程序人生 | (9) 从深度学习到深度理解
原文链接
作者 | 蒋宝尚
在《从深度学习到深度理解》的演讲报告中,沈向洋对过去十年,人工智能发生的变化做了总结。他提到,当前我们在大数据利用,计算架构方面的创新有着很大的进步,但是通用人工智能的进展一直缓慢。
他还表示,我们必须认真思考智能的真正含义是什么,深度学习只是狭义的人工智能,必须构建 robust AI 才能实现真正的强人工智能。
谈到深度学习,DNN是绕不开的话题,它的强大之处已经在语音、视觉、自然语言处理等领域得到了验证。

而真正把深度神经网络用于语音识别的重要文章是2012年的《Deep Neural Networks for Acoustic Modeling in Speech Recognition》,这篇文章由包括Hinton在内的四个研究小组参与,那时的深度学习刚开始发挥威力,一切听起来都是那么的棒。

自从这篇文章问世之后,深度学习不断取得进展。过去十年,尤其是DNN问世到现在,我们的“人工智能”有着怎样的变化?个人总结有三点:
- 在大数据利用方面有着惊人的有效性。表现是:DNN的巨大进步离不开海量数据的支撑。
- 对计算能力的需求日益增长。表现是:我们设计的算法越来越依赖于算力处理数据。
- 虽然DNN有巨大进展,但通用人工智能的进展缓慢。
现状
NLP需要更多参数,视觉需要更多层网络。先从数据谈起。当前我们需要海量的数据来应对计算机视觉的一些任务,包括面部识别、目标检测等等。
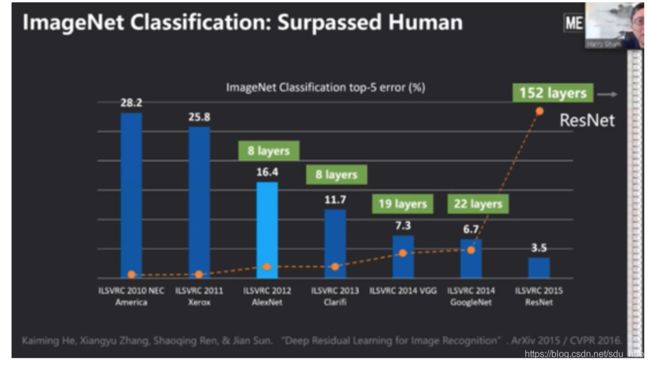
然而,对于深度学习而言,海量数据背后对应的是更多层的网络结构、更多层的网络参数。举例而言,如上图所示,2012年的AlexNet只有8层,到了2014年,19层的GoogLeNet和VGG拿下了当年ImageNet挑战赛(ILSVRC14)的双雄,又过了一年,152层的ResNet出现,于是为计算机视觉奠定了标准。
上面是计算机视觉的情况,那么NLP又如何呢?我敢肯定,NLP领域从计算机视觉那里“学”到了很多。

特别是近几年,模型之间的竞争非常激烈,从上图可以看到,从2018年的ELMo开始,其模型大小最初只有94M;2019年BERT出世,大小是ELMo 3倍多。尤其是著名的GPT-2,已经有了1.5B参数量,而最近刚发布的GPT-3更是达到了175B。
GPT-3的纪录也没有保持多长时间,谷歌推出的G-Shard带着600B参数走进大众的视野。所以,你可以想象,这场“竞赛”将会继续,人们接下来还会借用“DNN模型”学习更多的数据。

计算机架构也产生了许多进步,尤其是越来越多的人正在思考是否有一个以“神经计算”命名的新范式,此范式区别于传统的冯诺依曼架构,也可能颠覆传统。虽然非常激动人心,但是真正实用的系统不是很多。
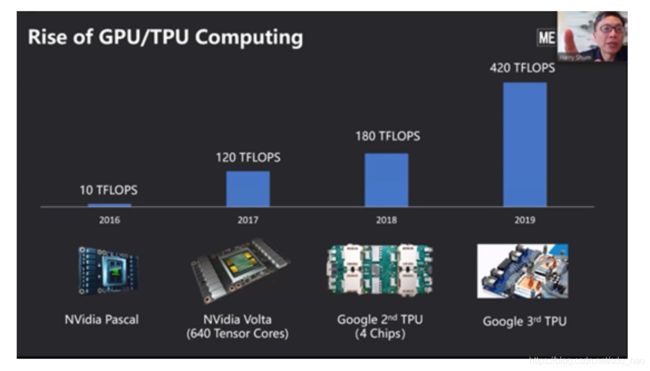
GPU和TPU的性能在近几年不断上升,如上图所示,2016年的 NVIdia Pascal 只有10 TFLOPS,而在2017,英伟达开发的 NVidia Volta 已经上升为120 TFLOPS了,2018年谷歌第二代四核TPU达到了180 TFLOPS,2019年谷歌开发的第三代TPU比第二代“快”了 两倍还多。

