第二天:布尔值、列表、字典和文件操作
1. 布尔值
在python中
None/False/空字符串”“/0/空列表[ ]/空字典{ }/空元组( )都相当于False,其它的都相当于True。
布尔值可以用and、or和not运算。
布尔值经常用在条件判断中,比如:
if age >= 18:
print('adult')
else:
print('teenager')and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and True
True
>>> True and False
False
>>> False and False
False
>>> 5 > 3 and 3 > 1
True or运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or True
True
>>> True or False
True
>>> False or False
False
>>> 5 > 3 or 1 > 3
True not运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not True
False
>>> not False
True
>>> not 1 > 2
True PS:该小节内容引用自廖雪峰的Python3基础教程文档
2. 在线工具分享
在线画思维导图ProcessOn:https://www.processon.com/
贴图库:http://www.tietuku.com/
mahua在线文档编辑器:http://mahua.jser.me/,
mahua用法总结:http://531d2d13.wiz03.com/share/s/1j7iQj2pF4PP2VhPBO1FRNwA0MS8Yz009ARg2G6F7U0XfBq5
“看板”可用来管理工作中的流程:https://trello.com/
3. MVC框架
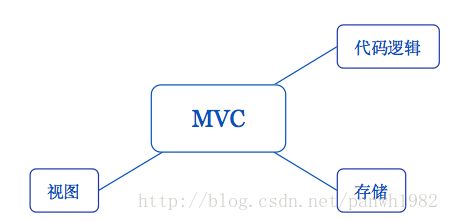
模型-视图-控制器(MVC)是一种软件设计模式,M是指后台代码,V是指用户界面,C则是控制器,使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。比如一批统计数据可以分别用柱状图、饼图来表示。C存在的目的则是确保M和V的同步,一旦M改变,V应该同步更新。
4. 列表(list)和元组
python中的列表类似于其它语言中的数组,是一种从0开始排序,并且是顺序排列的元素集合,可以随时添加和删除其中的元素(元素从前往后的序号是1,2,3,4,从后往前的序号是-1,-2,-3,-4)
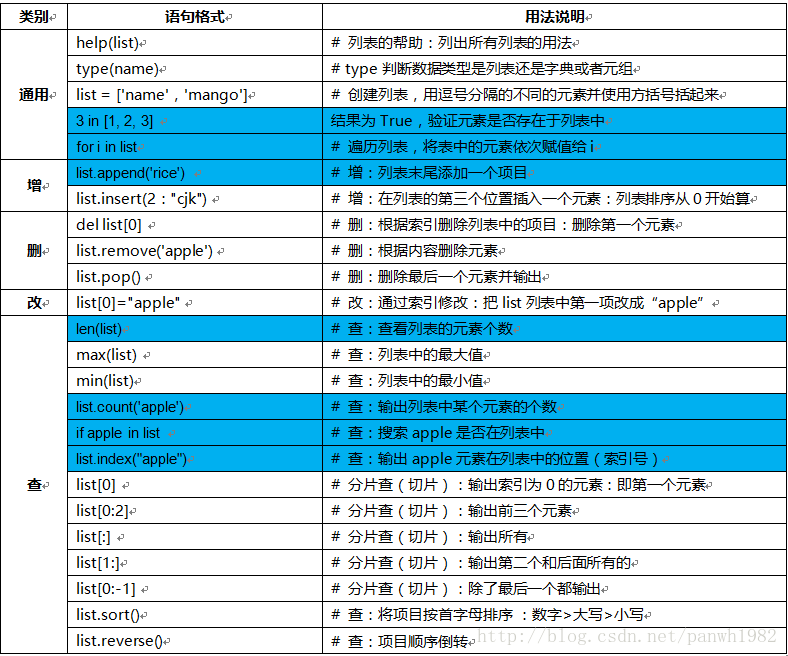
4.1. 列表主要用法
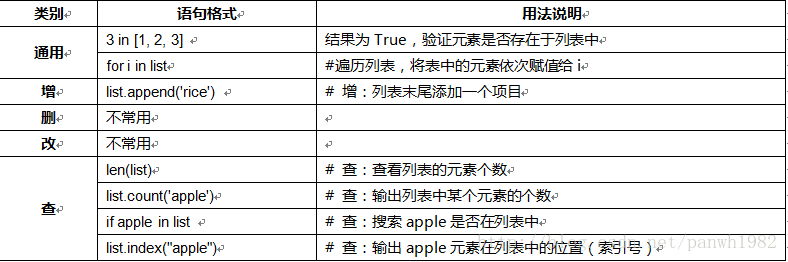
主要用法可分为增、删、改、查四大部分: # 蓝色列表为个人认为的常用语句,重点掌握“查”
4.2. 额外小知识:拼接字典,数据类型判断 # 简单学习即可
将字典中对应key的值拼成列表 # 可在学完字典以后回来看

数据类型判断:tpye和isinstance
type
格式: type(数据或者变量)
In [30]: type('cjk')
Out[30]: str
In [31]: a = ['1','2']
In [32]: type(a)
Out[32]: list
In [33]: type(a) == list #判断数据类型也比较常用,返回布尔值
Out[33]: Trueisinstance
格式: isinstance(变量或数据,数据类型) –>返回布尔值
In [31]: a = ['1','2']
In [34]: isinstance(a,list)
Out[34]: True
In [35]: isinstance('cjk',dict)
Out[35]: False4.3. 小练习:列表去重
a = [1,1,2,3,4,5,6,7] ,要求把列表a的重复项消除
思路1:在原有的列表中找到重复的元素,然后删除这个元素
1) 判断列表中所有元素出现的频率,如果大于2,则获取他们的索引,列表.index(元素)
2) 拿到索引之后,将多余的元素按索引删除即可

思路2:新建列表 ,将不重复的元素挪到新列表中
1) 新建一个列表,作为新的存储
2) 循环老的列表,并将遍历的元素添加到新列表中,同时进行判断,如果该元素已经在新的列表中就pass
3) 最终新列表中就只有不重复的元素了

简单粗暴式:set集合 #去重,set其实是另一种数据类型—集合
![]()
4.4. join()和split()函数
.join()函数用法:“分隔符”.join(列表)—把列表转换成字符串 # 重点,一定要掌握!!!
详细说明见第一天笔记的3.4小节

split()函数用法:字符串.split(‘分隔符’)—把字符串变成列表 # 重点,一定要掌握!!!
语法:‘字符串’.split(‘分隔符’,分割次数)
分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。也可以自己指定分隔符样式。
1.按某一个字符分割,如‘.’
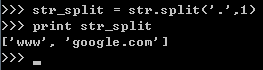
str = ('www.google.com')
print str
str_split = str.split('.')
print str_split结果如下:
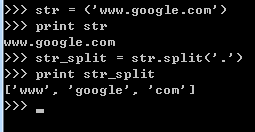
2.按某一个字符分割,且分割n次。如按‘.’分割1次
str = ('www.google.com')
print str
str_split = str.split('.',1)
print str_split结果如下:
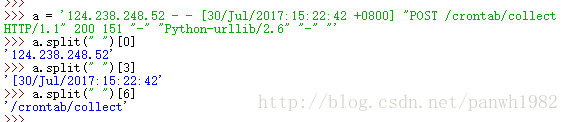
split()函数练习:取出下列数据的IP,请求时间,访问内容
124.238.248.52 - - [30/Jul/2017:15:22:42 +0800] “POST /crontab/collect HTTP/1.1” 200 151 “-” “Python-urllib/2.6” “-” ”
4.5. 遍历列表
方式一:普通遍历

