【一、项目背景】
有道翻译作为国内最大的翻译软件之一,用户量巨大。在学习时遇到不会的英语词汇,会第一时间找翻译,有道翻译就是首选。今天教大家如何去获取有道翻译手机版的翻译接口。
【二、项目目标】
多国语言的翻译,可以翻译词语或者句子。
【三、涉及的库和网站】
1、网址如下:
http://m.youdao.com/translate2、涉及的库:requests、lxml
3、软件:PyCharm
【四、项目分析】
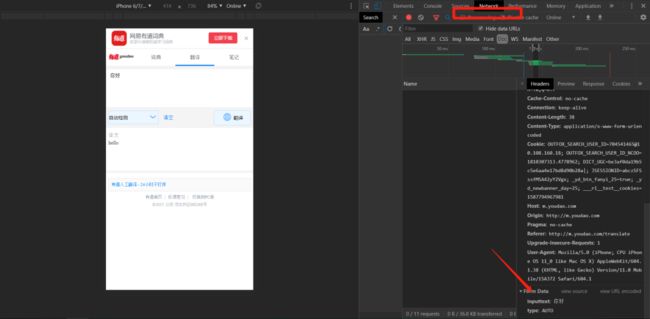
1、点击F12,点击蓝色窗口切换成手机模式,运行进入开发者模式,点击network,找到headers下面的form Data。
2、输翻译的词语点击翻译按钮,可以看到这里有两个参数,一个是inputtext(输入的词语),一个是type(代表语种)。
3、构架一个表单传入这两个参数,通过改变参数的类型,从而 实现多国的翻译。
4、通过返回的页面进行xpath解析数据。
【五、项目实施】
1、导入需要库,创建一个名为YoudaoSpider的类,定义一个初始化方法init。
import requests
from lxml import etree
class YoudaoSpider(object):
def __init__(self):{
}
if __name__ == '__main__':
spider = YoudaoSpider()2、准备url地址,请求头headers。
'''准备url地址'''
self.trans_url="http://m.youdao.com/translate"
'''请求头'''
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"3、定义get_result方法,传入两个参数,构架表单。
def get_result(self, word, fro):
'''构造一个form表单数据---表单是一个字典'''
data = {
'inputtext': word,
'type': fro
}4、发送请求, 获取响应,遍历得到的结果。
response = requests.post(url=self.trans_url, data=data, headers=self.headers)
html = response.content.decode('utf-8')
pa = etree.HTML(html)
# print(html)
pa_list = pa.xpath("//div[@class='generate']/ul/li/text()")
for i in pa_list:
print("翻译为:" + i)5、判断输入的语种类型,调用get_result方法。
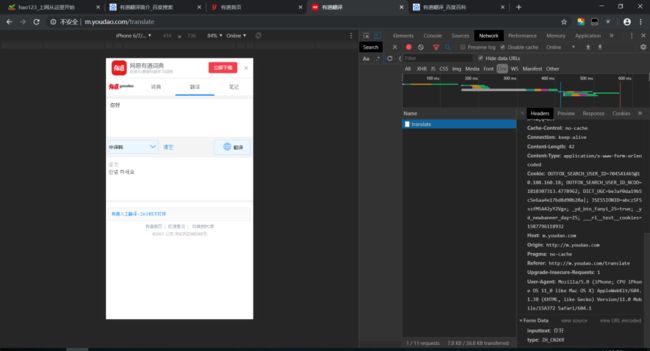
点击切换语种就可以看得到各国的type类型。例如(中译韩):
choice = input("1.中翻译英语 2.中翻韩语 3.把中文翻译法语 \n请选择1/2/3:\n")
if choice == '1':
fro = 'ZH_CN2EN'
elif choice == '2':
fro = 'ZH_CN2SP'
elif choice == '3':
fro = 'ZH_CN2FR'
word = input("请输入你要翻译的单词或句子:")
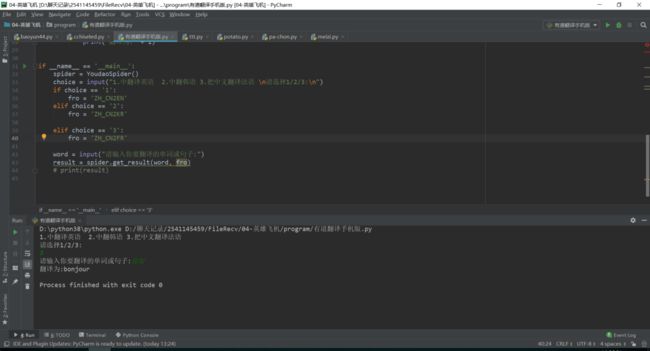
result = spider.get_result(word, fro)【六、效果展示】
1、输入你要翻译的类型。
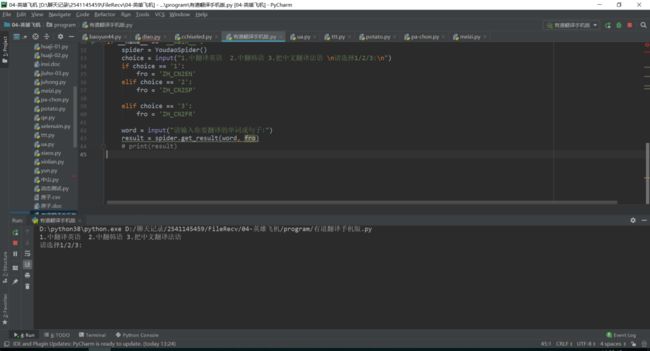
2、输入你要翻译的句子。
【七、总结】
1、本文基于Python网络爬虫,利用爬虫库,获取有道翻译的接口。
2、请求接口时构架表单问题进行了详细的讲解。并提供了解决方案。
3、大家可以尝试的去翻译其他的语言,能够更好的理解爬虫的原理。
4、自己尝试一下,你会发现你也可以 (世上无难事,只怕有心人)。
5、需要本文源码的小伙伴,后台回复“有道词典”四个字,即可获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】
