一、字符串排序算法比较
本文介绍的排序算法与传统的基于比较的通用排序算法不同,本文主要介绍LSD string sort、MSD string sort以及3-way string quicksort。
这些排序算法都利用了字母表(Alphabet)的概念,时间复杂度通常都是线性的(传统的通用排序算法最佳性能只能达到线性对数级别NlgN),但通常需要额外的空间。
字母表(Alphabet)
本文中,字母表就是给定一个字符集合的字典,保存着字符和索引之间的唯一映射。
如ASCII字母表,每个ASCII字符都有唯一的数值,且根据字符计算数值所需的时间通常是常数级别。
下图是各类排序算法的性能比较:

二、键索引计数法
键索引计数法(key-indexed counting sort),是本文介绍的各类排序算法的基础。该算法仅针对键范围已知的序列(键值需要大于等于0),效率高于通用排序算法。其另一特点是,该算法是稳定的。
2.1 基本思想
假设有一组待排序的键,其值范围在O~R-1之间。
那么通过计算每个键的频率,就可以知道每个键在排序结果中的起始位置:
每个键在排序结果中的起始索引=前一个键的起始索引+前一个键的频次
具体步骤:
- 统计各个键出现的频次,如count[i]表示键i出现的频次;
- 统计每个键k在排序结果中的起始索引
index[k];
index[k] = index[k-1] + count[k-1]; - 遍历原序列的每个元素,按照键的起始索引复制到辅助数组;(由此可知,该排序算法是稳定的)
- 将辅助数组复制回原序列。
源码:
/**
* 键索引计数法排序 假设array数组中键的范围在0~R-1之间
* TODO:优化点,count和index数组可以合并
*/
private void sort(Student[] array, int R) {
int N = array.length;
Student[] aux = new Student[N]; // 辅助数组,保存排序结果
// 1.统计每个键出现的频次
// count[i]表示键i出现的频次
int[] count = new int[R];
for (int i = 0; i < N; i++) {
count[aux[i].key]++;
}
// 2.统计每个键在排序结果中的起始索引
// index[i]表示键i所在的排序结果中的初始索引
int[] index = new int[R];
/**
* index[0] = 0;
* index[1] = index[0] + count[0];
* index[2] = index[1] + count[1];
* ...
* index[k] = index[k-1] + count[k-1];
*/
index[0] = 0;
for (int i = 1; i <= R; i++) {
index[i] = index[i - 1] + count[i - 1];
}
// 3.元素分类
// 遍历原数组中的每一个元素,进行分类
for (int i = 0; i < N; i++) {
// 原数组中的元素array[i]所在排序结果中的位置
int idx = index[array[i].key];
aux[idx] = array[i];
index[array[i].key]++;
}
// 4.回写
for (int i = 0; i < N; i++)
array[i] = aux[i];
}
注:上述代码有很多可以优化的点,但是具体步骤还是上述的4个步骤,具体优化点就是通过复用数组来提供空间利用率,具体可以参见MSD、LSD算法。
三、低位优先法(LSD)
3.1 算法思想
低位优先的字符串排序(Least-Signifcant-Digit First,LSD),仅适用于键长度都相同的序列。
基本步骤:
首先,假设待排序的键长度均相同,设为W。
- 排序时,从键的低位(最右侧)开始,依次向左,先对键的最右一个字符采用键索引计数法进行排序。
- 然后,从右向左以下一个字符作为关键字,用键索引计数法排序,总共需要排序W次。
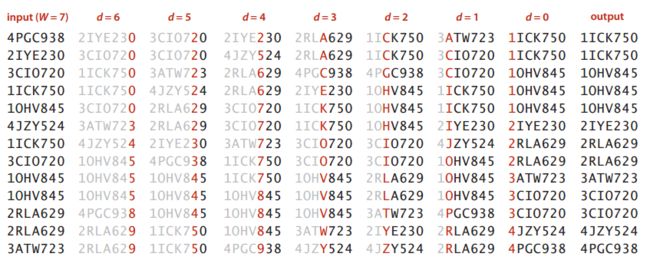
3.2 算法证明
首先,LSD的正确性依赖于键索引计数法是稳定的。
显然,键索引计数法是稳定的(见2.1)。
证明过程:
假设键一共n位(从左到右为0,1,..,k-1,k,…,n-1),在对第k位排序后,k位肯定有序了。此时对进行k-1位排序,k-1位有两种情况:
- k-1位待排序的两个键值相同,此时由于键索引计数法是稳定的,所以k-1位排完后,k位原来的顺序不会改变,如果k是第0位,那整个键就已经有序了;
- k-1位待排序的两个键值不同,此时原来k位的有序性已经没有了意义,因为k-1位排序后,会打乱k位的元素顺序,最终结果以k-1位为准,如果k是第0位,那整个键也已经有序了(虽然此时k位可能是无序的);
综上:
LSD算法的目的就是:
1. 在较高位字符相同的情况下,保持着较低位的顺序;
2. 在较高位字符不同的情况下,保证较高位要有序,此时低位的顺序已经没有意义。
3.3 算法实现
public class LSD {
private LSD() {
}
/**
* LSD算法(每个待排序元素的键长度必须相同)
* @param array 待排序数组
* @param w 键长度
*/
public static void sort(String[] array, int w) {
int N = array.length;
int R = 256; // 键范围
String[] aux = new String[N]; // 辅助数组
// 从右往左,对第k个字符,用键索引计数法排序
for (int k = w - 1; k >= 0; d--) {
// 计算键的频率
int[] count = new int[R + 1];
for (int i = 0; i < n; i++)
count[array[i].charAt(k) + 1]++;
// 计算键排序后的初始索引
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// 元素分类
for (int i = 0; i < n; i++)
aux[count[array[i].charAt(k)]++] = array[i];
// 回写
for (int i = 0; i < n; i++)
array[i] = aux[i];
}
}
public static void main(String[] args) {
String[] a = StdIn.readAllStrings();
int n = a.length;
// check that strings have fixed length
int w = a[0].length();
for (int i = 0; i < n; i++)
assert a[i].length() == w : "Strings must have fixed length";
sort(a, w);
for (int i = 0; i < n; i++)
StdOut.println(a[i]);
}
}
注意:上述代码为了说明LSD的思想,未对键索引计数法优化,优化后的完整代码如下:
public class LSD {
private static final int BITS_PER_BYTE = 8;
private LSD() {
}
/**
* Rearranges the array of W-character strings in ascending order.
*
* @param a the array to be sorted
* @param w the number of characters per string
*/
public static void sort(String[] a, int w) {
int n = a.length;
int R = 256; // extend ASCII alphabet size
String[] aux = new String[n];
for (int d = w - 1; d >= 0; d--) {
// sort by key-indexed counting on dth character
// compute frequency counts
int[] count = new int[R + 1];
for (int i = 0; i < n; i++)
count[a[i].charAt(d) + 1]++;
// compute cumulates
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// move data
for (int i = 0; i < n; i++)
aux[count[a[i].charAt(d)]++] = a[i];
// copy back
for (int i = 0; i < n; i++)
a[i] = aux[i];
}
}
/**
* Rearranges the array of 32-bit integers in ascending order. This is about
* 2-3x faster than Arrays.sort().
*
* @param a the array to be sorted
*/
public static void sort(int[] a) {
final int BITS = 32; // each int is 32 bits
final int R = 1 << BITS_PER_BYTE; // each bytes is between 0 and 255
final int MASK = R - 1; // 0xFF
final int w = BITS / BITS_PER_BYTE; // each int is 4 bytes
int n = a.length;
int[] aux = new int[n];
for (int d = 0; d < w; d++) {
// compute frequency counts
int[] count = new int[R + 1];
for (int i = 0; i < n; i++) {
int c = (a[i] >> BITS_PER_BYTE * d) & MASK;
count[c + 1]++;
}
// compute cumulates
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// for most significant byte, 0x80-0xFF comes before 0x00-0x7F
if (d == w - 1) {
int shift1 = count[R] - count[R / 2];
int shift2 = count[R / 2];
for (int r = 0; r < R / 2; r++)
count[r] += shift1;
for (int r = R / 2; r < R; r++)
count[r] -= shift2;
}
// move data
for (int i = 0; i < n; i++) {
int c = (a[i] >> BITS_PER_BYTE * d) & MASK;
aux[count[c]++] = a[i];
}
// copy back
for (int i = 0; i < n; i++)
a[i] = aux[i];
}
}
/**
* Reads in a sequence of fixed-length strings from standard input; LSD
* radix sorts them; and prints them to standard output in ascending order.
*
* @param args the command-line arguments
*/
public static void main(String[] args) {
String[] a = StdIn.readAllStrings();
int n = a.length;
// check that strings have fixed length
int w = a[0].length();
for (int i = 0; i < n; i++)
assert a[i].length() == w : "Strings must have fixed length";
// sort the strings
sort(a, w);
// print results
for (int i = 0; i < n; i++)
StdOut.println(a[i]);
}
}
四、高位优先法(MSD)
4.1 算法思想
高位优先的字符串排序(Most-Signifcant-Digit First,MSD),可以处理不等长的字符串。
基本步骤:
MSD算法从左向右检查每个字符:
- 先对第一个字符进行键索引计数排序,排序后将所有首字符相同的归为一个子数组
- 然后对每个子数组分别按照步骤1进行递归排序。

注意:在对各个子数组进行排序时,需要特别注意到达字符串末尾的情况。
比如“RON”和“RONG”,显然“RON”应小于“RONG”,所以字符串末尾在字符集中对应的整数应该最小。
为此定义一个特殊方法charAt,用来映射键字符和整数值,当索引达到字符串末尾时,默认为最小键0。
4.2 算法实现
public class MSD {
// 字符集大小,即基数
private static final int R = 256;
// 切换为插入排序时,子字符串数组大小
private static final int M = 15;
public static void sort(String[] array) {
int N = array.length;
String[] aux = new String[N];
sort(array, aux, 0, N - 1, 0);
}
/**
* MSD排序的递归方法. 即对array[start...end]中的每个字符串,按照第index个字符进行键索引计数排序
*
* @param array 待排序子序列
* @param aux 辅助数组
* @param start 子序列起始索引
* @param end 子序列结束索引
* @param index 子序列中运用键索引计数排序的字符索引位置,从0开始计
*/
private static void sort(String[] array, String[] aux, int start, int end, int index) {
// 对于小型数组,切换到插入排序
if (start + M >= end) {
insertSort(array, start, end, index);
return;
}
// 1.频数统计
int[] count = new int[R];
for (int i = start; i <= end; i++) {
count[charAt(array[i], index)]++;
}
// 2.转换为键在排序结果中的起始索引
// 注意array数组的起始位置是start
int[] idx = new int[R];
idx[0] = start;
for (int i = 1; i < R; i++) {
idx[i] = idx[i - 1] + count[i - 1];
}
// 3.复制排序结果至辅助数组
for (int i = start; i <= end; i++) {
aux[idx[charAt(array[i], index)]++] = array[i];
}
// 4.回写排序结果
for (int i = start; i <= end; i++) {
array[i] = aux[i];
}
// 递归处理首字符相同的子数组
// 此时idx保存的是每个键的结束索引+1
for (int i = 0; i < R; i++) {
sort(array, aux, idx[i] - count[i], idx[i] - 1, index + 1);
}
}
// 计算字符串在索引index的字符键值
private static int charAt(String s, int index) {
assert index >= 0;
if (index >= s.length())
return 0;
return s.charAt(index) + 1;
}
// 对array[start...end]中的字符串,进行插入排序
private static void insertSort(String[] array, int start, int end, int index) {
for (int i = start + 1; i <= end; i++) {
for (int j = i; j > start && less(array[j], array[j - 1], index); j--) {
exchange(array, j, j - 1);
}
}
}
private static void exchange(String[] array, int i, int j) {
String temp = array[i];
array[i] = array[j];
array[j] = temp;
}
private static boolean less(String s1, String s2, int index) {
// assert s1.substring(0, index).equals(s2.substring(0, index));
for (int i = index; i < Math.min(s1.length(), s1.length()); i++) {
if (s1.charAt(i) < s2.charAt(i))
return true;
if (s1.charAt(i) > s2.charAt(i))
return false;
}
return s1.length() < s2.length();
}
}
注意:上述代码为了说明LSD的思想,未对键索引计数法优化,优化后的完整代码如下:
public class MSD {
private static final int BITS_PER_BYTE = 8;
private static final int BITS_PER_INT = 32; // each Java int is 32 bits
private static final int R = 256; // extended ASCII alphabet size
private static final int CUTOFF = 15; // cutoff to insertion sort
// do not instantiate
private MSD() { }
/**
* Rearranges the array of extended ASCII strings in ascending order.
*
* @param a the array to be sorted
*/
public static void sort(String[] a) {
int n = a.length;
String[] aux = new String[n];
sort(a, 0, n-1, 0, aux);
}
// return dth character of s, -1 if d = length of string
private static int charAt(String s, int d) {
assert d >= 0 && d <= s.length();
if (d == s.length()) return -1;
return s.charAt(d);
}
// sort from a[lo] to a[hi], starting at the dth character
private static void sort(String[] a, int lo, int hi, int d, String[] aux) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
// compute frequency counts
int[] count = new int[R+2];
for (int i = lo; i <= hi; i++) {
int c = charAt(a[i], d);
count[c+2]++;
}
// transform counts to indicies
for (int r = 0; r < R+1; r++)
count[r+1] += count[r];
// distribute
for (int i = lo; i <= hi; i++) {
int c = charAt(a[i], d);
aux[count[c+1]++] = a[i];
}
// copy back
for (int i = lo; i <= hi; i++)
a[i] = aux[i - lo];
// recursively sort for each character (excludes sentinel -1)
for (int r = 0; r < R; r++)
sort(a, lo + count[r], lo + count[r+1] - 1, d+1, aux);
}
// insertion sort a[lo..hi], starting at dth character
private static void insertion(String[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && less(a[j], a[j-1], d); j--)
exch(a, j, j-1);
}
// exchange a[i] and a[j]
private static void exch(String[] a, int i, int j) {
String temp = a[i];
a[i] = a[j];
a[j] = temp;
}
// is v less than w, starting at character d
private static boolean less(String v, String w, int d) {
// assert v.substring(0, d).equals(w.substring(0, d));
for (int i = d; i < Math.min(v.length(), w.length()); i++) {
if (v.charAt(i) < w.charAt(i)) return true;
if (v.charAt(i) > w.charAt(i)) return false;
}
return v.length() < w.length();
}
/**
* Rearranges the array of 32-bit integers in ascending order.
* Currently assumes that the integers are nonnegative.
*
* @param a the array to be sorted
*/
public static void sort(int[] a) {
int n = a.length;
int[] aux = new int[n];
sort(a, 0, n-1, 0, aux);
}
// MSD sort from a[lo] to a[hi], starting at the dth byte
private static void sort(int[] a, int lo, int hi, int d, int[] aux) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
// compute frequency counts (need R = 256)
int[] count = new int[R+1];
int mask = R - 1; // 0xFF;
int shift = BITS_PER_INT - BITS_PER_BYTE*d - BITS_PER_BYTE;
for (int i = lo; i <= hi; i++) {
int c = (a[i] >> shift) & mask;
count[c + 1]++;
}
// transform counts to indicies
for (int r = 0; r < R; r++)
count[r+1] += count[r];
// distribute
for (int i = lo; i <= hi; i++) {
int c = (a[i] >> shift) & mask;
aux[count[c]++] = a[i];
}
// copy back
for (int i = lo; i <= hi; i++)
a[i] = aux[i - lo];
// no more bits
if (d == 4) return;
// recursively sort for each character
if (count[0] > 0)
sort(a, lo, lo + count[0] - 1, d+1, aux);
for (int r = 0; r < R; r++)
if (count[r+1] > count[r])
sort(a, lo + count[r], lo + count[r+1] - 1, d+1, aux);
}
// TODO: insertion sort a[lo..hi], starting at dth character
private static void insertion(int[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && a[j] < a[j-1]; j--)
exch(a, j, j-1);
}
// exchange a[i] and a[j]
private static void exch(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
/**
* Reads in a sequence of extended ASCII strings from standard input;
* MSD radix sorts them;
* and prints them to standard output in ascending order.
*
* @param args the command-line arguments
*/
public static void main(String[] args) {
String[] a = StdIn.readAllStrings();
int n = a.length;
sort(a);
for (int i = 0; i < n; i++)
StdOut.println(a[i]);
}
}
4.3 性能分析
高位优先(LSD)的字符串排序,其性能取决于数据,即键对应的值:
- 最坏情况
所有的键都相同,其性能和低位优先的字符串排序类似(大量含有相同前缀的键也会引起相同的问题); - 最好情况
只需要遍历数据一轮。
另外,在子数组较小时,可以切换为其它排序方法(如插入排序),以提升性能。
五、三向字符串快速排序
5.1 基本思想
三向字符串快速排序(3-way string quicksort),是对高位优先(MSD)的字符串排序(Most-Signifcant-Digit First)的改进。
基本步骤:
该算法将字符串数组切分成三个子数组:
- 一个含有所有首字母小于切分字符的子数组;
- 一个含有所有首字母等于切分字符的子数组;
- 一个含有所有首字母大于切分字符的子数组;
然后,递归地对这三个数组排序,对于所有首字母等于切分字符的子数组,在递归排序时忽略首字母(就像MSD中那样)。

5.2 算法实现
public static void sort(String[] a) {
StdRandom.shuffle(a); // 打乱数组
sort(a, 0, a.length - 1, 0);
}
// 3-way string quicksort a[lo..hi] starting at dth character
private static void sort(String[] a, int lo, int hi, int d) {
// 当子字符串数组的量很小时,切换为插入排序以提高性能
if (lo + M >= hi) {
insertion(a, lo, hi, d);
return;
}
int lt = lo, gt = hi, i = lo + 1;
// 查找字符表得到字符对应的唯一键值,并以此为基数
int v = charAt(a[lo], d);
while (i <= gt) {
int t = charAt(a[i], d);
if (t < v)
exch(a, lt++, i++);
else if (t > v)
exch(a, i, gt--);
else
i++;
}
// a[lo..lt-1] < v = a[lt..gt] < a[gt+1..hi].
