唐诗分析之爬取数据
唐诗分析
唐诗分析可视化
项目简介
唐诗分析项目是一个对中国古代唐诗的内容进行数据统计并将其以图表等形式可视化出来的一个JavaWeb项目。
项目的成果可以让用户直观的看到唐朝的各个诗人的作诗量。除此之外,项目将诗人们使用最频繁的词语可视化为一个词云供用户观看。
项目思路
项目主要分两个大步骤:
- 从网络上爬取古诗词保存入数据库
- 提取数据库中的信息进行处理展示
在该博客中描述了第一个步骤将数据保存入数据库。
我们获取的数据来源:

爬取诗词到数据库思路:
我们的最终目的就是获取诗词的数据并存入到数据库中。
那么这个步骤可以细分为一下七个步骤:
- 获取首页网站的html文件(其中包含了每首诗的href,即访问地址)
- 从获取到的html文件中拿到每首诗的链接
- 进入到每首诗的详情页获取诗的信息(作者,朝代,内容等)
- 将诗的信息进行处理(计算SHA-256-防止重复存入,分词-将来做词云用)
- 存入数据库
技术选型
分析上述几个步骤,我们需要用到很多第三方库,有了技术的支持才能完成对应的功能。
-
HtmlUnit(数据爬取)
通过HtmlUnit库,可以很方便的加载一个完整的Html页面而且可以很轻易的模拟各种浏览器,然后就可以将其转换成我们常用的字串格式。用其他工具来获取其中的元素了。当然也可以直接在HtmlUnit提供的对象中获取网页元素(比如诗词的文本内容或详情页的链接)。
此处我用的是HtmlUnit库提供的对象进行的数据获取。 -
ansj_seg
通过ansj_seg,可以对获取到的诗内容进行分词,用于将来的展示。 -
MySQL数据库(数据存储)
这是一个轻量级的数据库,操作方便,且支持SQL语句。利用客户端我们可以方便的对数据进行存储与管理里。 -
maven(项目管理工具)
在项目开发的过程中,我们会用到很多依赖包,所以此时maven管理是必不可少的,它可以极大提高开发效率。
熟悉工具
HtmlUnit的使用:
通过编写Demo的方式先熟悉工具的简单使用。
import java.util.List;
public class HtmlUnitDemo {
@Test
public void test1() throws IOException {
//无界面的浏览器(HTTP 客户端)
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//关闭了浏览器的js执行引擎和css执行引擎
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//请求页面
HtmlPage page = webClient.getPage("https://so.gushiwen.org/gushi/tangshi.aspx");
System.out.println(page);
//保存到指定路径
File file = new File("唐诗三百首\\列表页.html");
page.save(file);
//获取html的body标签的内容
HtmlElement body = page.getBody();
//获取body中的有用的标签
List<HtmlElement> elements = body.getElementsByAttribute(
"div",
"class",
"typecont");
/* for (HtmlElement e:elements){
System.out.println(e);
}*/
//取出第一个五言绝句
HtmlElement divElement = elements.get(0);
List<HtmlElement> aElements = divElement.getElementsByAttribute(
"a",
"target",
"_blank");
System.out.println(aElements.size());
for (HtmlElement e:aElements) {
System.out.println(e);
}
System.out.println(aElements.get(0).getAttribute("href"));
}
@Test //详情页的爬取测试
public void test2HtmlUnitDetailPages() throws IOException {
//无界面的浏览器(HTTP 客户端)
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//关闭了浏览器的js执行引擎和css执行引擎
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//请求页面
HtmlPage page = webClient.getPage("https://so.gushiwen.org/shiwenv_45c396367f59.aspx");
//获取html的body标签的内容
HtmlElement body = page.getBody();
//爬取标签路径
String xPath;
{
//获得标题、朝代作者等信息,根据xPath
xPath = "//div[@class='cont']/h1/text()";
Object o = body.getByXPath(xPath).get(0);
DomText domText = (DomText)o;
//标题
String title = domText.asText();
System.out.println("标题:"+title);
}
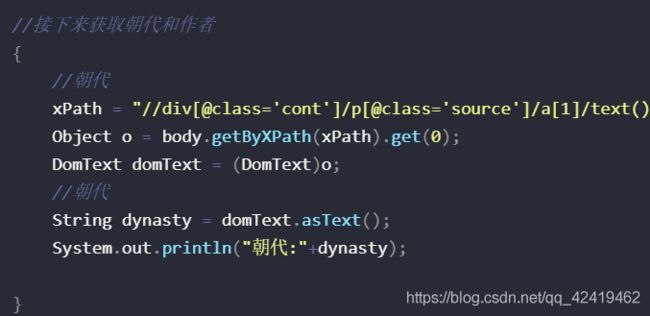
//接下来获取朝代和作者
{
//朝代
xPath = "//div[@class='cont']/p[@class='source']/a[1]/text()";
Object o = body.getByXPath(xPath).get(0);
DomText domText = (DomText)o;
//朝代
String dynasty = domText.asText();
System.out.println("朝代:"+dynasty);
}
{
//作者
xPath = "//div[@class='cont']/p[@class='source']/a[2]/text()";
Object o = body.getByXPath(xPath).get(0);
DomText domText = (DomText)o;
