python爬取带stonefont字体网页的经历
一、问题描述
在爬取某电影网站票价信息时,使用selenium定位票价元素信息时,发现票价显示“□□”,如下图所示:
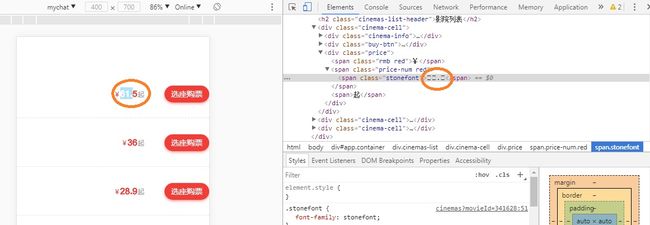
而通过chrome浏览器“查看网页源代码”方式查看该元素数值时,显示的是非正常票价数值,如下图所示:

二、 问题解决思路
百度查询相关解决方案,发现该网页使用了web-font字体,网页在打开时调用美团字体库对页面中数值进行渲染,需要找出当前网页使用的字体库,因为每次打开网页调用的字体库不一样, 所以需要每次都与基本库字形进行对比,找出实际对应的数字。在该网页源代码中字体库地址如下图所示:
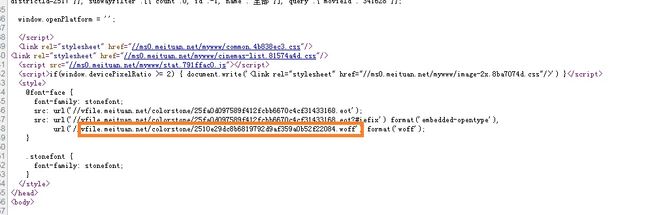
三、解决流程
1、环境
from selenium import webdriver from selenium.webdriver.chrome.options import Options from fontTools import ttLib
FontCreator软件,用于查看下载的字体库文件,可以比较直观的查看字形定义和字形代码。
2、解决流程
1)下载字体文件
下载网页字体库文件woff,保存到电脑中(文件后缀为woff),用于建立用于后期对比的基本字形库(字形名和字形定义),只下载一次即可。需要使用正则表达式搜索网页源代码中字体下载地址。这部分功能用的requests库,其它用的selenium,其实也可以全部用selenium,requests和selenium在解决该类问题时的区别在后面再说一下。
tem_re = re.compile(r"vfile.*?woff") font_url = r'http://' + tem_re.findall(driver.page_source)[0] #获取当前页面字体库下载地址 print('当前页面字体文件地址:', font_url) resp = requests.get(font_url) with open(r'd:\current.woff', 'wb') as fontfile: #将当前页面字体库下载至current.woff fontfile.write(resp.content)
2)字体文件格式说明
(1)用FontCreator打开下载的字体文件,如下图:
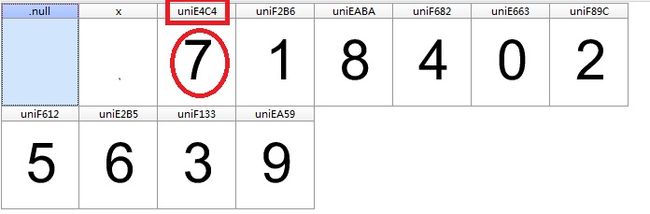
字形文件共12个元素,主要看10个数字对应的编号关系,建立每个数字和编号的对应关系。自定义的基本字体库:
base_woff_list=['uniE4C4','uniF2B6','uniEABA','uniF682','uniE663','uniF89C','uniF612','uniE2B5','uniF133','uniEA59'] base_num_list=['7','1','8','4','0','2','5','6','3','9']
(2) 字体库的字形定义
可以将下载的woff文件解析为xml文件,命令:
current_woff=ttLib.TTFont(r"*.woff")
base_font_woff.saveXML() # base_font_woff是字体文件对象,将字体文件解析出XML文件
用浏览器查看字形定义,方框中就是某个数字的字形定义,也是之后用于与其他网页票价信息中某个数字字形相比较,从而确定到底对应的是0-9哪个数字。“uniE18F”是这个数字对应的ID
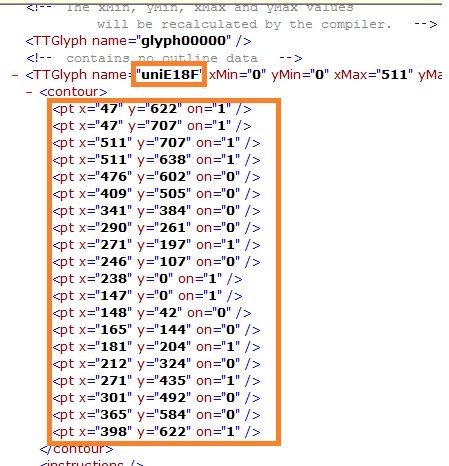
(3)字形比较
current_woff['glyf']['字符ID']==base_woff['glyf']['字符ID']
current_woff['glyf']['字符ID'] #该字符ID的字形定义对象, 也就是上图中大方框中的内容,像素瞄点
字形比较是程序中的核心部分,也就是字符解码。
四、其他问题
1)网页源代码问题
chrome浏览器用"检查元素"和“查看网页源代码”两种方式获得的网页内容不一样,前者对使用字体库的票价数字只显示“□□”,而查看网页源代码可以获得该数字的unicode编码。那么问题来了,如何通过selenium的xpath方式得到该数字的unicode编码,如何你使用如下语句,用print方式无法显示正常字符:
price_list=driver.find_elements_by_xpath("//span[@class='price-num red']") #获取当前页面票价list
print(price_list[0].text[0])#输出票价的第一位数字,实际什么也不显示
这里面需要使用str到unicode(class is byte)的转码,在把转码结果强制转换为str,最后把str截取后四位字符ID,再与“uni”字符串结合确定该数字对应的字符ID。核心对比代码如下:
current_woff['glyf']['uni'+str(temp_font_tag.encode('unicode_escape'))[5:9].upper()]!=base_woff['glyf'][base_woff_list[z]]
2)其他
为了得到票价数字的unicode破费一番周折,应为webdriver对象的page_source也无法正常显示。BeautifulSoup对象也无法正常显示。只有requests对象可以直接显示票价数字的unicode码。好累啊,哈哈。
总结:python业余爱好者,非科班出身,也不从事编程工作,纯粹爱好,遇到这类stonefont字体问题也百度了几篇参考文献,自己梳理的自认为核心问题在这里总结,写的不全面勿喷,全部代码就不贴了。
参考文档:
https://blog.csdn.net/FengHuaJianShi/article/details/78404216
https://blog.csdn.net/qq_31032181/article/details/79153578