方式二:enumerate函数
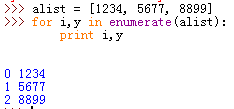
enumerate函数可以同时返回列表中元素的序号和元素值,多用于在for循环中计数,enumerate参数为可遍历的变量,如 字符串,列表等
4.6. 元组 # 不重要,简单了解即可
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy') 现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
5. 字典 — Dictionary(dict)
把目录(键,key)和详细信息(值,value)联系在一起就形成了字典。 键相当于字典的目录,可以通过一个目录来找到与之相对于值。换句话来说,目录就是内容的一个特殊标示,即每一个目录,都会在字典有中有与之相对应的详细信息。也就是说,字典中的每一个目录都是唯一的,与字典中的其他目录互不冲突。(字典中的数据是无序排列)
字典的值可以是任意数据类型,包括字符串,整数,对象,甚至其它的字典。在单个字典里, 字典的值并不需要全都是同一数据类型,可以根据需要混用和匹配。但是键就比较严格了,一般字符串,整数(我知道的只有这两种)。
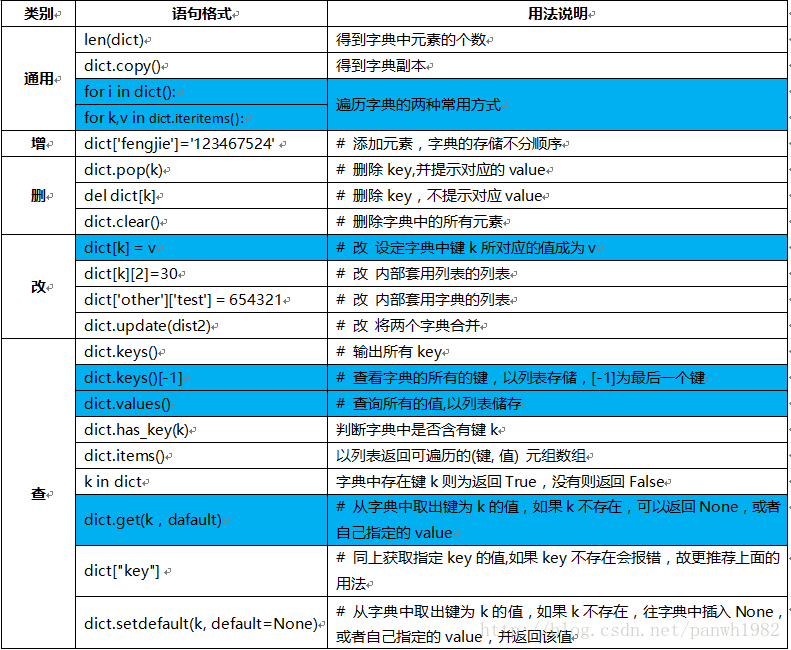
5.1. 字典主要用法:
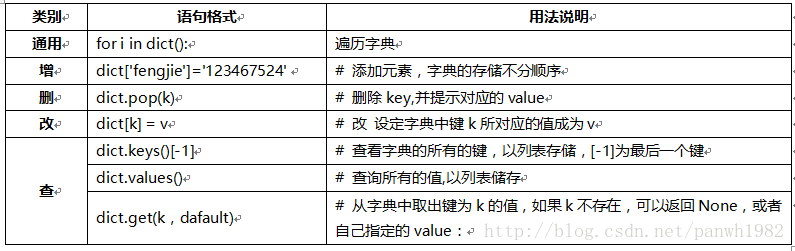
主要用法依旧分为增、删、改、查四大部分: # 蓝色行为个人认为的常用语句,重点掌握“查”
5.2. 遍历字典
首先,我们创建一个字典dict = {‘a’:1,’b’:2,’c’:3,’d’:4},分别用不同的方式遍历,看看会有什么结果
1) 普通遍历for i in dict :

2) 用dict.items()遍历:

如果不好理解,可以将上段代码拆成2段来理解:

3) 用dict.iteritems()遍历:

如果遍历存有较多数据的字典时,建议使用第一和第三种方式,第二种方式速度较慢,因为dict.items()会将字典转化成列表,每循环一次都需要查找整个列表,运行速度要比1,3方式慢。
5.3. 字典的格式化输出
方法一: # 笨方法,如果格式化输出时,有元素不属于字典时用这种

