逆向最大匹配算法之python实现
1.运行环境
python 3.6.4
2.思路
大致思路与正向相同,可参考我的上一篇博客。
3.代码实现
import codecs
#获得分词字典,存储为字典形式
f1 = codecs.open('./corpus/WordList.txt', 'r', encoding='utf8')
dic = {}
while 1:
line = f1.readline()
if len(line) == 0:
break
term = line.strip() #去除字典两侧的换行符,避免最大分词长度出错
dic[term] = 1
f1.close()
#获得需要分词的文本,为字符串形式
f2 = codecs.open('./corpus/zoo.txt', 'r', encoding='utf8')
chars = f2.read().strip()
f2.close()
#获得停用词典,存储为字典形式
f3 = codecs.open('stop_words.txt', 'r', encoding='utf8')
stoplist = {}
while 1:
line = f3.readline()
if len(line) == 0:
break
term = line.strip()
stoplist[term] = 1
f3.close()
#正向匹配最大分词算法
#遍历分词词典,获得最大分词长度
max_chars = 0
for key in dic:
if len(key) > max_chars:
max_chars = len(key)
#定义一个空列表来存储分词结果
words = []
n = len(chars) #待分词文本的长度
while n > 0:
matched = 0
#range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长 step=-1表示去掉最后一位
for i in range(max_chars, 0, -1): #i等于max_chars到1
if n - i < 0: #若待分词文本长度小于最大字典词长,则终止循环
continue
s = chars[n - i : n] #截取文本字符串n到n+1位
#判断所截取字符串是否在分词词典和停用词词典内
if s in dic:
if s in stoplist: #判断是否为停用词
words.append(s)
matched = 1
n = n - i
break
else:
words.append(s)
matched = 1
n = n - i
break
if s in stoplist:
words.append(s)
matched = 1
n = n - i
break
if not matched: #等于 if matched == 0
words.append(chars[n - 1: n])
n = n - 1
words.reverse()
#分词结果写入文件
f3 = open('RMMResult.txt','w', encoding='utf8')
f3.write('/'.join('%s' %id for id in words))
f3.close()4.运行结果
待分词文本:zoo.txt
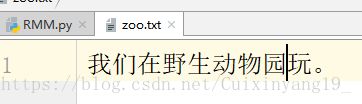
粉刺结果:RMMResult.txt
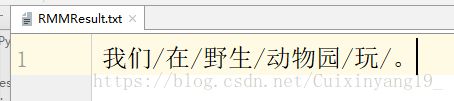
5.参考资料
(1)Python自然语言处理实战 核心技术与算法