爬虫学习
爬虫知识学习笔记
文章目录
- 一、爬虫的分类
- 二、爬虫的准备工作
- 三、http协议
- 四、requests模块
- 1、使用步骤
- 2、requests get方法
- response对象
- 例子1:获取百度产品页面
- 例子2:获取新浪新闻页面
- 分页如何实现?
- 例子3:爬取贴吧中前十页的内容保存到本地
- 3.requests post请求
- 例子4:破解百度翻译,做到可以查询任意单词效果
- 五、数据的分类
- 1、分类
- (1)结构化数据:能用关系型数据库描述的数据
- (2)半结构化数据:拥有字描述结构数据
- (3)非结构化数据
- 2、json 数据
- (1)json 与 js 关系
- (2)json 数据的处理(重点)
- 六、cookie和session
- 1、什么是cookie和session?
- 2、cookie和session产生的原因:
- 3、cookie原理:
- 4、session原理:
- 5、常见误区:打开浏览器中的一个网页,浏览器关闭,这个网页的session会不会失效?
- 6、cookie的字段
- 7、会话cookie和持久cookie
- 8、用requests登录页面
- 例子5:人人网登录
- 七、代理使用方法
- 1、代理基本原理
- 2、代理的作用
- 3、在requests模块中如何设置代理
- 例子6:高德地图(获取所有城市的天气信息)
一、爬虫的分类
爬虫可以分为通用爬虫和聚焦爬虫
1、通用爬虫:就是将互联网上的数据整体爬取下来保存到本地的一个爬虫程序,是搜索引擎的重要组成部分。
(1)搜索引擎:就是运用特定的算法和策略,从服务器上获取页面信息,并将信息保存到本地为用户提供检索服务的系统。
(2)搜索引擎的工作步骤:
- 第一步:抓取网页
- 第二步:数据存储
- 第三步:预处理
提取文字
中文分词
消除噪音(比如版权声明文字、导航条、广告等……)
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。 - 第四步:提供检索服务,网站排名
2、聚焦爬虫:在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
二、爬虫的准备工作
(1)robots协议
定义:网络爬虫排除标准
作用:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
写爬虫程序要规避robots协议即可。
(2)网站地图sitemap
sitemap 就是网站地图, 它通过可视化的形式, 展示网站的主要结构。比如:列表页、分类页、tag页,以及内容页面。
网上有很多sitemap生成网站:https://help.bj.cn/
(3)估算网站的大小
可以使用搜索引擎来做,比如在百度中使用site:www.zhihu.com
三、http协议
http协议:超文本传输协议
作用:是一种收发html的【一种规范】。
http端口号:80
https : 安全版的http协议
https端口号:443
SSL(安全套接层)用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
数字签证
http协议的特点:
(1)应用层协议。(最顶层也是和用户交互的层。)
(2)无连接:http协议每次发送请求都是独立的。http 1.1以后有请求头:connection:keep_alive.
(3)无状态:http协议不记录状态,进而产生了两种记录http状态的技术:cookie 和 session。
url:统一资源定位符
-
主要作用:用来定位互联网上的任意资源的位置
-
url 组成:https://www.baidu.com/index.html?username=123&password=abc#top
(1)scheme:协议—https
(2)netloc : 网络地址:ip:port—www.baidu.com
通过ip定位电脑(网卡)
通过port定位应用。例如mysql(3306)、mogono
(3)path:资源路径
(4)query:请求参数:?后面的内容username=123&password=abc
(5)fragment:锚点----top -
url 中特殊符号:
?:get请求的参数在?后面
& : get请求的多个参数用&连接
# : 锚点,用来定位到页面中任意位置----如果url中有锚点,在爬虫程序中尽量去除。 -
python中用来解析 url 的模块。
from urllib import parse
url = https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=baidutop10&wd=python&oq=%25E7%25BA%25BD%25E7%25BA%25A6%25E5%25B7%259E%25E6%2596%25B0%25E5%25A2%259E7917%25E4%25BE%258B&rsv_pq=bf1978c40001323b&rsv_t=734dvlMHLeNpQvWiTURFFV%2BQ3xwarh7lmTJlBpNmlPeoioFYCukHcZwgQwbuDBaVvg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&inputT=1193&rsv_sug4=1193
result = parse.urlparse(url)
print(result.scheme)
print(result.netloc)
-
http工作过程:
(1)地址解析
(2)封装HTTP请求数据包
(3)封装成TCP包,建立TCP连接(TCP的三次握手)
(4)客户机发送请求命令
(5)服务器响应
(6)服务器关闭TCP连接 -
客户端请求
(1)组成:请求行、请求头、空行、请求数据(实体)四个部分组成
请求行:协议,url,请求方法
请求头:主要的作用就是来限定这个请求的详细信息。
请求数据:post请求的数据是放到这里面的。
(2)重要请求头
user-agent:客户端标识(身份)
cookie:请求的状态信息
referer:表示产生请求的网页来源于哪里(防盗链)
accept:允许传入的文件类型
x-requested-with:ajax请求必须要封装的头
(3)请求方法:
get/post/put(推送——delete(删除)——trace(诊断)——options(性能)——connect(连接,预留字段)
get方法:get获取–从服务器获取资源–条件(请求参数)—请求参数是拼接到url里面的?后面–不安全(容易被别人获取:用户名和密码)—大小受限。
post方法:post传递–向服务器传递数据–请求数据是放在实体里面。----安全—大小不受限 -
服务器响应
(1)组成:状态行:状态码、消息报头、空行、响应正文(html)
(2)响应头
Content-Type: text/html;charset=utf-8:响应的类型
(3)状态码(状态码)
1xx:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
2xx:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
3xx:为完成请求,客户需进一步细化请求。
4xx:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访)
5xx:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。 -
当我们在客户端输入一个url,客户端是如何请求加载出整个页面的?
