python中rabbitMQ的使用
rabbitMQ在python中的使用
(1)实现简单的生产者和消费者模型
生产者:当启动publishs的时候,生产者则会创建一个连接,申明一个管道去定义一个queue,queue定义的名字是task_mess,然后在这个queue中发送body消息,等待着消费者接收该管道里面queue=task-mess队列里面的消息。

import pika
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue
channel.queue_declare(queue='task_mess')
#通过管道发送消息
channel.basic_publish(exchange='',
routing_key='task_mess',
body='Hello World!2222222')
print("消息以及发送到subscribe端")
connection.close()
消费者:当启动subscribe的时候,消费者则会创建一个连接,申明一个管道去定义一个queue,queue定义的名字是task_mess,然后在这个queue中等待生产者发送的消息,当消息接收到就会调用callback函数,执行里面的处理。

import pika
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue
channel.queue_declare("task_mess")
def callback(ch,method,properties,body):
#ch 是申明的管道的内存地址
#method 吧消息发给谁的处理信息
#properties序列化
#body publish端发来的信息
print("subscribe端已经接收到消息正在处理~~~",body)
print("%s:ch,%s:method,%s:properties"%(ch,method,properties))
#管道接收消息
channel.basic_consume("task_mess",callback)
channel.start_consuming()
(2)RabbitMQ消息是通过轮询的方式分发任务的
当有一个生产者(publish)和多个消费者(subscribe,subscribe1,subscribe2)的时候(一对多),生产者的执行顺序就是按照先开启先接收的原则,直到所有的消费者都分配到消息的时候,重新从第一个执行的消费者开始继续接收消息。(当我启动消费者的顺序是subscribe,subscribe1,subscribe2当publish来消息的时候,subscribe先接收任务,然后subscribe1接收任务,最后是subscribe2接收任务,直到所有的消费者都执行过任务,在从新回到subscribe开始接收)
模拟的场景是,先分别开启subscribe,subscribe1,subscribe2这三个消费者(代码一样)

然后连续开启6次publish生产者,为了能直观的显示消费者的接收信息,我们在生产者每次下发消息的时候修改body里面的消息(分别是,Hello1,Hello2,Hello3,Hello4,Hello5,Hello6)

最后观察消费者的接收消息如下:subscribe接收的是Hello1和Hello4,subscribe1接收的是Hello2和Hello5,subscribe接收的是Hello3和Hello6
(3)RabbitMQ中的消费者突然宕机的处理机制(默认情况下是,当前消费者正在时突然被宕机,该条消息会被别的消费者继续消费,如果在所有的消费者的回调函数中添加no_ack=True那么当前消费者正在时突然被宕机,该条消息跟着消失。)
在RabbitMQ消息队列中,当生产者发送消息,被消费者接收到,然后消费者处理数据,最终将告诉服务器消息已经处理完成,那么该条消息将会在队列中被移除。但是当消费者接收到消息,正在处理数据(调用的回调函数没有结束)的时候,突然消费者宕机了,那么RabbitMQ是怎么处理的?
消费者:subscribe,subscribe1,其中在回调函数中加一个延迟时间以便于手动关闭消费者(模拟宕机),生产者:publish添加一条消息,之后关闭正在执行的消费者。(先启动subscribe,再启动subscribe1,然后启动publish发送一条信息,接着关闭subscribe)
分别启动subscribe,subscribe1
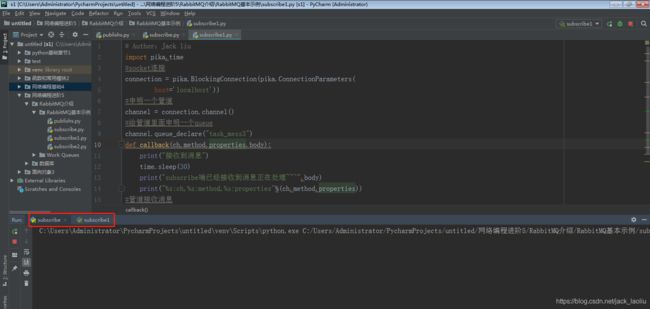
subscribe和subscribe1代码相同
import pika,time
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue
channel.queue_declare("task_mess3")
def callback(ch,method,properties,body):
print("接收到消息")
time.sleep(30)
print("subscribe端已经接收到消息正在处理~~~",body)
print("%s:ch,%s:method,%s:properties"%(ch,method,properties))
#管道接收消息
channel.basic_consume("task_mess3",callback)
channel.start_consuming()
启动publish,然后迅速关闭subscribe(代码中延迟时间为30秒)

