2019独角兽企业重金招聘Python工程师标准>>> 
1、消息的持久化
默认情况下,队列和交换器在服务器重启后都会消失,消息当然也是。将队列和交换器的durable属性设为true,缺省为false,但是消息要持久化还不够,还需要将消息在发布前,将投递模式设置为2。消息要持久化,必须要有持久化的队列、交换器和投递模式都为2。
注意:将所有的消息都设为持久化,会严重影响 RabbitMQ 的性能。写入磁盘的速度比写入内存的速度慢得不只一点点。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吐吞量之间做一个权衡。
将交换器、队列、消息都设置了持久化之后就能百分之百保证数据不丢失了吗? 答案是否定的
在持久化的消息正确存入 RabbitMQ 之后,还需要有一段时间(虽然很短,但是不可忽视〉才能存入磁盘之中。 RabbitMQ 并不会为每条消息都进行同步存盘(调用内核的 fsync方法)的处理,可能仅仅保存到操作系统缓存之中而不是物理磁盘之中。如果在这段时间内RabbitMQ 服务节点发生了岩机、重启等异常情况,消息保存还没来得及落盘,那么这些消息将会丢失。这时候就需要rabbitmq服务做到高可用:镜像队列。
交换机设置
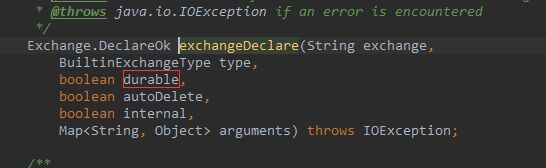
队列设置

消息设置

2、消息的获取方式
拉取Get:
属于一种轮询模型,发送一次get请求,获得一个消息。如果此时RabbitMQ中没有消息,会获得一个表示空的回复。
总的来说,这种方式性能比较差,很明显,每获得一条消息,都要和RabbitMQ进行网络通信发出请求。
而且对RabbitMQ来说,RabbitMQ无法进行任何优化,因为它永远不知道应用程序何时会发出请求。
对我们实现者来说,要在一个循环里,不断去服务器get消息。
//消费者1
@Slf4j
public class Consumer1 {
public static void main(String[] argv) throws Exception {
String queueName = "hello_direct_c1";
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 定义队列的消费者
while(true){
GetResponse getResponse =
channel.basicGet(queueName, true);
if(null!=getResponse){
log.debug("get message:{}",new String(getResponse.getBody()));
}
Thread.sleep(1000);
}
}
}推送Consume
属于一种推送模型。注册一个消费者后,RabbitMQ会在消息可用时,自动将消息进行推送给消费者。前面的文章中使用的都是这种方式,也是建议使用的一种方式。
3、消息的预取模式
声明交换机队列并绑定
/**
* 1、声明交换机、队列并绑定
*/
@Test
public void decalreExchange() throws Exception {
String exchange = "hello_qos";
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明exchange,指定类型为direct
channel.exchangeDeclare(exchange, BuiltinExchangeType.DIRECT,true,false,false,new HashMap<>());
String queueName = "hello_qos_c";
// 声明队列
channel.queueDeclare(queueName, true, false, false, null);
// 绑定队列到交换机
String routingKey = "aaa";
channel.queueBind(queueName, exchange, routingKey,null);
}
消费者1所在的集群性能强劲,可能花了500ms就处理完一条消息
//消费者1
@Slf4j
public class Consumer1 {
public static void main(String[] argv) throws Exception {
String queueName = "hello_qos_c";
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
log.error("error:",e);
}
log.debug("Consumer1 consume msg:{}",msg);
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
// 监听队列,自动返回完成
channel.basicConsume(queueName, false, consumer);
}
}消费者2所在机器性能一般,需要2000ms才能消费完一条消息。
// 消费者2
@Slf4j
public class Consumer2 {
public static void main(String[] argv) throws Exception {
String queueName = "hello_qos_c";
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
log.error("error:",e);
}
log.debug("Consumer2 consume msg:{}",msg);
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
// 监听队列,自动返回完成
channel.basicConsume(queueName, false, consumer);
}
}分别启动两个消费者,并向队列hello_qos发送20条消息
/**
* 生产者发送消息
* @throws Exception
*/
@Test
public void sendMessage() throws Exception {
String exchange = "hello_qos";
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
for (int i = 1;i <= 20;i++){
// 消息内容
String message1 = "Less is more direct " + i;
// 发布消息到Exchange 指定路由键
channel.basicPublish(exchange, "aaa", null, message1.getBytes());
}
channel.close();
connection.close();
}
消费者1和消费者2都收掉了10条消息,由此可见,rabbitmq 是通过轮询的方式均匀的把消息发送给消费者。
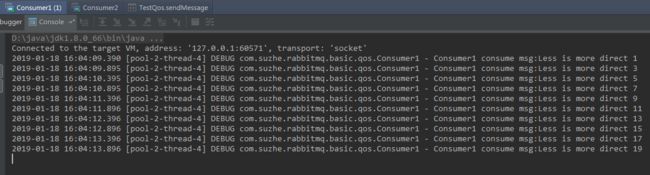

现在的状态属于是把任务平均分配,正确的做法应该是消费越快的人,消费的越多。
怎么实现呢?
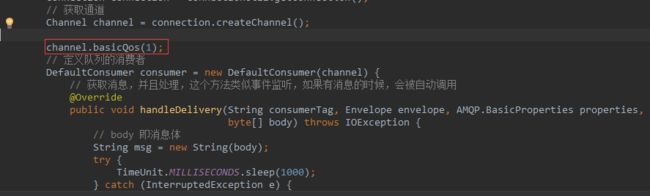
我们可以使用basicQos方法和prefetchCount = 1设置。 这告诉RabbitMQ一次不要向消费者发送多于一条消息。 或者换句话说,不要向消费者发送新消息,直到它处理并确认了前一个消息。 相反,它会将其分派给不是仍然忙碌的下一个消费者。
在消费者代码中加入下面的代码,重启消费者。
再一次发送消息,可以看到消费能力强的多消费了消息。
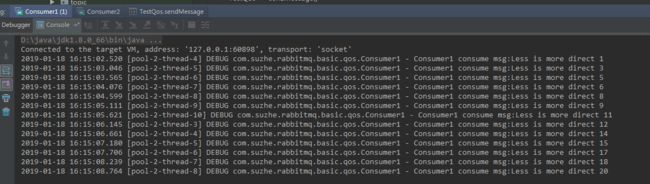
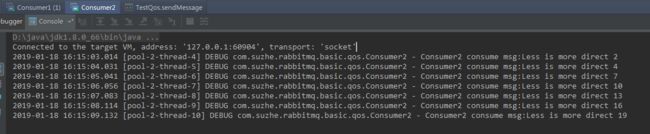
注意:这种机制起到限流的作用,试想,假如大量的消息涌入消费者,可能导致消费者程序的崩溃。
详细源码地址
https://github.com/suzhe2018/rabbitmq-item