Seaborn
简单的学一下
Seaborn是在matplotlib的基础上进行了更高级的API封装
import seaborn as sns
import numpy as np
import matplotlib as mpt
import matplotlib.pyplot as plt
%matplotlib inline
def sinplot(flip=1):
x=np.linspace(0,14,100)#在区间0到14上找100个点
for i in range(1,7):#画六条线
plt.plot(x,np.sin(x+i*.5)*(7-i)*flip)
plt.show()
sinplot()

使用seaborn默认风格 ,使用seaborn默认参数
sns.set()
sinplot()

seaborn中有5种主题风格:
- darkgrid
- whitegrid
- dark
- white
- ticks
plt.rcParams['figure.figsize'] = (8,6)
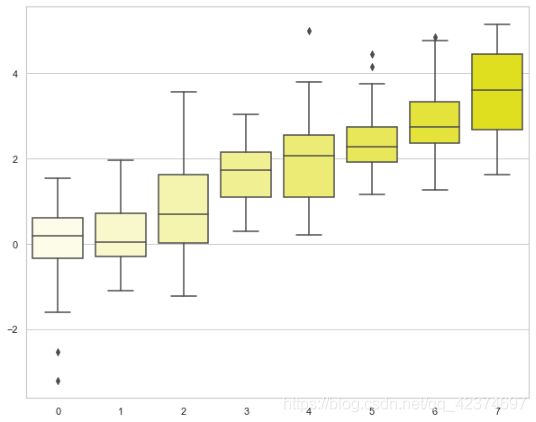
sns.set_style("whitegrid") # 使用whitegrid主题
data = np.random.normal(size=(20,6)) + np.arange(6)/2
sns.boxplot(data=data)
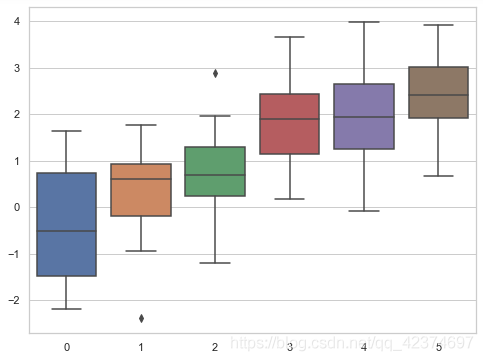
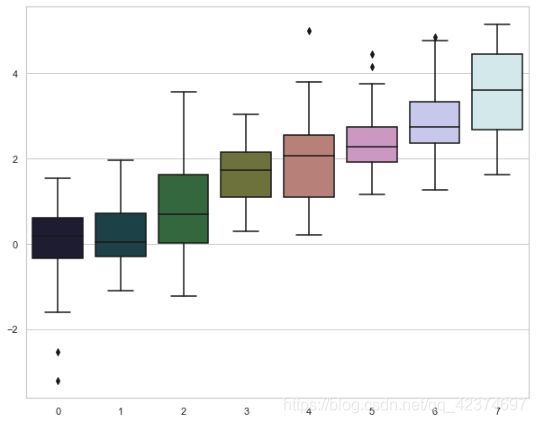
sns.set_style("dark") # dark
sns.boxplot(data=data)