//作者
String user = domText.asText();
System.out.println("作者:"+user);
}
{
//古诗词内容
xPath = "//div[@class='cont']/div[@class='contson']";
Object o = body.getByXPath(xPath).get(0);
HtmlElement htmlElement = (HtmlElement)o;
//正文
String content = htmlElement.getTextContent();
System.out.println("正文:"+content);
}
}
}
关键方法的解释:
- getElementsByAttribute
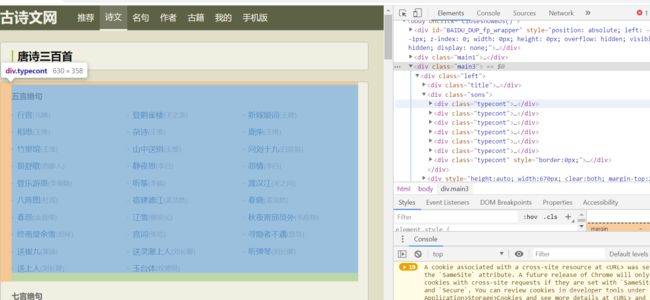
body.getElementsByAttribute(“div”,“class”,“typecont”);
获取div标签中class属性为typecont的html元素。由html的语法可以知道Dom树中可能不只这一个该元素,所以返回值为一个集合类型。从右图中也可以看出第一个该元素对应着五言绝句的分类,那么第二个就是七言绝句,第三个,第四个。。。。
我们都可以获取到。
- getAttribute
aElements.get(0).getAttribute(“href”)
我们可以利用上述方法同样获得a标签元素,然后利用该方法获得属性href的值,这个值就是我们需要的详情页的相对访问链接。

- XPath路径
String xPath;
{
//获得标题、朝代作者等信息,根据xPath
xPath = “//div[@class='cont']/h1/text()”;
Object o = body.getByXPath(xPath).get(0);
DomText domText = (DomText)o;
//标题
String title = domText.asText();
System.out.println(“标题:”+title);
}
//div[@class=‘cont’]/h1/text():
表示获取div中属性class为cont的元素
其下面的h1标签的内容。
这是通过XPath路径获取信息,更为方便。
DomText为节点对象,asText()为获取内容的文本形式。
注意:
需要注意的是:
a[1]表示该路径下不止一个a标签,且下标的值是从1开始的。
- ansj_seg(分词库)
package lab;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import org.junit.Test;
import java.util.List;
/**
* 分词Demo测试
*/
public class AnsiDemo {
@Test
public void splitTest(){
String sentence = "愿你熬得过万丈孤独,藏得下星辰大海";
List<Term> termList = NlpAnalysis.parse(sentence).getTerms();
for (Term term : termList) {
//getNatureStr输出词性,getRealName输出词语
System.out.println(term.getNatureStr() + ":" + term.getRealName());
}
}
}
NlpAnalysis.parse(sentence).getTerms();
调用静态方法将要解析的字符串传入并调用getTerms方法返回一个Term的集合。
利用该方法可以对获取的诗的内容进行词语提取。
小结:
经过工具的练习,我们大致可以爬取到自己想要的内容了。
接下来就是数据库中存入数据了。
我们需要对数据库表进行设计!
数据库表的设计
我们要存的是一首首的唐诗。那么至少该包含下列属性:
古诗名、作者、朝代、正文
除了这四个属性,我们将来会用到分词,所以应该加一个存词语的属性。
为了保证插入的不重复我们设置一个SHA-256属性。最后再加上主键自增长的id。一共七个属性。
建表语句:
SHA-256是固定长度所以用char,诗内容与分词信息比较大,所以使用TEXT
CREATE DATABASE tangshi;
USE tangshi;
-- 最终表
CREATE TABLE tangshi(
id INT AUTO_INCREMENT PRIMARY KEY,
sha256 CHAR(64) NOT NULL UNIQUE,
dynasty VARCHAR(20) NOT NULL,
title VARCHAR(30) NOT NULL,
author VARCHAR(20) NOT NULL,
content TEXT NOT NULL,
words TEXT NOT NULL
);
代码实现
单线程版:
全部由主线程完成,数据库存入操作速度最慢。无线程安全问题。
多线程版:
爬取首页网站还是主线程做,之后每一个详情页(每一首的单独页面)启动一个线程进行解析并存入数据库。
编写中遇到的问题:
Connection存在线程安全。解决:每个线程从dataSource中获取一个连接对象。
线程池版:
用到是Executors.newFixedThreadPool(int)方式创建的线程池。
编写中遇到的问题:
程序不能自己停止,就算诗全部存入数据库中也不能停止。
原因:
因为JVM在等待所有非后台线程停止,而线程池却是不会停止的,每个线程任务完成后,资源归还给线程池,线程池不停止,那么JVM就不会停止。
解决:
有两种方式:
- 利用原子类计数,完成一个线程就减掉一
- 利用CountDownLatch类
这里使用的是第二种方式:
CountDownLatch的构造方法可以传入需要等待结束的线程数。
//指定countDownLatch要等待的任务数,有多少个详情页就要启动多少个任务
countDownLatch = new CountDownLatch(hrefs.size());
我们只需要在每个线程结束时调用一下
//表示该任务结束
countDownLatch.countDown();
最后在主线程中调用:
所有线程结束后该方法就会被执行通过。
之后我们让线程池关闭即可。
//利用CountDownLatch等待诗词处理完毕,如果没结束,那么就停在这
countDownLatch.await();
executor.shutdown();
爬取数据源码:
唐诗分析