方法二: # 推荐方式,如果所有元素都属于字典,用这种方式

5.4. 练习
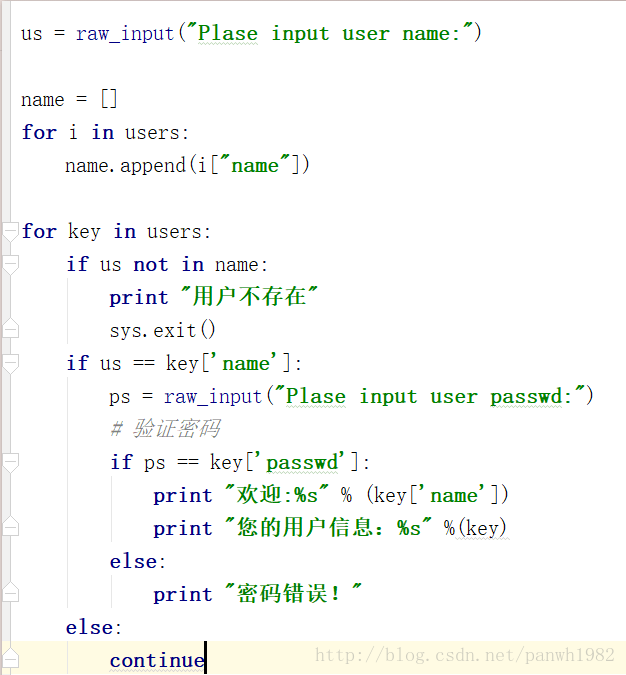
users = [{'age': 18, 'job': 'coo', 'name': 'wd', 'passwd': '12323'},{'age': 19, 'job': 'cto', 'name': 'kk', 'passwd': 'abcdef'},{'age': 20, 'job': 'cio', 'name': 'pc', 'passwd': 'ABC'}]练习要求及思路
已知用户信息的列表users,要求:
1) 判断用户是否在列表中 if else — 需要循环列表,取到对应的name
2) 如果用户不存在,退出;
3) 如果用户存在,则判断密码是否正确 — 取到对应的密码;
4) 如果用户密码都正确 — 打印该用户的信息
代码:
5.5. 列表和字典有什么区别,分别适用于什么场景?
简单说,如果你需要一组有序的数列(0,1,2,3),用列表,如果你需要一组有对应关系的数据,用字典。
在查找大量数据时,用字典比列表快得多。
6. 文件操作
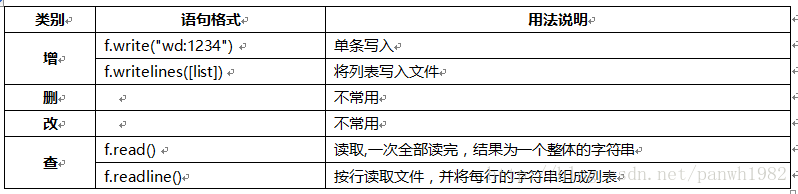
6.1. 主要用法
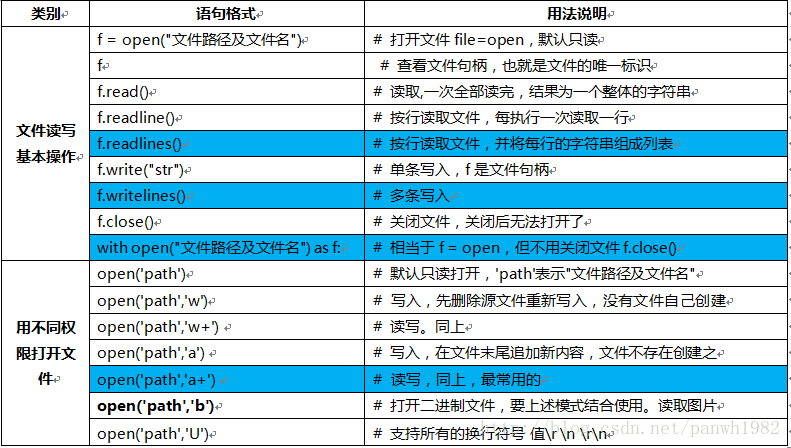
6.2. 文件读写方法展示
A. 单行、多行写入操作
f = open('user.txt','a')
f.write("wd:1234") # 单条写入
names=["kk:123\n","panda:123\n"] # 多条写入的时候,可以利用\n换行
f.writelines(names)
f.close()B. readline()——每次读取一行,结果以字符串形式保存
!/usr/bin/env python
num = 1
fo = open("poem.txt") # 获取文件句柄
while True:
line = fo.readline() # 每次只输出一行
print repr(line) # 打印原始的数据,eg: 'wd:123456\n'
print "%s-->%s" %(num,line.rstrip("\n")) # 每输出一行,前面加个行号,另外line.rstrip("\n")是把字符串中的\n干掉,
num += 1 # 行号每次加1
if len(line)==0: # 读完文件后关闭
break结果:
'wd:123456\n'
1-->wd:123456
'pc:654321\n'
2-->pc:654321
C. readlines() ——一次读取所有,结果以列表形式保存
In [1]: fo = open("user.txt")
In [2]: line= fo.readlines() # 将文件按行读取成列表,每行都是列表的一列
In [3]: type(line)
Out[3]: list
In [4]: line
Out[4]:
['wd:123456\n', # 每行都是列表的一列,且都带有\n换行符号
'pc:654321\n',
'woniu:123\n',
'kk:123\n',
'panda:123\n',
'kk:123\n',
'panda:123\n',
'kk:123\n',
'panda:123\n']D. read()——一次读完所有文件,结果是一个大的字符串
In [10]: fo = open("user.txt")
In [11]: a = fo.read()
In [12]: type(a)
Out[12]: str
In [13]: a
Out[13]: 'wd:123456\npc:654321\nwoniu:123\nkk:123\npanda:123\nkk:123\npanda:123\nkk:123\npanda:123\n'E. 文件倒读
str = ''
with open('/tmp/jobs.log') as f:
for line in reversed(f.readlines()): # 倒读
#print line
str +=line7. 重点汇总—常用语句
列表:
字典:
文件操作
字符串与列表相互转换
join()和split()函数 # 经常用到,一定要掌握!!!
8. 课后作业:
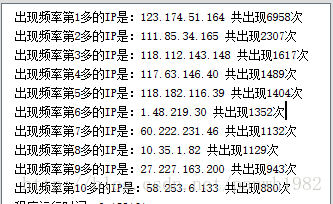
读取access.txt日志文件,找出重复次数前10的IP地址,输出IP地址和重复次数
文件下载地址:http://pan.baidu.com/s/1bps7bpt
答案: