java 爬虫 网页解析(Jsoup)
上一篇演示了怎样使用HttpClient建立连接获取网页内容,接下来展示使用第三方开源分析工具Jsoup对获取到的网页进行分析,爬取需要的信息。
一、Jsoup
Jsoup是一款Java的HTML解析器,可以直接解析某个URI地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出需要的网页内容和信息。下载地址:http://jsoup.org/download
在使用Jsoup解析HTML文本文件前,需要对HTML文本格式有一些了解。如果你已经熟悉HTML直接跳到“二、解析过程”。一个HTML文本文档是由若干的标签组标记成,这些标签当中含有单标签和复标签,其中单标签不会再含有子标签,而复标签可以含有若干个子标签。基于这样的模型,整个HTML文档构成一棵DOM树,就文档来看(浏览器解析时根节点是document),这棵树的根标签是。如下的HTML对应的DOM树:
Title

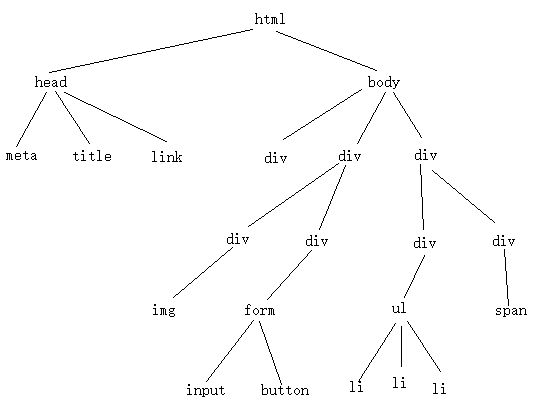
除了理解HTML文档的DOM树模型外,还需要知道标签具有的特征。每一个标签具有自己的特有属性也具有通用属性。如标签具有href特有属性,也含有class、id通用属性。另外就是一个class对应多个标签,而一个id最多对应一个标签,这在解析时是重要的。
二、解析过程
在解析之前需要区分两个对象Element和Elements对象,前者对应一个特定的标签,而后者是一个多标签的集合,该集合中的一个元素是一个Element对象,在解析过程中这两个对象不断的转换。
1、实例化文档对象,参数是一个HTML文本文档通常是String类型的HTML文档(如果需要可以是文件或输入流),这里使用上一篇文章 java HttpClient 爬虫中最后获得的entity对象。
String html=EntityUtils.toString(entity,CHARSET);
//实例文档对象,
Document document = Jsoup.parse(html);2、通过标签名解析。Document和Element对象都提供了getElementsByTag(String tagName)方法,这个方法返回Document或Element下的所有标签名为tagName的标签集合。需要注意的是通过标签名解析时文档中或一个标签下含有多个同名标签。对应的对象是Elements。
//获得文档下所有div标签,返回的是一个标签的集合
Elements elements = document.getElementsByTag("div");
//定义一个标签对象
Element element=null;
//从这一个标签集合中一个一个的取出
for (int i = 0; i < elements.size(); i++) {
element= elements.get(i);
}
//不仅document可以取出所有的div标签,一个标签也可以取出它所有的div子标签
if(element!=null){
Elements newelements=element.getElementsByTag("div");
}3、通过class属性解析。Document和Element对象都提供了getElementsByClass(String className)方法,这个方法返回Document或Element下的所有class通用属性为className的标签集合。需要注意的是通过class属性解析时文档中或一个标签下含有多个class属性相同的标签。对应的对象是Elements。
//获得文档下所有class属性为header的标签,返回的是一个标签的集合
Elements elements = document.getElementsByClass("header");
//定义一个标签对象
Element element=null;
//从这一个标签集合中一个一个的取出
for (int i = 0; i < elements.size(); i++) {
element= elements.get(i);
}
//一个标签也可以取出它所有class属性为header的子标签
if(element!=null){
Elements newelements=element.getElementsByTag("header");
}4、通过id属性解析。Document和Element对象都提供了getElementsById(String id)方法,这个方法返回Document或Element下的一个id通用属性为id的标签。需要注意的是通过id属性解析时文档中或一个标签下最多含有一个id属性为id的标签。对应的对象是Element。
//获得文档下属性id为submit_button的标签
Element element=document.getElementById("submit_button");
//获得一个标签下属性id为submit_button的子标签
element=element.getElementById("submit_button");5、通过子元素解析。Element对象提供了getAllElements()方法,这个方法返回Element下所有的子标签。另外还提供了child(index)方法,这个方法返回该标签中子标签索引为index的子标签,需要注意可能没有会报数组越界错误。
//获得文档下属性id为submit_button的标签
Element element=document.getElementById("main");
//获得标签的所有子标签
Elements elements=element.getAllElements();
//获得标签子标签索引为1个子标签,如果没有可能会报数组越界,因此捕获异常。
try{
element=element.child(1);
}catch (Exception e){
e.printStackTrace();
}6、解析属性。通过以上的步骤介绍了4中解析到标签或标签集合的方法。接下来就来解决怎样获得一个标签属性的值,Element对象提供了attr(String attributeKey)方法获取属性为attributeKey的属性值。
//获得文档下属性id为main的标签
Element element=document.getElementById("main");
//获得element标签的href属性的值,
String href=element.attr("href");7、文本解析。爬取网页很多时候需要的是网页上的文本,Element对象提供了text()方法获取该标签下(不仅是一层)的所有文本内容。
//获得文档下属性id为main的标签
Element element=document.getElementById("main");
//获得element标签下的所有文本
String text=element.text();到这里基本上就能完成网页的爬虫,在网页的爬虫过程中结合使用上面6中解析方法就能很好的解析网页了。