WebMagic爬虫Demo尝试(二) - 多页面
上篇记录了第一个Demo,使用WebMagic进行了单页面的信息获取,在控制台输出了信息,这次来进行多页面的信息获取,然后存储到数据库,使用Mybatis框架,mysql5.5库
pom.xml,以及log4j的配置参见上文
这里记录mybatis-config.xml的配置以及数据库地址的配置
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3307/webmagic
jdbc.username=root
jdbc.password=123456创建jdbc.propertise文件,写入自己的数据库配置信息,用于连接数据库
配置MyBatis,配置数据源,配置映射的Mapper文件
Mybatis的相关资料以及配置不多赘述,百度很多,直接进入爬虫逻辑类
与上次的单页面信息获取一样,流程依然是:
下载页面 -> 解析页面信息 -> 得到信息处理信息
只不过这次我们需要获取的是多个页面,而不是一个,获取的是多条信息,
为了方便起见,还是先把可能用到的信息初始化了出来,不考虑安全性性能,拿出来用就好
private static csdn_titleUrl_one csdn;
private static csdn_titleUrl_oneService csdnService = new csdn_titleUrl_oneService();
private List allList;
private static String username = "dog250";//需要爬取的用户名信息,可更改,也可设置为手动输入(实现控制台的scanner)
private static int count = 0;//文章总数
private static int number = 1;//当前页码数
private static Spider spider = Spider.create(new getCsdn_TitleAndUrl());
private static String START_URL = "https://blog.csdn.net/" + username + "/article/list/" + number;
private Site site = Site.me()
.setDomain("www.baidu.com")
.setSleepTime(5000)
.setCharset("utf-8")
.setRetrySleepTime(3)
.setTimeOut(1000)//设置超时
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31"); 这次初始化了一个Service类,主要是需要进行数据持久化存储
爬取解析逻辑方面的代码:
public void process(Page page) {
allList = new ArrayList();
List title = page.getHtml().xpath("*[@id=\"mainBox\"]/main/div[2]/div/h4/a/text()").all();//文章标题信息
List url = page.getHtml().xpath("*[@id=\"mainBox\"]/main/div[2]/div/h4/a").links().all();//文章标题URL
for(int i = 0;i 一个页面有多个标题和url信息,所以存入了一个list,然后循环list做数据库的存储,
方法下方一个page.addTargetRequests()方法,这个方法是爬取队列中下一页信息,需要传入一个list参数
这个list里面包含的就是待爬取的页面url,我这里偷懒直接手动组装了一个url集合,代码如下:
/**
* 手工生成listUrl表
*/
public List doListUrl(){
List list = new ArrayList();
for(int i = 2;i<=79;i++) {
list.add("https://blog.csdn.net/" + username + "/article/list/" + i);
}
return list;
} 因为这个博主的博客列表总共就有79页,所以爬取79页就好.
关于Mybatis的相关类也贴上来:
pojo类:
package pojo;
public class csdn_titleUrl_one {
private int id;
private String title;
private String url;
public csdn_titleUrl_one(int id, String title, String url) {
this.id = id;
this.title = title;
this.url = url;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
@Override
public String toString() {
return "csdn_titleUrl_one{" +
"id=" + id +
", title='" + title + '\'' +
", url='" + url + '\'' +
'}';
}
public csdn_titleUrl_one() {
}
}
Service类:
package mapper;
import Util.SqlsessionFactory;
import org.apache.ibatis.session.SqlSession;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
import pojo.csdn_titleUrl_one;
@Service
public class csdn_titleUrl_oneService {
private csdn_titleUrl_oneDao csdn_titleUrl_oneDao;
private SqlSession session;
public csdn_titleUrl_oneService(){
session = SqlsessionFactory.getSessionAutoConmit();
csdn_titleUrl_oneDao = session.getMapper(csdn_titleUrl_oneDao.class);
}
@Resource
public int insert(csdn_titleUrl_one pojo){
return csdn_titleUrl_oneDao.insert(pojo);
}
public int insertList(List< csdn_titleUrl_one> pojos){
return csdn_titleUrl_oneDao.insertList(pojos);
}
public List select(csdn_titleUrl_one pojo){
return csdn_titleUrl_oneDao.select(pojo);
}
public int update(csdn_titleUrl_one pojo){
return csdn_titleUrl_oneDao.update(pojo);
}
}
DAO:
package mapper;
import org.apache.ibatis.annotations.Param;
import java.util.List;
import pojo.csdn_titleUrl_one;
public interface csdn_titleUrl_oneDao {
int insert(@Param("pojo") csdn_titleUrl_one pojo);
int insertList(@Param("pojos") List< csdn_titleUrl_one> pojo);
List select(@Param("pojo") csdn_titleUrl_one pojo);
int update(@Param("pojo") csdn_titleUrl_one pojo);
}
最后是Mapper文件:
id,
title,
url
INSERT INTO csdn_titleUrl_one
id,
title,
url,
VALUES
#{pojo.id},
#{pojo.title},
#{pojo.url},
INSERT INTO csdn_titleUrl_one(
(
#{pojo.id},
#{pojo.title},
#{pojo.url}
)
UPDATE csdn_titleUrl_one
id = #{pojo.id},
title = #{pojo.title},
url = #{pojo.url}
WHERE id = #{pojo.id}
DELETE FROM csdn_titleUrl_one where id = #{pojo.id}
最后贴上爬虫类全代码:
package WebMagicForCSDN;
import mapper.csdn_titleUrl_oneService;
import pojo.csdn_titleUrl_one;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.List;
/**
* 这个类用于演示,测试WebMagic爬虫在爬取多页面,根据页面结构,以及页面跳转的URL进行翻页下一页爬取的操作,
*
* 对于下一页数据的获取方面,CSDN博客的页面底部的按钮没有找到相应的跳转URL,或许是通过js封装跳转的,导致直接获取链接无法完成
*
* 所有使用了一个比较笨的方法,自己手动查看了所有的页数,然后自己根据URL拼接完成了待爬取的页面URL.
*
* 待优化的部分:
* 当前获取页码的形式为写死的,是自己观看了博客页数以后进行的数据获取,
*
* 优化方法:可以在第一次进入页面的时候获取页面底部的最后一页按钮的text文本,转换为int类型,然后赋予全局变量,获取到总页数(待实现)
*/
/**
*2018.9.26更新,整合mybatis,使用mysql5.5对查询出来的数据做了存储
*/
public class getCsdn_TitleAndUrl implements PageProcessor {
private static csdn_titleUrl_one csdn;
private static csdn_titleUrl_oneService csdnService = new csdn_titleUrl_oneService();
private List allList;
private static String username = "dog250";//需要爬取的用户名信息,可更改,也可设置为手动输入(实现控制台的scanner)
private static int count = 0;//文章总数
private static int number = 1;//当前页码数
private static Spider spider = Spider.create(new getCsdn_TitleAndUrl());
private static String START_URL = "https://blog.csdn.net/" + username + "/article/list/" + number;
private Site site = Site.me()
.setDomain("www.baidu.com")
.setSleepTime(5000)
.setCharset("utf-8")
.setRetrySleepTime(3)
.setTimeOut(1000)//设置超时
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
allList = new ArrayList();
List title = page.getHtml().xpath("*[@id=\"mainBox\"]/main/div[2]/div/h4/a/text()").all();//文章标题信息
List url = page.getHtml().xpath("*[@id=\"mainBox\"]/main/div[2]/div/h4/a").links().all();//文章标题URL
for(int i = 0;i doListUrl(){
List list = new ArrayList();
for(int i = 2;i<=79;i++) {
list.add("https://blog.csdn.net/" + username + "/article/list/" + i);
}
return list;
}
public static void ioWrite(String str,int number) throws Exception {
File file = new File("D:" + File.separator+ "WebMagic/CSDN_dog250" + number +".txt");
OutputStream out = null;
try {
out = new FileOutputStream(file);
byte[] data = str.getBytes();
out.write(data);
}catch (Exception e){
e.printStackTrace();
}finally {
out.close();
}
}
}
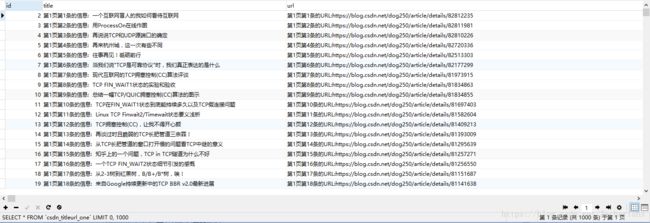
以及最后运行后存入到数据库的数据: