python入门篇6:文本/CSV/Excel/word文件操作
2、CSV文件操作
2.1、从csv中读取文件
import csv
def read_csv_index():
"""通过下标的方式"""
with open('stock.csv', 'r') as f:
# csv.reader()返回的是一个迭代器,这里的迭代器是列表
reader = csv.reader(f)
# 一般不想使用标题行使用next(reader)
next(reader) # 表示第一行开始,不是从第0行开始
for x in reader:
name = x[3]
volumn = x[-1]
print(name, volumn)
def read_csv_dict():
"""通过字典的方式读取csv文件"""
with open("stock.csv","r") as f:
# csv.DictReader()返回的是一个迭代器,这里的迭代器是字典
# DictReader()不会包含标题行的数据
reader = csv.DictReader(f)
for d in reader:
name = d['secShortName']
volumn = d['turnoverVol']
print(name, volumn)
if __name__ == '__main__':
read_csv_dict()【例子】
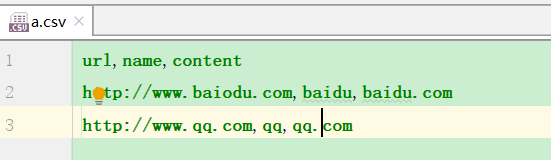
import csv
with open("a.csv","r") as f:
# 文件中的第一行会自动作为标题行处理,并且会根据他们得出字典中键的名称
reader = csv.DictReader(f)
for line in reader: # OrderedDict([('url', 'http://www.baiodu.com'), ('name', 'baidu'), ('content', 'baidu.com')])
print(line.pop('url'),line.pop('name'),line.pop('content'))
2.2、写入csv文件中
import csv
def write_csv():
# 第一行的标题
csv_headers = ['name', 'age', 'classroom']
values = [ ('zhangsan', 19, '508'),
('zhaosi', 20, '902'),
('wangwu', 32, '603')]
# newline参数默认值是newline='\n'
with open("test.csv",'w',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
# 写入文件标题
writer.writerow(csv_headers)
# writerows()一次写入多行数据
writer.writerows(values)
def write_csv_dict():
"""使用字典的方式把数据写入csv文件中"""
csv_headers=['name','age','room']
# 列表中存放的是字典
values = [
{'name':'zhangsan','age':19,'room':'508'},
{'name':'zhaosi','age':20,'room':'902'},
{'name':'wangwu','age': 32,'room':'603'}
]
with open("test.csv", 'w', encoding='utf-8',newline='') as f:
writer= csv.DictWriter(f,csv_headers)
# 写入文件标题
writer.writeheader()
# writerows()一次写入多行数据
writer.writerows(values)
if __name__ == '__main__':
write_csv_dict()2.3、不使用csv模块追加写入文件
def save_data(self,content,code):
with open("面上项目.csv","a+",encoding="utf-8") as f:
for i in content:
csv_list = []
csv_list.append(code) # 申请代码
csv_list.append(i[1]) # 项目名称
csv_list.append(i[3]) # 项目类别
csv_list.append(i[4]) # 依托单位
csv_list.append(i[5]) # 负责人
csv_list.append(i[7]) # 年份
f.write(','.join(csv_list))
f.write("\n")
print("完成",code,"申请编号")
pass3、openpyxl操作excel
3.1、创建excel文档
import openpyxl
data = openpyxl.Workbook() # 新建工作簿
data.create_sheet('Sheet1') # 添加工作簿
#table = data.get_sheet_by_name('Sheet1') # 获得指定名称页
table = data.active # 获得当前活跃的工作页,默认为第一个工作页
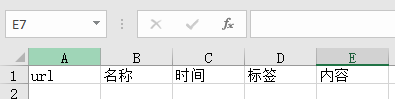
table.cell(1,1,'url') # 行,列,值 这里是从1开始计数的
table.cell(1,2,'名称')
table.cell(1,3,'时间')
table.cell(1,4,'标签')
table.cell(1,5,'内容')
data.save('test.xlsx') # 一定要保存
3.2、追加写入excel文档中
import openpyxl
wb = openpyxl.load_workbook('test.xlsx')
# print(data.get_named_ranges()) # 输出工作页索引范围
# print(data.get_sheet_names()) # 输出所有工作页的名称
# 取第一张表
sheetnames = wb.sheetnames #wb.sheetnames获取所有表格的名称
table = wb[sheetnames[0]] # wb['工作簿名称']表示通过表格名称获取Worksheet对象
table = wb.active # 获取活跃的表格
# wb.remove(worksheet) or del wb[sheetname]删除一个表格
# print(table.title) # 输出表名
nrows = table.max_row # 获得行数
ncolumns = table.max_column # 获得行数
values = [
{'url':'http://www.bidchance.com/info-zhongbiao-26052140.html','name':'Guangan20190717101142001','date':'2019年07月17日','tag':'空调招标 街招标','content':'项目信息'},
{'url':'http://www.bidchance.com/info-zhongbiao-26052141.html','name':'Guangan20190717101142002','date':'2019年07月18日','tag':'空调招标 街招标2','content':'项目信息2'},
{'url':'http://www.bidchance.com/info-zhongbiao-26052142.html','name':'Guangan20190717101142003','date':'2019年07月19日','tag':'空调招标 街招标3','content':'项目信息3'},
{'url':'http://www.bidchance.com/info-zhongbiao-26052143.html','name':'Guangan20190717101142004','date':'2019年07月20日','tag':'空调招标 街招标4','content':'项目信息4'},
{'url':'http://www.bidchance.com/info-zhongbiao-26052144.html','name':'Guangan20190717101142005','date':'2019年07月21日','tag':'空调招标 街招标5','content':'项目信息5'},
]
for value in values:
table.cell(nrows+1,1).value = value['url']
table.cell(nrows + 1, 2).value = value['name']
table.cell(nrows + 1, 3).value = value['date']
table.cell(nrows+1,4).value = value['tag']
table.cell(nrows + 1, 5).value = value['content']
nrows = nrows + 1
wb.save('test.xlsx')
4、word操作
首先我们需要安装python-docx,也就是pip install python-docx。学习可以参考https://www.jianshu.com/p/30b49d0322a9这个页面。
# coding:utf-8
# pip install python-docx
from docx import Document
from docx.shared import Inches
document = Document() # #创建一个文档
document.add_heading(u'Python 操作Word实例示例', level=1) #直接添加标题,参数level表示几级标题,越小越大
#先定义标题,再添加内容
p_total = document.add_heading()
r_total = p_total.add_run("这是一个table表格")
r_total.font.bold = True # bold表示加粗,italic表示斜体
# 增加表格
# table = document.add_table(rows=1, cols=3)
table = document.add_table(rows=1, cols=3, style="Light List Accent 5") # style表示表格边框颜色
# 设置表格表头
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'testName'
hdr_cells[1].text = 'param'
hdr_cells[2].text = 'exc'
for i in range(3):
i = i + 1
testName = "testName"+str(i)
param = "param"+str(i)
exc="exc"+str(i)
row_cells = table.add_row().cells
row_cells[0].text = testName
row_cells[1].text = param
row_cells[2].text = exc
#添加二级标题
p_total = document.add_heading("", level=2)
r_total = p_total.add_run("这是一个二级标题")
r_total.font.bold = True # 加粗
r_total.italic = True # 斜体
img_name = "D:/test.jpg"
# width=Inches(0.5) 中的Inches表示多少英寸
document.add_picture(img_name, width=Inches(5)) # 向文档里添加图片
# document.add_picture(img_name)
paragraph = document.add_paragraph('啊,这是一个例子')#添加一个段落
# run = paragraph.add_run('bold')
# run.bold = True # bold字体加粗
# run.italic = True # bold字斜体
# prior_paragraph = paragraph.insert_paragraph_before('啊,这')#在某处插入一个段落
document.save("D:/test.docx") # 保存文档
【效果】