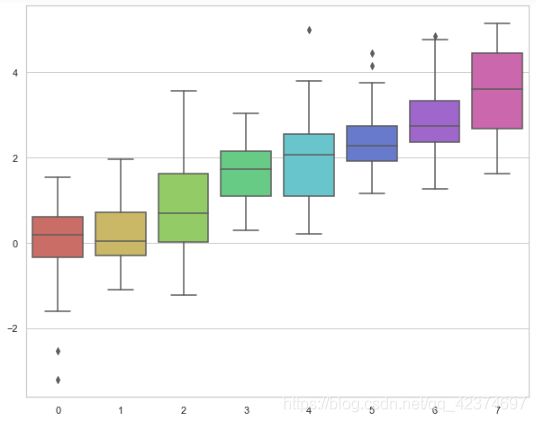
sns.set_style("ticks") # ticks 刻度线
sns.boxplot(data=data)
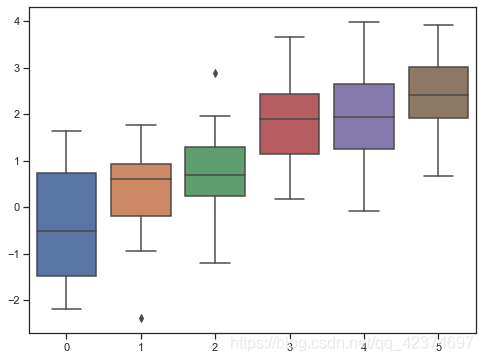
图形与轴线距离
sns.violinplot(data)
sns.despine(offset=30)

sns.set_style("whitegrid") # 使用whitegrid主题
data = np.random.normal(size=(20,6)) + np.arange(6)/2
data
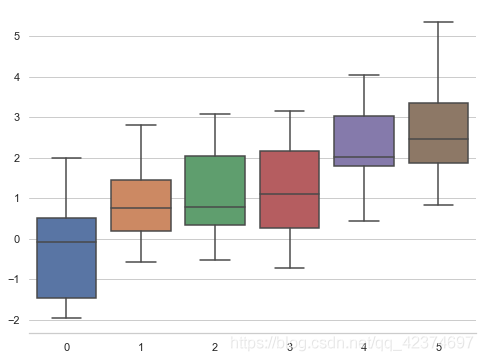
sns.boxplot(data=data) #箱型图
sns.despine(left=True) # 隐藏左边的轴
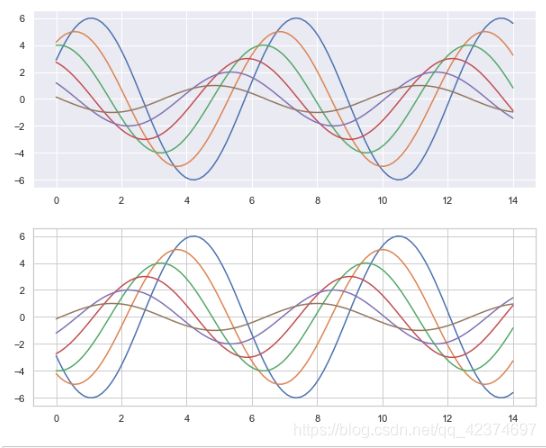
plt.rcParams['figure.figsize'] = (10,8) # 单位是inches
with sns.axes_style("darkgrid"): # 在with中的使用seaborn画图,只在with中生效
plt.subplot(211)
sinplot()
plt.subplot(212)
sinplot(-1)
def sinplot(flip=1):
x=np.linspace(0,14,100)#在区间0到14上找100个点
for i in range(1,7):#画六条线
plt.plot(x,np.sin(x+i*.5)*(7-i)*flip)
plt.show()
sns.set()
sns.set_context("paper")#参数paper,poster,notebook,talk
plt.figure(figsize=(8,6))
sinplot()

sns.set_context("talk")#参数paper,poster,notebook,talk
plt.figure(figsize=(8,6))
sinplot()
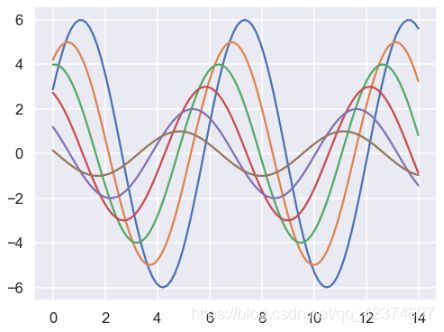
sns.set_context("poster")#参数paper,poster,notebook,talk
plt.figure(figsize=(8,6))
sinplot()

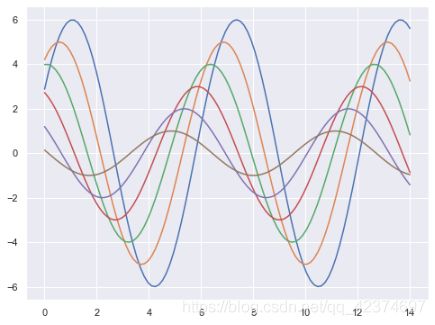
sns.set_context("notebook")#参数paper,poster,notebook,talk
plt.figure(figsize=(8,6))
sinplot()
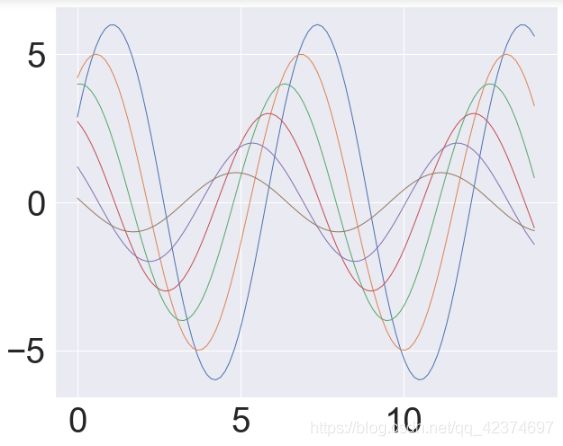
# 指定字体大小,线条粗细
sns.set_context("notebook",font_scale=3.5,rc={"lines.linewidth": 1})
sinplot()
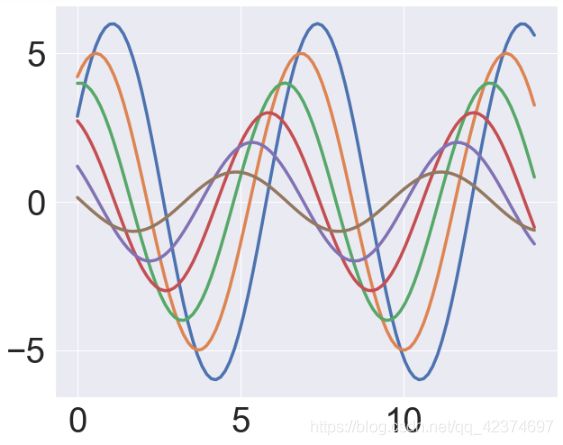
sns.set_context("notebook",font_scale=3.5,rc={"lines.linewidth": 3.5})
sinplot()
调色板
- 颜色很重要
- color_palette()能传入任何Matplotlib所支持的颜色
- color_palette()不写参数则默认颜色
- set_palette()设置所有图的颜色
离散型和连续型的颜色
分类色板:
# 调色板
current_palette=sns.color_palette()
sns.palplot(current_palette)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4eo9J9bs-1597118884190)(output_21_0.png)]](http://img.e-com-net.com/image/info8/a73ed02220b64ff09ada966c2b046a44.png)
6个默认的颜色循环主题:deep,muted,pastel,bright,dark,colorblind
圆形画板
当你有六个以上的分类要区分时,最简单的方法就是在一个圆形的颜色空间中画出均匀间隔的颜色(这样的色调会保持亮度和饱和度不变),这是大多数的当他们需要使用当前默认颜色循环中设置的颜色更多时的默认方案。
最常用的方法是使用hls的颜色空间,这是RGB的一个简单转换。
color_palette=sns.color_palette("hls",8)
sns.palplot(color_palette)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AEvtj0s5-1597118884193)(output_23_0.png)]](http://img.e-com-net.com/image/info8/c2b89df402774ee0a37f2656e76cfb2d.png)
color_palette=sns.color_palette("hls",12)
sns.palplot(color_palette)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V2u8qdHc-1597118884197)(output_24_0.png)]](http://img.e-com-net.com/image/info8/5b0dd9f93da5423ca5ccec74b848f00e.png)
# 箱型图
data=np.random.normal(size=(20,8))+np.arange(8)/2
plt.rcParams['figure.figsize'] = (10,8)
sns.set_style("whitegrid") # 使用whitegrid主题
color_palette=sns.color_palette("hls",8)
sns.boxplot(data=data,palette=color_palette)
plt.show()
hls_palette()函数来控制颜色的亮度和饱和
- l-亮度 lightness
- s-饱和 saturation
sns.palplot(sns.hls_palette(8,l=.5,s=.9))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MFT8br8M-1597118884204)(output_27_0.png)]](http://img.e-com-net.com/image/info8/cab9527dfb18423b899c183cbfa9b6e0.png)
sns.boxplot(data=data,palette=sns.hls_palette(8,l=.5,s=.9))
plt.show()

sns.palplot(sns.color_palette("Paired",8)) # 进行对比 ,两两对比 》》浅蓝色:深蓝 浅绿色:深绿 ...
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sWYLQGVx-1597118884208)(output_29_0.png)]](http://img.e-com-net.com/image/info8/352d10d966da496b831e6f14b9e28324.png)
sns.boxplot(data=data,palette=sns.color_palette("Paired",8))
plt.show()

连续色板
色彩随数据变换,比如数据越来越重要,则颜色越来越深。
sns.palplot(sns.color_palette("Blues"))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tr7iA9Yt-1597118884214)(output_32_0.png)]](http://img.e-com-net.com/image/info8/4c9bd300804541528de5302a9115f80f.png)
如果想要翻转渐变,可以在面板名称中添加一个_r
sns.palplot(sns.color_palette("Blues_r"))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qCLUvz0r-1597118884218)(output_34_0.png)]](http://img.e-com-net.com/image/info8/0310b0a882824475b850b3d2b876c443.png)
cubehelix_palette()调色板
色调线性变换
sns.palplot(sns.color_palette("cubehelix",8))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wxzolwA6-1597118884220)(output_36_0.png)]](http://img.e-com-net.com/image/info8/7f98a3cf463f466ba03679cf03cbc8b1.png)
sns.boxplot(data=data,palette=sns.color_palette("cubehelix",8))
plt.show()
sns.palplot(sns.color_palette("cubehelix",12))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pwh4P9FB-1597118884226)(output_38_0.png)]](http://img.e-com-net.com/image/info8/f6336c50711b4350a779452b9287dfda.png)
sns.palplot(sns.cubehelix_palette(8,start=.5,rot=-.75))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G8ZkEvhB-1597118884229)(output_39_0.png)]](http://img.e-com-net.com/image/info8/644cdc0974f74351b746cc37efba0178.png)
light_palette()和dark_palette()调用定制连续调色板
sns.palplot(sns.light_palette("red"))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q595BgZC-1597118884232)(output_41_0.png)]](http://img.e-com-net.com/image/info8/193f5d4a732d435bb2bff3eb6c83e119.png)
sns.palplot(sns.light_palette("yellow",8))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XaIjU7JP-1597118884235)(output_42_0.png)]](http://img.e-com-net.com/image/info8/72d2ca5356444d48b7b66c92d2a8d375.png)
sns.boxplot(data=data,palette=sns.light_palette("yellow",8))
plt.show()
sns.palplot(sns.dark_palette("blue"))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b4ScPuLN-1597118884240)(output_44_0.png)]](http://img.e-com-net.com/image/info8/8bb9d57148034417a2e9685864b09590.png)
反转,由深到浅
sns.palplot(sns.dark_palette("blue",reverse=True))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FYwrA1IS-1597118884244)(output_46_0.png)]](http://img.e-com-net.com/image/info8/312007c2fbca4fbaa7e5b26087fe27f7.png)
x,y=np.random.multivariate_normal([0,0],[[1,-.5],[-.5,1]],size=300).T
with sns.axes_style("darkgrid"): # 在with中的使用seaborn画图
pal=sns.dark_palette("green",as_cmap=True)
sns.kdeplot(x,y,camp=pal)

直方图
- 单变量分布
变量分布可用于表达一组数值的分布趋势,包括集中程度、离散程度等。seaborn中提供了3种表达单变量分布的绘图接口
distplot
distribution+plot,接口内置了直方图(histogram)、核密度估计图(kde,kernel density estimation)以及rug图(直译为地毯,绘图方式就是将数值出现的位置原原本本的以小柱状的方式添加在图表底部),3种图表均可通过相应参数设置开关状态,默认情况下是绘制hist+kde。
distplot支持3种格式数据:pandas.series、numpy中的1darray以及普通的list类型。以鸢尾花数据为例,并添加rug图可得如下图表:
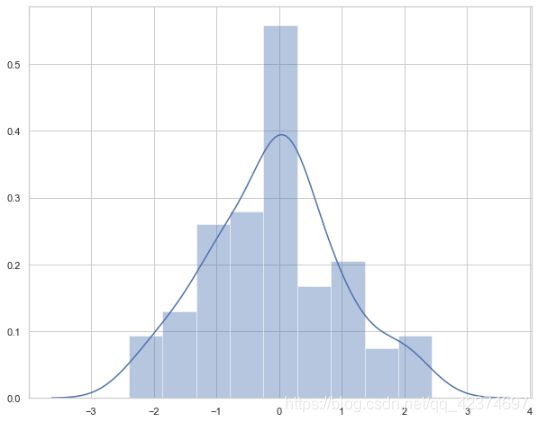
x =np.random.normal (size=100)
sns.distplot(x, kde=True) # 需要做核密度估计
x =np.random.normal (size=100)
sns.distplot(x,bins=10, kde=True) # 需要做核密度估计
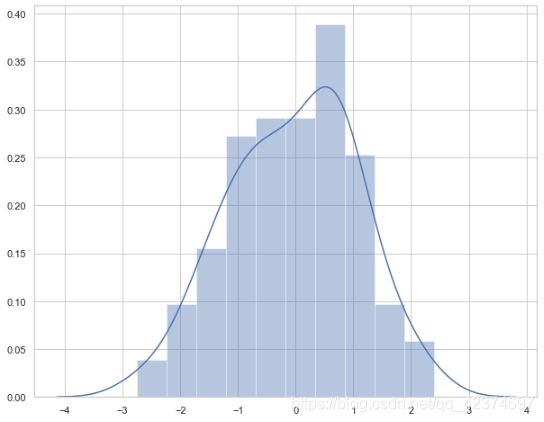
sns.distplot(x, kde=False, rug=True)

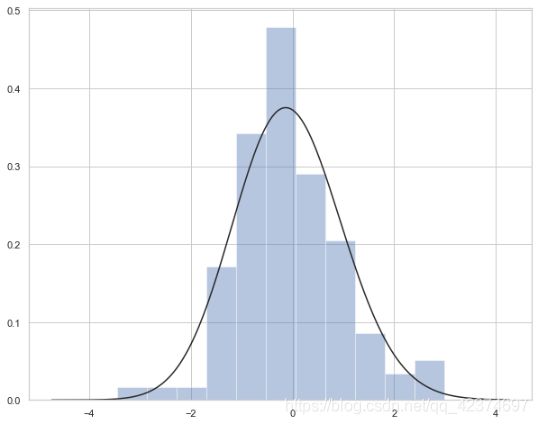
x =np.random.normal (size=100)
from scipy import stats,integrate
sns.distplot(x, kde=False,fit=stats.gamma)
根据均值和协方差生成数据
import pandas as pd
import numpy as np
mean,cov = [0,1], [(1,.5),(.5,1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x","y"])
df
| x | y | |
|---|---|---|
| 0 | -0.740086 | 0.657901 |
| 1 | 0.008141 | 0.790282 |
| 2 | 0.922745 | 1.466627 |
| 3 | -1.067108 | -0.093577 |
| 4 | -0.293711 | 0.883318 |
| ... | ... | ... |
| 195 | 1.538877 | 0.065780 |
| 196 | 0.035276 | 0.306113 |
| 197 | -0.618367 | 0.213944 |
| 198 | -0.006016 | 0.506377 |
| 199 | -0.289681 | 2.118134 |
200 rows × 2 columns
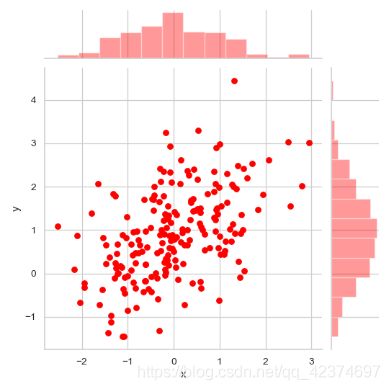
二维数据,看一下X特征与Y特征之间的关系
# 绘制散点图
# 观察两个变量之间的分布情况:(散点图)
sns.jointplot(x='x',y='y',data=df,color='red')
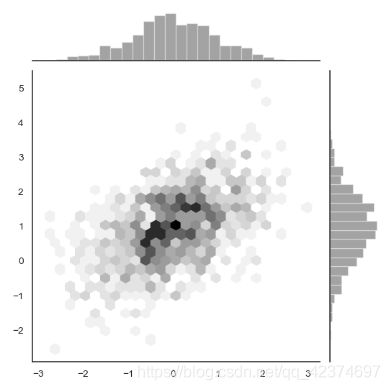
x,y=np.random.multivariate_normal(mean,cov,1000).T
with sns.axes_style('white'):
sns.jointplot(x=x,y=y,kind='hex',color='k')
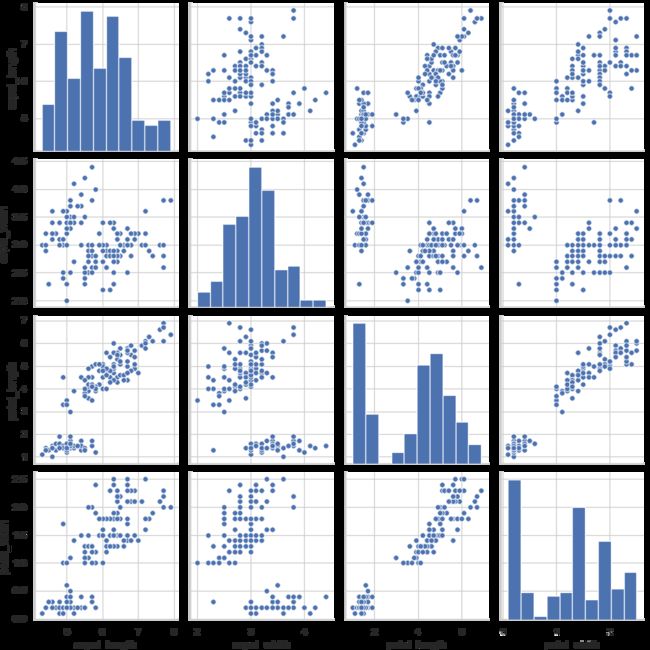
4、多变量分析绘图
iris = sns.load_dataset("iris") #传入数据
sns.pairplot(iris)
regplot()和lmplot()都可以绘制回归关系,推荐regplot()
tips = sns.load_dataset('tips')
sns.regplot(x="total_bill", y="tip", data=tips)

如果值为整数,不适合建立回归模型,如:
sns.regplot(x="size",y="tip",data=tips)
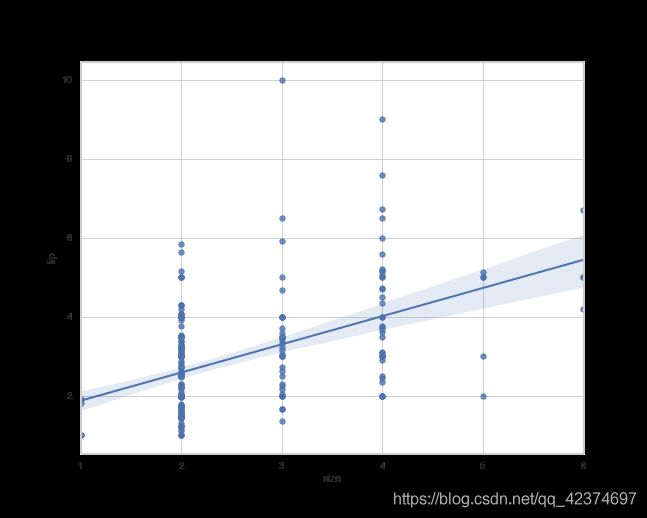
离群点
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid", color_codes=True)
np.random.seed(sum(map(ord, "categorical")))
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")
sns.stripplot(x="day", y="total_bill", data=tips);

sns.stripplot(x="day", y="total_bill", data=tips, jitter=True) #jitter=True

sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True);

sns.violinplot(x="day", y="total_bill", data=tips, sinner=None);
sns.swarmplot(x="day", y="total_bill", data=tips,color='w',alpha=.5)

多层面板分类图
这个将之前的几种整合到一起,将图的类型作为参数传入
关于factorplot
seaborn.factorplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='point', size=4, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)
Parameters:
•x,y,hue 数据集变量 变量名
•date 数据集 数据集名
•row,col 更多分类变量进行平铺显示 变量名
•col_wrap 每行的最高平铺数 整数
•estimator 在每个分类中进行矢量到标量的映射 矢量
•ci 置信区间 浮点数或None
•n_boot 计算置信区间时使用的引导迭代次数 整数
•units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
•order, hue_order 对应排序列表 字符串列表
•row_order, col_order 对应排序列表 字符串列表
•kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点 size 每个面的高度(英寸) 标量 aspect 纵横比 标量 orient 方向 "v"/"h" color 颜色 matplotlib颜色 palette 调色板 seaborn颜色色板或字典 legend hue的信息面板 True/False legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False share{x,y} 共享轴线 True/False
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
import matplotlib as mpl
import matplotlib.pyplot as plt
sns.set(style="ticks")
np.random.seed(sum(map(ord, "axis_grids")))
tips = sns.load_dataset("tips")
tips.head()
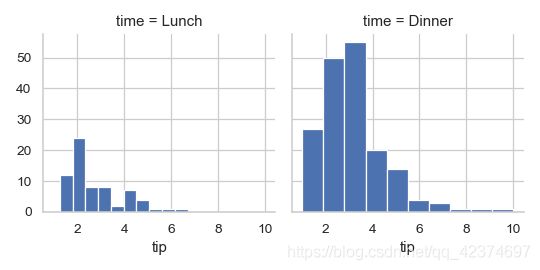
g = sns.FacetGrid(tips, col="time")
g.map(plt.hist, "tip") #条形图,tip为x轴
g = sns.FacetGrid(tips, col="sex", hue="smoker") #
g.map(plt.scatter, "total_bill", "tip", alpha=.7) #alpha为透明度
g.add_legend() #加入图例(最右边的)

g = sns.FacetGrid(tips, row="smoker", col="time", margin_titles=True)
g.map(sns.regplot, "size", "total_bill", color=".1", fit_reg=True, x_jitter=.1) #fit_reg 表示回归的直线要不要画出来, x_jitter表示抖动区间