(1)客户端解析url,封装数据包,发送请求给服务器。
(2)服务器从请求中解析出客户端想要内容,比如 index.html,然后把该页面封装成响应数据包,发送给客户端。
(3)客户端检查该 index.html 中是否有静态资源需要继续请求,比如 js,css,图片,如果有继续请求获取静态资源。
(4)客户端按照html的语法结合静态资源将页面完美的显示出来。
四、requests模块
1、使用步骤
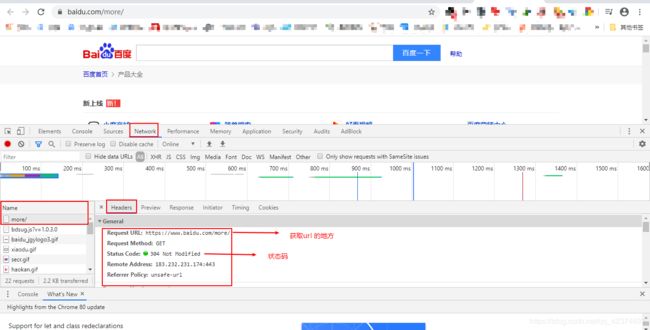
# 导包
import requests
# 确定待爬取的url
base_url = 'https://www.baidu.com/more/'
# 发送请求,获取响应
response = requests.get(base_url)
# 处理响应内容
print(response)
2、requests get方法
requests.get(
url=请求url,
headers =请求头字典,
params = 请求参数字典。
timeout = 超时时长,
)——>response对象
response对象
服务器响应包含:状态行(协议,状态码)、响应头,空行,响应正文
(1)响应正文:
- 字符串格式:response.text
- bytes类型:response.content
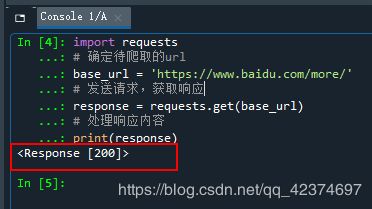
例子1:获取百度产品页面
import requests
# 确定待爬取的url
base_url = 'https://www.baidu.com/more/'
# 发送请求,获取响应
response = requests.get(base_url)
# 处理响应内容
print(response.text) #会出现乱码
#乱码产生的原因:编码和解码的编码格式不一致造成的
#str.encode('编码')---将字符串按指定编码解码成bytes类型
#bytes.decode('编码')---将bytes类型按指定编码编码成字符串。
# 响应正文的乱码问题解决
#第一种方法
response_str = response.content.decode('utf-8')
print(response_str)
#第二种方法
print(response.encoding) #ISO-8859-1
#如果response.text乱码了,可以先给response.encoding设置正确编码,在通过response.text就可以获取正确的页面内容。
response.encoding = 'utf-8'
response_str = response.text
print(response_str)
#保存
with open('index.html','w',encoding='utf-8') as fp:
fp.write(response_str)
例子2:获取新浪新闻页面
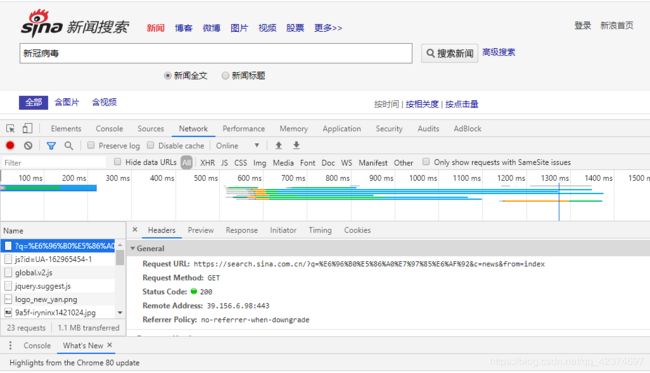
问号之前的(包括问号)为基础url
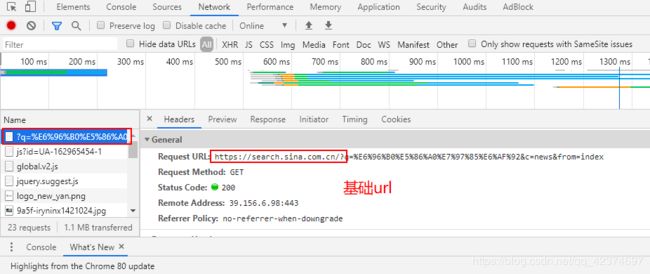
请求头:user-agent

完整的 url ,问号之后的就是 params

import requests
'''
模仿网页中的搜索功能,可以查看任意搜索内容的页面进行保存
'''
def main(kw):
# 1.确定待爬取的url
base_url = 'https://search.sina.com.cn/?'
# 2.发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
}
# 2.2 params字典
# 问号之后的
params = {
'range':'all',
'c':'news',
'q': kw,
'from': 'home',
'ie':'utf-8',
}
response = requests.get(base_url,headers=headers,params=params)
# print(response.encoding)
response_str = response.text
with open('sina_news6.html','w',encoding='GB18030') as fp:
fp.write(response_str)
if __name__ == '__main__':
kw = input("输入搜索关键词:")
main(kw)
print()
print("搜索完成!")
也可以使用parse拼接,url中出现中文,必须将中文用url编码进行转码才可以
import requests
# 用parse对 url 转码
from urllib import parse
'''
对于get请求,我们直接也可以将参数完全拼接到url里面,直接请求url
url中出现中文,必须将中文用url编码进行转码才可以.
'''
def main(kw):
# 1、确定基础url
base_url = 'https://search.sina.com.cn/?'
# 2、发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
# 2.2 params字典
params = {
'q': kw,
'c': 'news',
'from': 'channel',
'ie': 'utf-8',
}
# 通过拼接url的形式来进行请求
url_extend = parse.urlencode(params)
# print(url_extend)
# 完整的 url = 基础 url + 转码后的params
full_url = base_url+url_extend
response = requests.get(full_url,headers=headers)
response_str = response.text
with open('aaa.html','w',encoding='GB18030') as fp:
fp.write(response_str)
if __name__ == '__main__':
kw = input("输入搜索关键词:")
main(kw)
print()
print("搜索完成!")
(2)状态码:response.status_code
(3)响应头:response.headers
分页如何实现?
分页的请求的每一页url基本上都是通过get请求的一个请求参数决定的,所以分页主要是查看每页中,请求参数页码字段的变化,找到变化规律,用for循环就可以做到分页。
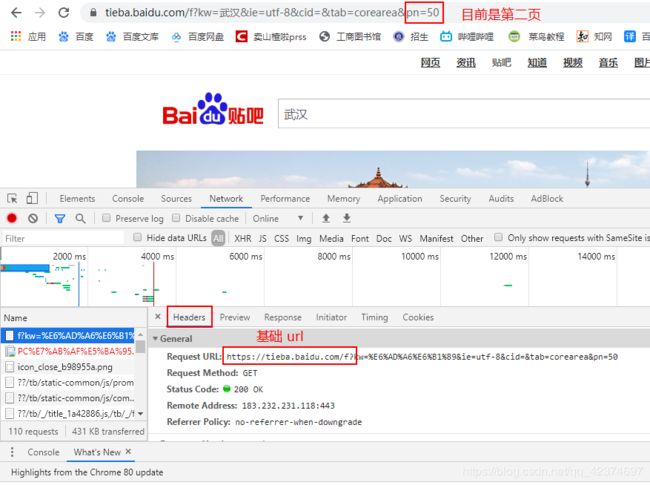
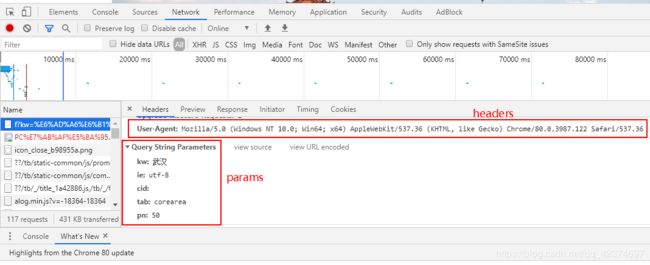
例子3:爬取贴吧中前十页的内容保存到本地
百度贴吧中第一页 参数:pn=0
百度贴吧中第二页 参数:pn=50
百度贴吧中第三页 参数:pn=100
…
import requests
import os
def main():
# 确定基础url
base_url = 'http://tieba.baidu.com/f?'
#准备参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
filename = './tieba/'+kw
# 实现页面保存到每个贴吧名称对应的文件夹中。
if not os.path.exists(filename):
#不存在创建文件夹
os.mkdir(filename)
for i in range(10):
# 页码值
pn = i*50
params = {
'kw': kw,
'ie': 'utf-8',
'tab': 'corearea',
'pn': pn,
}
# 发送请求,获取响应
response = requests.get(base_url,headers= headers,params=params)
with open(filename+'/'+str(i+1)+'.html','w',encoding='utf-8') as fp:
fp.write(response.text)
if __name__ == '__main__':
kw = '武汉'
main()
3.requests post请求
post请求一般返回数据都是json数据。
post请求与get请求又相似的地方
response = requests.post(
url = 请求url地址,
headers = 请求头字典,
data=请求数据字典,
timeout=超时时长,
)---response对象。
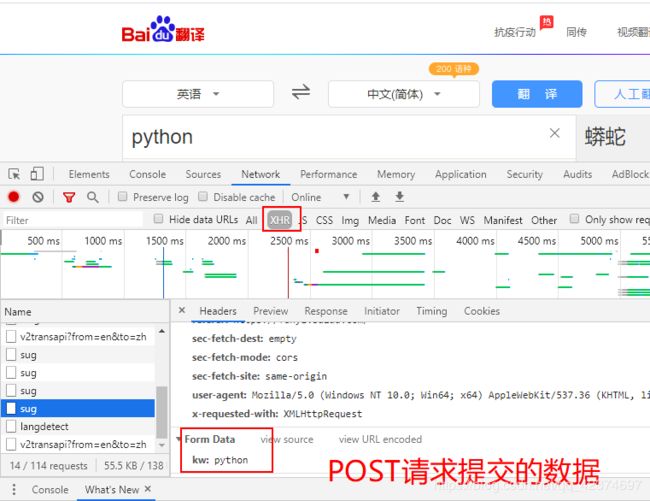
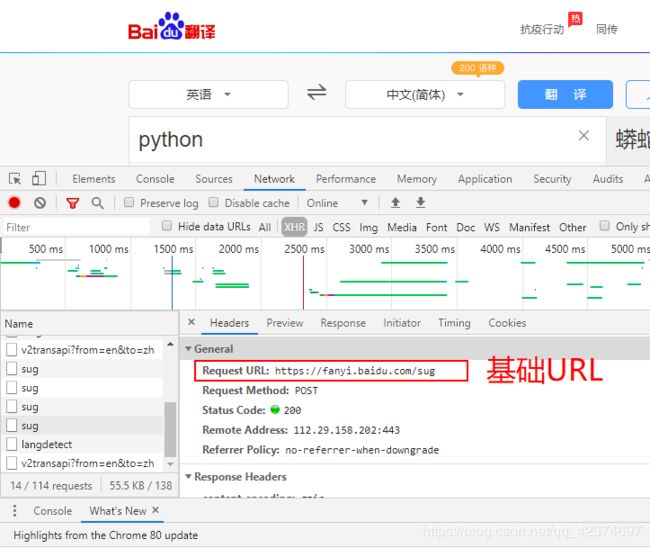
例子4:破解百度翻译,做到可以查询任意单词效果
url
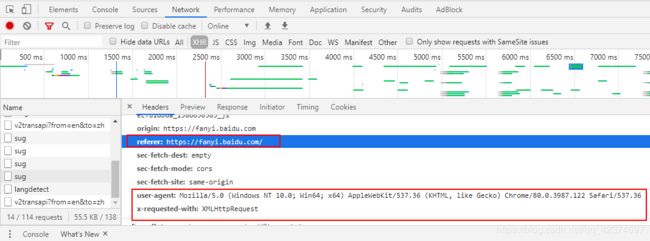
headers字典中需要放入的
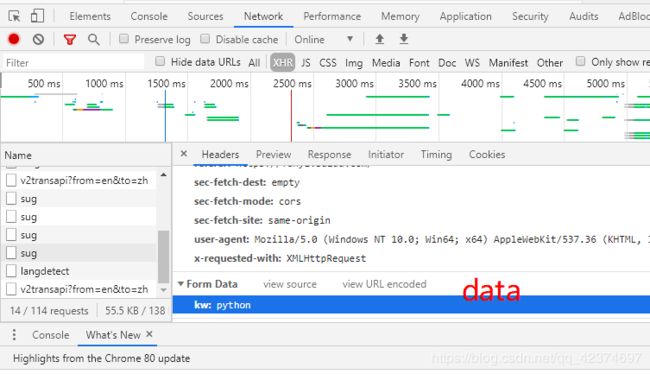
data
import requests
import json
# 1、确定基础url
base_url = 'https://fanyi.baidu.com/sug'
# 2、发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'content-length': '9',#POST请求数据的长度(字符的个数)
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
# 2.2 data
data = {
'kw': 'python'
}
response = requests.post(base_url, headers=headers, data=data)
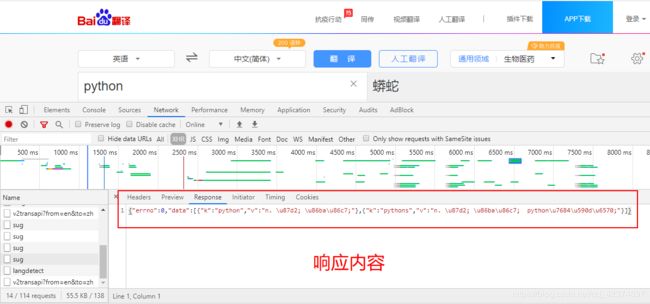
# 得到返回的json数据
print(response.text)
# {"errno":0,"data":[{"k":"python","v":"n. \u87d2; \u86ba\u86c7;"},{"k":"pythons","v":"n. \u87d2; \u86ba\u86c7; python\u7684\u590d\u6570;"}]}
json_data = json.loads(response.text)
print(json_data)
# {'errno': 0, 'data': [{'k': 'python', 'v': 'n. 蟒; 蚺蛇;'}, {'k': 'pythons', 'v': 'n. 蟒; 蚺蛇; python的复数;'}]}
result = ''
for data in json_data['data']:
result += data['v'] + '\n'
print(result)
# n. 蟒; 蚺蛇;
# n. 蟒; 蚺蛇; python的复数;
封装为函数
import requests
import json
def main(kw):
# 1、确定基础url
base_url = 'https://fanyi.baidu.com/sug'
data = {
'kw': kw
}
data_len = len(str(data))
headers = {
'content-length': str(data_len),
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
# 发送请求,获取响应
response = requests.post(base_url, headers=headers, data=data) # 得到返回的json数据
# print(response.text)
json_data = json.loads(response.text)
# print(json_data)
result = ''
for data in json_data['data']:
result += data['v'] + '\n'
return(result)
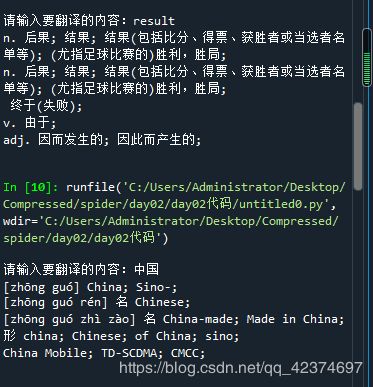
if __name__ == '__main__':
kw = input("请输入要翻译的内容:")
result = main(kw)
print(result)
五、数据的分类
1、分类
(1)结构化数据:能用关系型数据库描述的数据
特点:数据以行为单位,一行数据表示一个实体的信息,每一行的数据的属性是相同的。
举例:关系数据库中存储的表
处理方法:sql—结构化查询语言—语言—可以在关系型数据库中对数据的操作。
(2)半结构化数据:拥有字描述结构数据
特点:包含相关标记,用来分隔语义元素以及对记录和字段进行分层----也别成为自描述结构
举例:html,xml,json。
处理方法:正则,xpath(xml,html)
(3)非结构化数据
特点:没有固定结构的数据。
举例:文档,图片,视频,音频等等,都是通过整体存储二进制格式来保存的。
如果下载视频,音频。
处理:
response = requests.get(url='视频的地址')
保存response.content即可,文件名称后要注意。
2、json 数据
json(JavaScript Object Notation,JS对象标记)
json是一种数据【交换】的格式。
(1)json 与 js 关系
json是Js对象的字符串表达式,他使用文本形式表示一个Js对象的信息,本质是一个字符串(用来保存对象=字典和数组=列表)
js中的对象:var obj = {name:'zhangsan',age:'10'}----在python中这个可以当成:字典
js中的数组:var arr = ['a','b','c','d']----在python中这个可以当成:list
(2)json 数据的处理(重点)
1. 使用json模块处理
json_str 表示 json数据
json.loads(json_str)--->变成--->python的list或者字典
json.dumps(python的list或者字典)--->变成--->json_str
2. requests模块
在requests模块中,response对象有个json方法,可以直接得到相应json字符串解析后的内容
response.json()--->变为--->python的list或者字典
import requests
import json
json_data = {'abc':'0','cc':[1,2,3,4,5]}
# json.dumps(python的list或者字典)--->变成--->json_str
json_str = json.dumps(json_data)
print(json_str)
print(type(json_str))
# {"abc": "0", "cc": [1, 2, 3, 4, 5]}
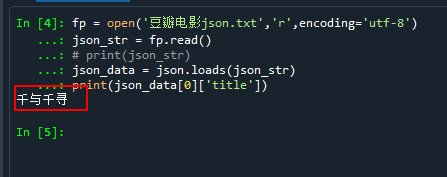
# 
六、cookie和session
1、什么是cookie和session?
cookie是网站用来辨别用户身份,进行会话跟踪,存储在本地终端上的数据。
session(会话)指有始有终的一系列动作和消息。在web中,session主要用来在服务器端存储特定用户对象会话所需要的信息。
2、cookie和session产生的原因:
http协议是一个无状态协议,在特定操作的时候,需要保存信息,进而产生了cookie和session。
3、cookie原理:
由服务器来产生,浏览器第一次请求,服务器发送给客户端进而保存。
浏览器继续访问时,就会在请求头的cookie字段上附带cookie信息,这样服务器就可以识别是谁在访问了。
但是cookie存在缺陷:
1、不安全–本地保存,容易被篡改。
2、大小受限,本身最大4kb。
cookie虽然在一定程度上解决了‘保持状态’的需求,但是我们希望有一种新的技术可以克服cookie缺陷,这种技术就是session。
4、session原理:
session在服务器保存。----解决安全问题。
问题来了:服务器上的session,但是客户端请求发送过来,服务器如何知道session_a,session_b,到底和那个请求对应。
所以为了解决这个问题:cookie就作为这个桥梁。在cookie有一个sessionid字段,可以用来表示这个请求对应服务器中的哪一个session。
禁用cookie,一般情况下,session也无法使用。特殊情况下可以使用url重写技术来使用session。
url重写技术:将sessionid拼接到url里面。
session的生命周期:服务器创建开始,有效期结束(一般网站设定都是大约30分钟左右),就删除。
cookie和session 配合使用既解决安全问题,又解决大小受限问题
5、常见误区:打开浏览器中的一个网页,浏览器关闭,这个网页的session会不会失效?
不会,服务器到底删除不删除session,由session的生命周期。有效期结束,就会被删除。
6、cookie的字段
(1)Name : 该的名称。一旦创建, 该名称便不可更改。
(2)value : 该cookie 的值。如果值为Unicode 字符, 需要为字符编码。如果值为二进制数据, 则需要使用BASE64 编码。
(3)Domain : 可以访问该cookle 的域名。例如, 如果设置为.zhihu.com , 则所有以zhihu.com 结尾的域名都可以访问该cookie。
(4)MaxAge : 该cookie 失效的时间, 单位为秒, 也常和Expires一起使用, 通过它可以计算出其有效时间。Max Age 如果为正数, 则该cookie 在Max Age 秒之后失效。如果为负数, 则关闭浏览器时cookie 即失效, 浏览器也不会以任何形式保存该cookie 。
(5)Path : 该cookie 的使用路径。如果设置为/path/ , 则只有路径为/ path / 的页面可以访问该cookie 。如果设置为/ , 则本域名下的所有页面都可以访问该cookie
(6)Size 字段: 此Cookie 的大小。
(7)HTTP 字段: cookie 的httponly 属性。若此属性为true , 则只有在HTTP 头中会带有此Cookie 的信息, 而不能通过document.cookie 来访问此Cookie。
(8)Secure : 该cookie 是否仅被使用安全协议传输。安全协议有H TTP s 和SSL 等, 在网络上传输数据之前先将数据加密。默认为false。
7、会话cookie和持久cookie
- 会话cookie:Max Age 为负数,则关闭浏览器时cookie 即失效,保存在内存中的cookie。
- 持久cookie:Max Age 如果为正数, 则该cookie 在Max Age 秒之后失效。保存在硬盘上的cookie
持久化:将内存中数据持久化到硬盘上。其实就是数据保存到文件或者数据库中。
序列化:将对象持久化到硬盘中。
8、用requests登录页面
(1)将登录后的cookie封装到请求头字典中,这样就可以了。
例子5:人人网登录
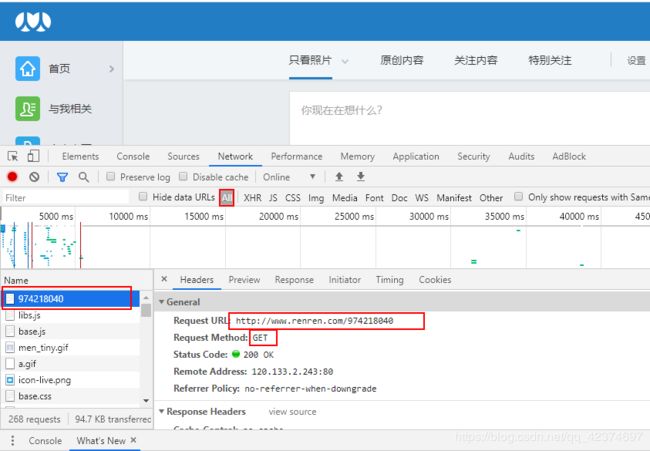
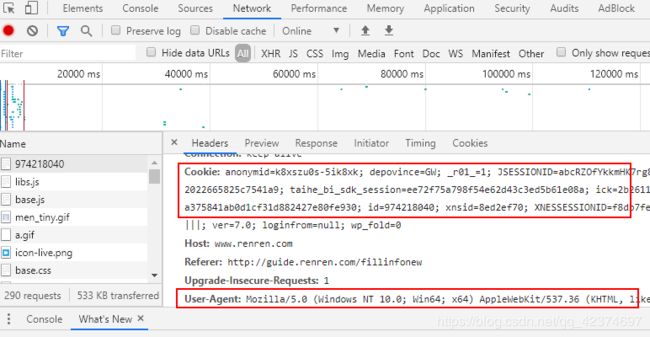
用封装cookie的形式来登录
import requests
def login():
# 确定基础url
base_url = 'http://www.renren.com/974218040'
# 准备参数
headers = {
'Cookie':'anonymid=k8xszu0s-5ik8xk; depovince=GW; _r01_=1; JSESSIONID=abcRZOfYkkmHK7rg8kXfx; ick_login=0d09651c-348b-49e2-b0e9-0ec7da7b9519; taihe_bi_sdk_uid=25abb1a4702d8272022665825c7541a9; taihe_bi_sdk_session=ee72f75a798f54e62d43c3ed5b61e08a; ick=2b261181-d2e4-4e59-8054-581a5854ad0a; t=72a375841ab0d1cf31d882427e80fe930; societyguester=72a375841ab0d1cf31d882427e80fe930; id=974218040; xnsid=8ed2ef70; XNESSESSIONID=f8db7fe06bf4; WebOnLineNotice_974218040=1; jebecookies=af052275-8990-44b5-99fb-439ae01d98d6|||||; ver=7.0; loginfrom=null; wp_fold=0',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
# 发送请求,获取响应
response = requests.get(base_url, headers=headers)
if '小谭' in response.text:
return True
else:
return False
if __name__ == '__main__':
result = login()
if result:
print('登陆成功')
else:
print('登录失败!')

用requests模块的session对象,使用用户名和密码登录
import requests
'''
用requests模块的session对象,使用用户名和密码登录
'''
def login():
#确定url
#from 标签中action
login_url = 'http://www.renren.com/PLogin.do'
# 创建一个session(会话)对象:可以记录登录后的状态。
session = requests.session()
#用session对象来进行登录操作,这个对象就会记录登录的状态。
#准备登录请求的参数
data = {
'email':'1********8',
'password':'123456789',
}
#登录
session.post(login_url,headers=headers,data=data)
return session
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537',
}
session = login()
index_url = 'http://www.renren.com/974218040'
response = session.get(index_url,headers = headers)
if '小谭' in response.text:
print('登录成功!')
else:
print('登录失败!')
七、代理使用方法
1、代理基本原理
代理可以说是网络信息中转站(中间人)。实际上就是在本机和服务器之间架了一座桥。
2、代理的作用
(1)突破自身ip访问现实,可以访问一些平时访问不到网站。
(2)访问一些单位或者团体的资源。
(3)提高访问速度。代理的服务器主要作用就是中转,所以一般代理服务里面都是用内存来进行数据存储的。
(4)隐藏ip。
3、在requests模块中如何设置代理
proxies = {
'代理服务器的类型':'代理ip'
}
response = requests.get(proxies = proxies)
代理服务器的类型:http,https,ftp
代理ip:http://ip:port
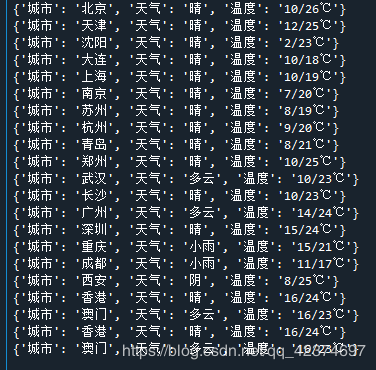
例子6:高德地图(获取所有城市的天气信息)
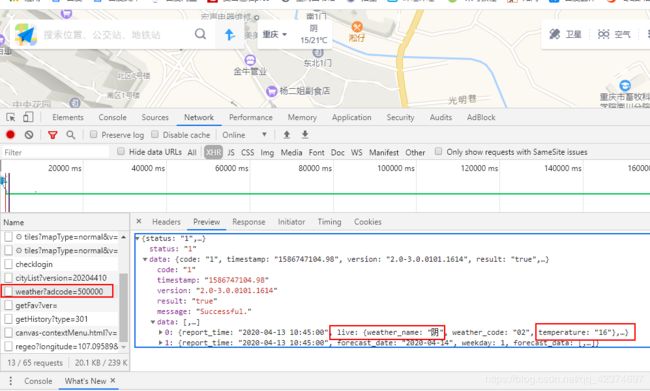
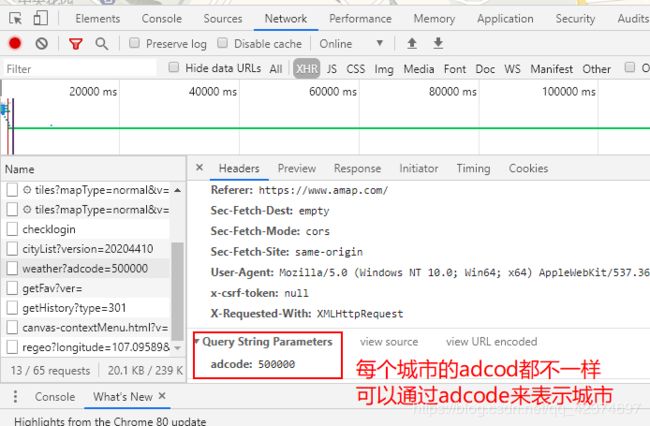
下一步获取全国城市的adcode
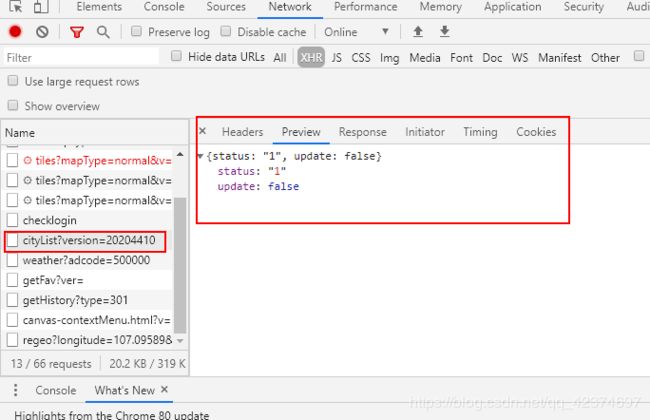
发现并没有
可以先清空缓存,在重新请求刷新页面。
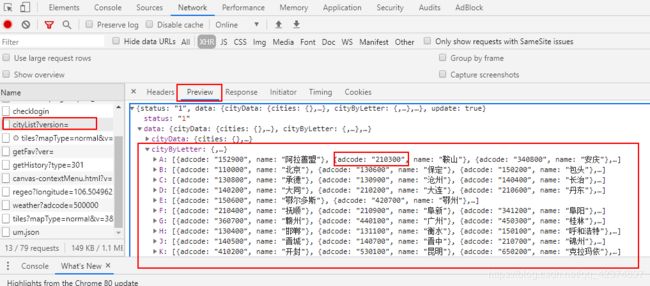
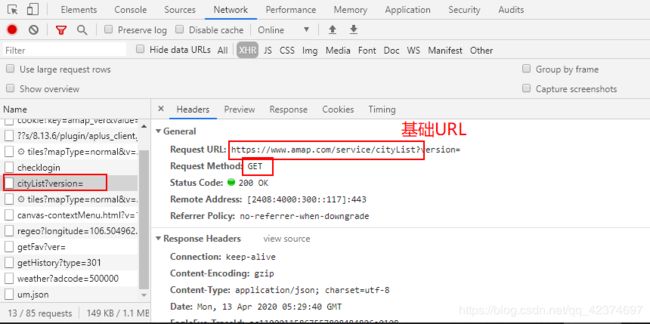
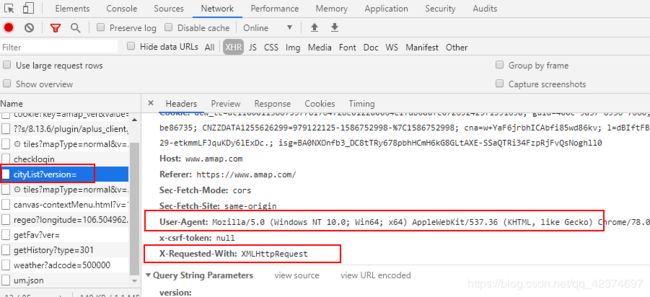
获取城市
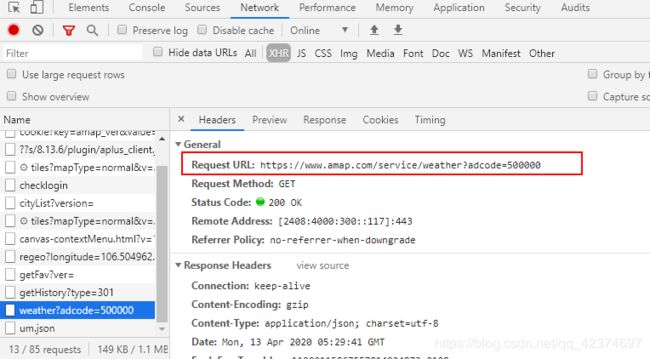
获取天气
import requests
#获取城市以及对应的adcode
def get_city():
#确定url
base_url = 'https://www.amap.com/service/cityList?'
# 发送请求
response = requests.get(base_url,headers=headers)
# print(response.text)
#解析json数据
json_data = response.json()
# print(json_data) 得到的json数据放到在线json解析网站中,方便分析结构
#获取adcode
#热门城市
city_adcode = []
for data in json_data['data']['cityData']['hotCitys']:
city_adcode.append((data['adcode'],data['name']))
#其他城市
for data in json_data['data']['cityData']['otherCitys']:
city_adcode.append((data['adcode'],data['name']))
return city_adcode
def get_weather(adcode,city_name):
'''
获取城市天气
Query String Parameters
adcode:500000
'''
#基础url
base_url = 'https://www.amap.com/service/weather?adcode={}'.format(adcode)
response = requests.get(base_url, headers=headers) #发送请求,获取响应
json_data = response.json() #获取json数据
#通过得到的json数据,在在线解析网站中解析后,分析其结构,找到要获取的在哪一个字典或者列表列表
#分层的取出来即可
if json_data['data']['result']=='true':
weather = json_data['data']['data'][0]['forecast_data'][0]['weather_name'] #当前天气
#最大温度
max_temp = json_data['data']['data'][0]['forecast_data'][0]['max_temp']
#最小温度
min_temp = json_data['data']['data'][0]['forecast_data'][0]['min_temp']
# print(weather, max_temp, min_temp)
dic = {}
dic['城市'] = city_name
dic['天气'] = weather
dic['温度'] = '{}/{}℃'.format(min_temp,max_temp)
print(dic)
def main():
city_adcode = get_city()
# print(city_adcode)
#将每个城市的adcode传给get_weather
#city_adcode有城市和adcode
for i in city_adcode:
adcode = i[0]
city_name = i[1]
get_weather(adcode,city_name)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537',
'X-Requested-With': 'XMLHttpRequest',
}
main()