sort(a, lo, lt - 1, d);
// a[lt..gt]之间都是d索引处等于v的键.
// 如果v<0,说明已经达到字符串末尾,不需要再进行三向切分
if (v >= 0)
sort(a, lt, gt, d + 1);
sort(a, gt + 1, hi, d);
}
// return the dth character of s, -1 if d = length of s
private static int charAt(String s, int d) {
if (d == s.length())
return -1;
return s.charAt(d);
}

完整源码:
public class Quick3string {
private static final int CUTOFF = 15; // cutoff to insertion sort
private Quick3string() { }
/**
* Rearranges the array of strings in ascending order.
*
* @param a the array to be sorted
*/
public static void sort(String[] a) {
StdRandom.shuffle(a);
sort(a, 0, a.length-1, 0);
assert isSorted(a);
}
// return the dth character of s, -1 if d = length of s
private static int charAt(String s, int d) {
assert d >= 0 && d <= s.length();
if (d == s.length()) return -1;
return s.charAt(d);
}
// 3-way string quicksort a[lo..hi] starting at dth character
private static void sort(String[] a, int lo, int hi, int d) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
int lt = lo, gt = hi;
int v = charAt(a[lo], d);
int i = lo + 1;
while (i <= gt) {
int t = charAt(a[i], d);
if (t < v) exch(a, lt++, i++);
else if (t > v) exch(a, i, gt--);
else i++;
}
// a[lo..lt-1] < v = a[lt..gt] < a[gt+1..hi].
sort(a, lo, lt-1, d);
if (v >= 0) sort(a, lt, gt, d+1);
sort(a, gt+1, hi, d);
}
// sort from a[lo] to a[hi], starting at the dth character
private static void insertion(String[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && less(a[j], a[j-1], d); j--)
exch(a, j, j-1);
}
// exchange a[i] and a[j]
private static void exch(String[] a, int i, int j) {
String temp = a[i];
a[i] = a[j];
a[j] = temp;
}
// is v less than w, starting at character d
private static boolean less(String v, String w, int d) {
assert v.substring(0, d).equals(w.substring(0, d));
for (int i = d; i < Math.min(v.length(), w.length()); i++) {
if (v.charAt(i) < w.charAt(i)) return true;
if (v.charAt(i) > w.charAt(i)) return false;
}
return v.length() < w.length();
}
// is the array sorted
private static boolean isSorted(String[] a) {
for (int i = 1; i < a.length; i++)
if (a[i].compareTo(a[i-1]) < 0) return false;
return true;
}
/**
* Reads in a sequence of fixed-length strings from standard input;
* 3-way radix quicksorts them;
* and prints them to standard output in ascending order.
*
* @param args the command-line arguments
*/
public static void main(String[] args) {
// read in the strings from standard input
String[] a = StdIn.readAllStrings();
int n = a.length;
// sort the strings
sort(a);
// print the results
for (int i = 0; i < n; i++)
StdOut.println(a[i]);
}
}
5.3 性能分析
优点:
- 三向字符串快速排序,能够很好处理等值键、有效长公共前缀的键、取值范围较小的键和小数组——所有MSD排序算法不擅长的各种情况。
- 三向字符串快速排序不需要额外的空间,它相当与是三向快速排序和MSD的结合体。
缺点:
由于是基于快速排序,所以算法是不稳定的。
算法可优化点:
- 随机化
即在排序前,最好打乱数组或者将数组的第一个元素和一个随机位置的元素交换,以得到一个随机的切分元素,这样可以预防数组已经有序或者接近有序的最坏情况。 - 小型子数组
当递归调用至待处理的子数组较小时,可以转换为插入排序,以提高性能。