(int)(f ^ f >>> 32)
iv.如果该域是float类型,则计算Float.floatToIntBits(f)
v.如果该域是double类型,则计算Double.doubleToIntBits(f),然后按照步骤2.a.iii,为得到的long类型值计算散列值
vi.如果该域是一个对象引用,并且该类的equals方法通过递归调用equals的方式来比较这个域,则同样为这个域递归调用hashCode。如果这个域值为null,则返回0(或者为其他常数)
vii.如果该域是一个数组,则将每一个元素当成单独域来处理。递归调用上面的方法
b.按照下面公式,把步骤2.a中计算得到的哈希码c,合并到result中
result = 31 * result + c;
3.返回result
4.写完后,查看是否“相等的实例是否具有相同hashCode”,并单元测试。
equals
一般的包装类型都重写了 equals() 方法,并不是直接对比内存地址。
- 自反性(reflexive)。对于任意不为
null的引用值x,x.equals(x)一定是true。 - 对称性(symmetric)。对于任意不为
null的引用值x和y,当且仅当x.equals(y)是true时,y.equals(x)也是true。 - 传递性(transitive)。对于任意不为
null的引用值x、y和z,如果x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true。 - 一致性(consistent)。对于任意不为
null的引用值x和y,如果用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false。 - 对于任意不为
null的引用值x,x.equals(null)返回false。
equals()重写
| 1.使用 == 操作符检查“参数是否为对这个对象的引用” |
| 2.使用 instanceif 操作符检查“参数是否为正确的类型” |
| 3.对于该类中的每个“关键(significant)”域,检查参数中的域是否与该对象中对应的域相匹配 |
关于equals方法:
- 使用 == 操作符检查“参数是否为对这个对象的引用”。如果equals的对象为本身的引用,那么返回肯定是true。在方法内首先判断,可以做为一种性能优化,如果操作比较昂贵,就值得这么做。
- 使用 instanceof 操作符检查“参数是否为正确的类型”。instanceof 操作符可以判断传入参数与本身类型是否相同。也相当于是一种性能优化。其次,在有些情况下,指该类所实现得接口。例如集合接口(collection interface)得Set,List,Map和Map.Entry。
- 对于该类中的每个“关键(significant)”域,检查参数中的域是否与该对象中对应的域相匹配。如果第二条中的类型是个接口,就必须通过接口方法访问参数中的域;如果是个类,就可以直接访问。
| 基本类型域 | 除了float和double,可以直接使用==进行比较 |
| 对象引用域 | 可以调用引用对象的equal方法 |
| float域 | Float.compare方法 |
| double域 | Double.compare方法 |
float和double的比较需要经过特殊处理,存在例如Float.NaN,-0.0f的常量。有些对象可以包含null,需要考虑避免空指针异常。
域的比较顺序可能会影响equal方法的效率,应该最先比较最有可能不同的域,或者开销最低的域。
不要将equals声明中的Object对象替换为其他(那就不是重写方法了,而是自定义方法。)
在自定义一个类的时候,我们必须要同时重写equals()和hashCode(),并且必须保证:
其一:如果两个对象的equals()相等,那么他们的hashCode()必定相等。
其二:如果两个对象的hashCode()不相等,那么他们的equals()必定不等。
toString
Object默认toString方法为16进制 hashcode 字符串,
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
以下摘自《effective java》:
toString 的通用约定要求 「建议所有的子类重写这个方法」 ,返回的字符串应该是 「一个简洁但内容丰富的表示,对人们来说是很容易阅读的」 。
在静态工具类中编写 toString 方法是没有意义的。 你也不应该在大多数枚举类型中写一个 toString 方法,因为 Java 为你提供了一个非常好的方法。
但是,你应该在任何抽象类中定义 toString 方法,该类的子类共享一个公共字符串表示形式。 例如,大多数集合实现上的 toString 方法都是从抽象集合类继承的。
除非父类已经这样做了,否则在每个实例化的类中重写 Object 的 toString 实现。 它使得类更加舒适地使用和协助调试。 toString 方法应该以一种美观的格式返回对象的简明有用的描述。