关闭subscribe之后打印的信息
查看subscribe1的打印信息,发现当subscribe被强迫停止的时候,该条信息会被另一个消费者去执行。(客户端没有接收确定,那么这条任务还会继续分发)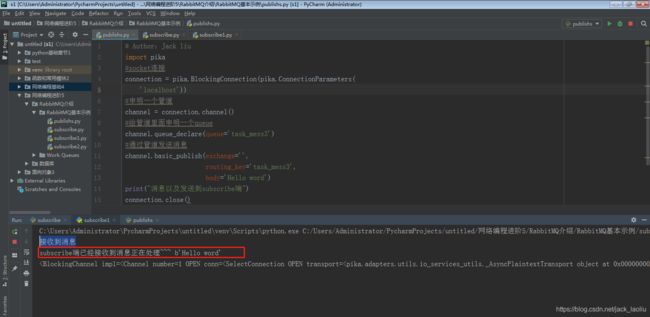
流程总结:生产者发送一个消息,被消费者接收到了并处理完了给生产者发送一个确认(说这个消息已经处理完了),生产者才会在消息队列里给这条消息删除,当生产者没有接收到确认,就不会被删除(突然间消费消息的这个消费者宕机了,被检测到就会将消息转给下一个消费者,当成新消息处理)
(4)RabbitMQ消息持久化
当我们在消息队列里面添加任务的时候,突然rabbitMQ的服务挂了,那么消息队列里面的消息全部都消失了,为了在服务宕机的时候也不影响,那么我们就要学习一下RabbitMQ消息持久化
演示正常情况下RabbitMQ挂掉,消息队列里面的消息全部消失
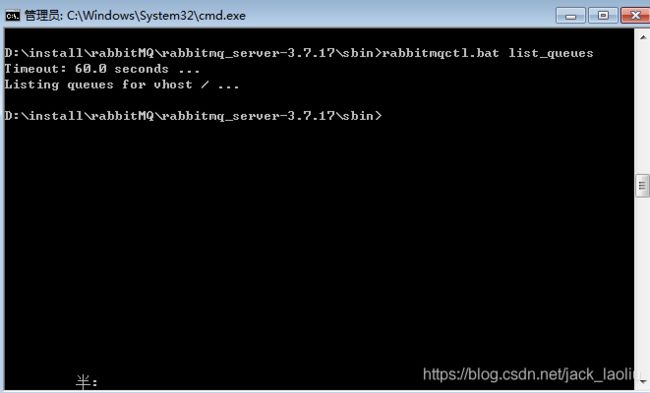
在rabbitMQ安装路径下的sbin中输入:rabbitmqctl.bat list_queues 查询rabbitMQ中的队列以及对应的消息个数

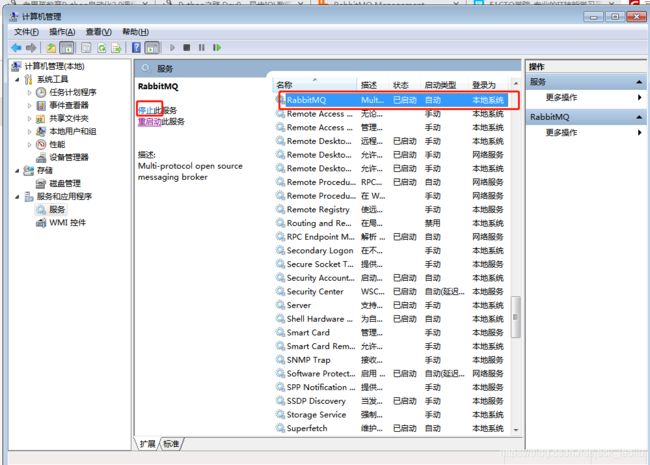
在window中只需要手动关闭RabbitMQ服务,点击“停止”然后再点击“启动”
再次在rabbitMQ安装路径下的sbin中输入:rabbitmqctl.bat list_queues 查询rabbitMQ中的队列以及对应的消息个数,发现添加的消息队列消失了。
处理方法在消费者和生产者申明一个queue的时候,写出序列化channel.queue_declare(queue=‘hello’,durable=True),然后在生产者中的发送消息中补充 properties=pika.BasicProperties(delivery_mode=2)持久化,
生产者:
import pika
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue
channel.queue_declare(queue='hello',durable=True)
#通过管道发送消息
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello word',
properties=pika.BasicProperties(
delivery_mode=2
))
print("消息以及发送到subscribe端")
connection.close()

消费者:
import pika,time
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue,durable=True将队列持续化了
channel.queue_declare("hello",durable=True)
def callback(ch,method,properties,body):
print("接收到消息")
# ch.basic_ack(delivery_tag=method.delivery_tag)
print("subscribe端已经接收到消息正在处理~~~",body)
print("%s:ch,%s:method,%s:properties"%(ch,method,properties))
#管道接收消息
channel.basic_consume("hello",callback)
channel.start_consuming()

在window中只需要手动关闭RabbitMQ服务,点击“停止”然后再点击“启动”。
再次在rabbitMQ安装路径下的sbin中输入:rabbitmqctl.bat list_queues 查询rabbitMQ中的队列以及对应的消息个数,发现添加的消息队列和个数都保存下来没有丢失。

强调:在申明queue的时候channel.queue_declare(queue=‘hello’,durable=True),消费者和生产者都一定要添加durable=True,这个确保队列是持久化的,同时也要在生产者发送消息的时候,添加properties=pika.BasicProperties( delivery_mode=2),这个确保消息是持久化的。如果只是添加了队列持久化,当RabbitMQ挂掉重启的时候,消息队列会保留但是里面小消息丢失了,如果只是添加了消息持久化,当RabbitMQ挂掉重启的时候,这个队列就丢失了,所以既要保证队列的持久化(durable=True),又要保证消息的持久化(properties=pika.BasicProperties( delivery_mode=2))
(5)RabbitMQ消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
模拟:开启两个消费者(receiver1,receiver2),其中receiver1处理上延迟40秒,receiver2正常,然后开启生产者(sender),连续下发4条消息(hello word)。
消费者receiver1
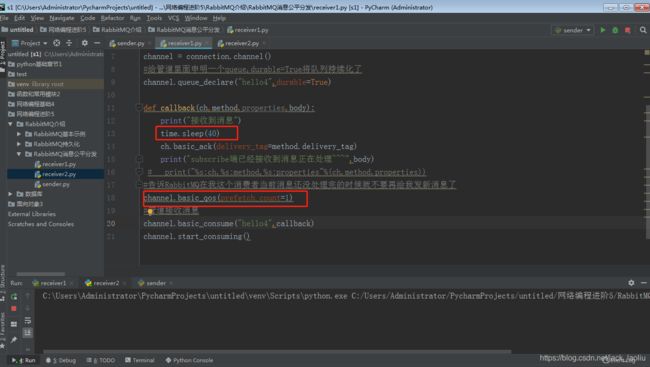
# Author:Jack liu
import pika,time
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue,durable=True将队列持续化了
channel.queue_declare("hello1",durable=True)
def callback(ch,method,properties,body):
print("接收到消息")
time.sleep(40)
ch.basic_ack(delivery_tag=method.delivery_tag)
print("subscribe端已经接收到消息正在处理~~~",body)
print("%s:ch,%s:method,%s:properties"%(ch,method,properties))
#告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
channel.basic_qos(prefetch_count=1)
#管道接收消息
channel.basic_consume("hello1",callback)
channel.start_consuming()
消费者receiver2

# Author:Jack liu
import pika,time
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue,durable=True将队列持续化了
channel.queue_declare("hello1",durable=True)
def callback(ch,method,properties,body):
print("接收到消息")
ch.basic_ack(delivery_tag=method.delivery_tag)
print("subscribe端已经接收到消息正在处理~~~",body)
print("%s:ch,%s:method,%s:properties"%(ch,method,properties))
#告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
channel.basic_qos(prefetch_count=1)
#管道接收消息
channel.basic_consume("hello1",callback)
channel.start_consuming()
生产者:sender

# Author:Jack liu
import pika
#socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
#申明一个管道
channel = connection.channel()
#给管道里面申明一个queue
channel.queue_declare(queue='hello1',durable=True)
#通过管道发送消息
channel.basic_publish(exchange='',
routing_key='hello1',
body='Hello word',
properties=pika.BasicProperties(
delivery_mode=2
)
)
print("消息以及发送到subscribe端")
connection.close()
运行的结果是:消费者receiver1没有打印生产者的消息,消费者receiver2接收了4条hello word 的消息,实现了该功能。