Python 结巴分词——自然语言处理之中文分词器
jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
jieba分词支持三种分词模式:
1. 精确模式, 试图将句子最精确地切开,适合文本分析:
2. 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3. 搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词。
一 结巴分词的安装
pip3 install jieba
二 结巴分词的主要功能
1. jieba.cut:该方法接受三个输入参数:
参数1:需要分词的字符串;
参数2:cut_all参数用来控制是否采用全模式,默认为精确模式;
cut_all=True 全模式
cut_all=false 精确(默认)模式
参数3:HMM参数用来控制是否适用HMM模型
2. jieba.cut_for_search:该方法接受两个参数:
参数1:需要分词的字符串;
参数2:是否使用HMM模型,
该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。3. jieba.cut 以及jieba.cut_for_search
返回的结构都是可以得到的generator(生成器)4. jieb.lcut 以及 jieba.lcut_for_search
直接返回list5.jieba.Tokenizer(dictionary=DEFUALT_DICT)
新建自定义分词器,
可用于同时使用不同字典,
jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。三 结巴分词的三种模式
import jieba
text='赵丽颖主演的正午阳光剧,知否知否应是绿肥红瘦'1 全模式 cut_all=True
seq_list=jieba.cut(text,cut_all=True)
print(seq_list) #
print(list(seq_list))
'''
['赵', '丽', '颖', '主演', '的', '正午', '阳光', '剧', '', '', '知', '否', '知', '否', '应', '是', '绿肥', '绿肥红瘦']
''' 2 精确模式 (默认模式) cut_all =False
# 02精确模式
seq_list=jieba.cut(text,cut_all=False)
print(list(seq_list))
'''
['赵丽颖', '主演', '的', '正午', '阳光', '剧', ',', '知否', '知否', '应', '是', '绿肥红瘦']
'''3 搜索引擎模式 cut_for_search
seq_list=jieba.cut_for_search(text,)
print(list(seq_list))
'''
['赵丽颖', '主演', '的', '正午', '阳光', '剧', ',', '知否', '知否', '应', '是', '绿肥', '绿肥红瘦']
'''
四 自定义分词器(jieba.Tokenizer)
1 创建词典内容的格式
一个词语占一行(分三部分)
格式: 词语 词频 词性
如:张三 5
李四 10 eng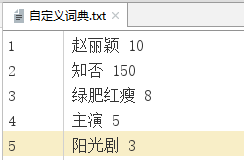
2 自定义词典的导入(load_userdict)
text='赵丽颖主演的正午阳光剧,知否知否应是绿肥红瘦'
# 自定义词典
jieba.load_userdict('自定义词典.txt')
sep_list=jieba.lcut(text)
print('userdict>>>',sep_list)
userdict>>> ['赵丽颖', '主演', '的', '正午', '阳光剧', ',', '知否', '知否', '应是', '绿肥红瘦']
五 利用jieba 进行关键词的抽取
1 基于TF-IDF算法的关键词抽取
详解自然语言处理之TF-IDF模型和python实现
2 python 实现关键提取
jieba.analyse.extract_tags(text,topK=20,withWeight=False,allowPOS=())
'''
text:为待提取的文本;
topK:返回几个TF/IDF权重最大的关键字,默认值为20;
withWeight:是否一并返回关键词权重值,默认False;
'''
jieba.analyse.TFIDF(idf_path=None) #新建tf-idf实例,idf_path为IDF实例
五 使用结巴的词云实例
1 数据准备
文档:
死了都要爱
不淋漓尽致不痛快
感情多深只有这样
才足够表白
死了都要爱
不哭到微笑不痛快
宇宙毁灭心还在
把每天当成是末日来相爱
一分一秒都美到泪水掉下来
不理会别人是看好或看坏
只要你勇敢跟我来
爱不用刻意安排
凭感觉去亲吻相拥就会很愉快
享受现在别一开怀就怕受伤害
许多奇迹我们相信才会存在
死了都要爱
不淋漓尽致不痛快
感情多深只有这样才足够表白
死了都要爱
不哭到微笑不痛快
宇宙毁灭心还在
穷途末路都要爱
不极度浪漫不痛快
发会雪白土会掩埋
思念不腐坏
到绝路都要爱
不天荒地老不痛快
不怕热爱变火海
爱到沸腾才精采英文版:
Dream it possible
I will run, I will climb, I will soar.
I'm undefeated
Jumping out of my skin, pull the chord
Yeah I believe it
The past, is everything we were don't make us who we are
so I'll dream, until I make it real, and all I see is stars
It's not until you fall that you fly
When you dreams come alive you're unstoppable
take a shot, chase the sun, find the beautiful
We will glow in the dark turning dust to gold
And we'll dream it possible
I will chase, I will reach, I will fly
Until I'm breaking, until I'm breaking
Out of my cage, like a bird in the night
I know I'm changing, I know I'm changing
In,into something big, better than before
And if it takes, takes a thousand lives
Then it's worth fighting for图片:(红心.jpg)

# 数据获取
with open('死了都要爱.txt','r',encoding='utf8')as f:
text=f.read()
# with open('dream is possible.txt','r',encoding='utf8')as f:
# text=f.read()
#图片获取
mask=np.array(Image.open('红心.jpg'))
2 数据清洗
屏蔽不需要的数据和分词
# 数据清洗
# 屏蔽死了都要爱
STOPWORDS.add('死了都要爱')
sep_list=jieba.lcut(text,cut_all=False)
sep_list=" ".join(sep_list) #转为字符串自定义画布
wc=WordCloud(
font_path=font,#使用的字体库
margin=2,
mask=mask,#背景图片
background_color='white', #背景颜色
max_font_size=25,
max_words=200,
stopwords=STOPWORDS, #屏蔽的内容
)生成词语,保存图片
wc.generate(text) #制作词云
wc.to_file('新增图片.jpg') #保存到当地文件
3 数据展示
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.show()
完整代码和效果展示
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import jieba
# 数据获取
with open('死了都要爱.txt','r',encoding='utf8')as f:
text=f.read()
# with open('dream is possible.txt','r',encoding='utf8')as f:
# text=f.read()
#图片获取
mask=np.array(Image.open('关羽.jpg'))
# 数据清洗
# 屏蔽死了都要爱
# STOPWORDS.add('死了都要爱')
font=r'C:\Windows\Fonts\simhei.ttf'
sep_list=jieba.lcut(text,cut_all=False)
sep_list=" ".join(sep_list)
wc=WordCloud(
font_path=font,#使用的字体库
margin=2,
mask=mask,#背景图片
background_color='white', #背景颜色
max_font_size=200,
# min_font_size=1,
max_words=200,
# stopwords=STOPWORDS, #屏蔽的内容
)
wc.generate(sep_list) #制作词云
wc.to_file('关羽新增.jpg') #保存到当地文件
# 图片展示
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.show()
图片一(未分词):

图片二(分词效果)