clone
clone() 方法返回与当前对象的一个副本对象,使用 clone() 方法需要实现 Cloneable 接口。
clone() 在 Object 中是 protected 方法,在别的类中调用需要重写。
在Java中,clone() 方法有两种不同的模式,即浅复制和深复制(也被称为浅拷贝和深拷贝)。
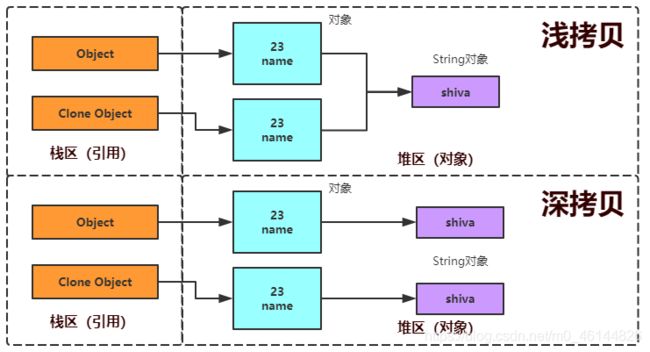
对于浅复制,只是对象的引用得到的复制;如果对象中存在其他对象的引用,使用浅复制后,源对象和复制后的对象中对其他对象的引用会指向同一个内存地址。如果要完全把两个对象在内存中分开,必须使用深复制。
阿里巴巴Java开发手册中提到,慎用自带 clone() 方法,默认是浅拷贝。所以需要用到 clone() 一定要重写。
深拷贝举例:
class Stu implements Cloneable{
String name;
Pen pen = new Pen();
@Override
protected Object clone() throws CloneNotSupportedException {
Stu temp = (Stu) super.clone();
temp.pen = (Pen) pen.clone();
return temp;
}
}
class Pen implements Cloneable{
String name;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
finalize
java提供finalize()方法,垃圾回收器准备释放内存的时候,会先调用finalize()。 对于垃圾回收,需要首先了解 《JAVA编程思想》中对finalize的讲解 :
- 对象不一定会被回收。
- 垃圾回收不是析构函数。
- 垃圾回收只与内存有关。
- 垃圾回收和finalize()都是靠不住的,只要JVM还没有快到耗尽内存的地步,它是不会浪费时间进行垃圾回收的。
在Java中,由于GC的自动回收机制,因而并不能保证finalize方法会被及时地执行(垃圾对象的回收时机具有不确定性),也不能保证它们会被执行(程序由始至终都未触发垃圾回收)。
finalize()使用时机
finalize()方法中一般用于释放非Java 资源(如打开的文件资源、数据库连接等),或是调用非Java方法(native方法)时分配的内存(比如C语言的malloc()系列函数),上面提到的 clone() 创建的。
应该避免使用finalize()
GC可以回收大部分的对象(凡是new出来的对象,gc都能搞定,一般情况下我们不会用new以外的方式去创建对象),所以一般是不需要程序员去实现finalize的。
以下摘自《Effective Java》:
1、终结方法(finalizer)通常是不可预测的,也是很危险的,一般情况下是不必要的。是使用终结方法会导致行为不稳定、降低性能,以及可移植性问题。所以,我们应该避免使用终结方法。
2、使用终结方法有一个非常严重的性能损失。在我的机器上,创建和销毁一个简单对象的时间大约为5.6ns、增加一个终结方法使时间增加到了2400ns。换句话说,用终结方法创建和销毁对象慢了大约430倍。
3、如果实在要实现终结方法,要记得调用super.finalize()
参考文章
https://www.cnblogs.com/KingIceMou/p/7239668.html
https://www.jianshu.com/p/8236d9bc2abf
https://blog.csdn.net/Saintyyu/article/details/90452826
https://blog.csdn.net/dome_/article/details/92084823
https://www.cnblogs.com/Qian123/p/5703507.html#_labelTop
https://www.cnblogs.com/yibutian/p/9619696.html
https://www.cnblogs.com/KpGo/p/10454142.html
https://zhuanlan.zhihu.com/p/43001449
https://jingyan.baidu.com/article/3ea51489bb18e152e71bba76.html
https://www.cnblogs.com/lolybj/p/9738946.html
https://www.iteye.com/blog/bijian1013-2288225
https://blog.csdn.net/crazylai1996/article/details/84900818
https://blog.csdn.net/lixpjita39/article/details/79383957