CPU的“规格”也在发生变化,2010年~2015年期间,CPU从“大盒子”慢慢转变为“小盒子”,目的是为了能构建更大的模型,处理更多的数据,以及加强团队合作。但是,从2015年开始,一个GPU小盒子已经满足不了需求了,“GPU的小盒子”慢慢又转向“GPU/TPU大盒子”了。
从算法到计算结构都产生了许多进步,深度学习也已经解决了很多实际问题,那么我们真的获得了智能么?现实是,我们并没有真正从这些海量的数据和海量的计算中获得太多的智能。
深度学习本质上还是一个黑箱,我们不知道到底发生了什么,也无法解读很多现象。例如下面这个例子。
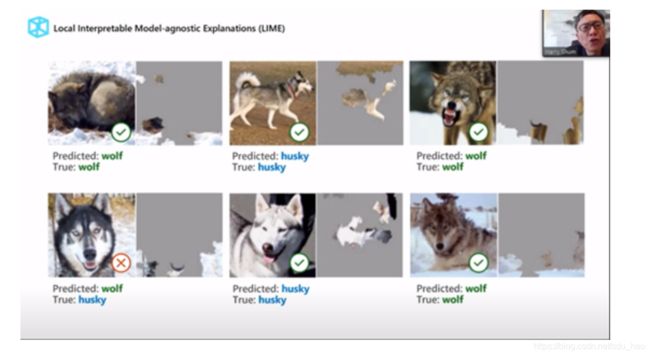
用已经训练好的神经网络检测图片中的动物是狼还是哈士奇。在下面6张照片中,只有左下角的一张被识别错了。
这个模型5/6的准确率非常高对吧?那么我应该高兴么?不确定,这取决于你想要什么。如果认为是一只哈士奇,却把狼带回家,那麻烦就大了。
让我们看看模型到底发生了什么,这个深度神经网络到底是通过观察图像中的哪些区域来分辨是狼还是哈士奇的?AI并非像我们理解的那样通过动物的外形来辨别的,而是在观察图像中有没有雪,如果有雪,那就是狼。
所以你以为你训练了一个非常强大的模型,实际上并非如此,这就是我一直在强调的:模型的可解释性十分重要。

上面是计算机视觉的例子。同样,我们在自然语言处理领域中使用DNN也会出现问题。如上图所示,如果没有标蓝文字,那么DNN模型处理还是不错的,但是加上了“蓝色噪音”就意味着模型有了“对抗性攻击”,处理结果完全达不到预期。
再者,在情感分析中,如果对输入稍微改变一些,预测结果有可能从“负面情绪”转到“正面情绪”。

再举一个GPT-2的例子,如上图所示,输入一句话,它会预测一句你想得到的话。例如,输入:两名士兵走进酒吧。GPT-2的输出是在Mosul酒吧,他们花光所有的钱用来买酒。嗯,似乎也能说得过去。
但是,再看这句:昨天我把衣服送到干洗店,到现在还没有来取。我的衣服呢?GPT-2的回答是:在我妈妈的房子里。
还有这句:木头上有六只青蛙,两只离开后,有三只加入,请问现在有几只?GPT-2:17只。
显然,在问答和算术方面,自然语言处理还有很大的进步空间。因此,通过上面这些例子,我们可以得到一个结论,尽管在过去几十年里AI取得了令人难以置信的进步,但是在大数据利用方面的不合理,加上深度学习“魔术”般的效果,我们离真正的智能还有很长的路要走。
从深度学习到深度理解
我们必须认真思考智能的真正含义是什么,这也是我今天真正想表达的。如果把人工智能进行分类,可以分为弱人工智能和强人工智能。

其中,弱人工智能对应的是深度学习,围绕单一任务点,需要大量数据做支撑,有时候不那么可靠,可移植性差/移植过后需要大量重新训练。正如上面GPT-2中的那些例子,深度学习支撑的“智能”在转移和泛化方面差了不少。
强人工智能(robust AI)对应深度理解,强调系统化地解决宽泛的问题,具备灵活与动态的推理能力,可以很好地移植到不同场景。显然,我们当前需要的是强人工智能。毕竟,我们想要综合各种来源的知识,期望AI能够对世界上正在发生的事情进行推理。就像人类一样,能够在一种语境中学习,在另一种语境中应用。
那么,近期有没有从深度学习转向深度理解的机会?在我看来,当前一些机器学习的结果对于每一个任务来说,已经不只是“分类器”,而是robust AI 智能体。例如它可以通过实践继续学习技能和知识(强化学习),以及探索示例(无监督学习)。这类智能体的特点是用比较少的学习次数,就能解决非常新的任务。
事实上,我最近思考robust AI的时候,对三个方面比较感兴趣,感觉这三个方面在实现robust AI时大有可为:
- 构建大规模的强机器学习仿真器。不仅是游戏,还有自动驾驶等复杂系统。
- 对于机器学习本质的深度理解。从优化功能开始,思考我们从里面真正学到的是什么。
- 基于神经与符号的混合模型(Hybrid Neural/Symbolic Model for Robust AI)。

前两个不是今天的重点,我会介绍基于神经与符号的混合模型。最近,雷蒙德微软研究院写了一篇论文,题目为《SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trainedAuto-regressive Model》,文章中提出了一种新的方法,能够利用迁移学习进行高效地大规模构建面向任务的对话系统。
在我看来,这篇文章有两个亮点,其一是有个预训练模型GTG(Grounded Text generator),其二是该方法实现了真正的会话学习。下面我主要讲讲GTG。

如上图所示,是一个多领域对话任务的示意,其结果经过微调GTG产生。在对话的一开始,人类就要求推荐一个博物馆;机器紧接着根据景点搜索、位置等信息给出了建议。随后,人类又要求在相同的位置进行预订餐馆,并要求餐馆里有印度食物。机器根据 same area 推断出了人类所要求的位置在“小镇中心”,显示出了很强的推理能力。
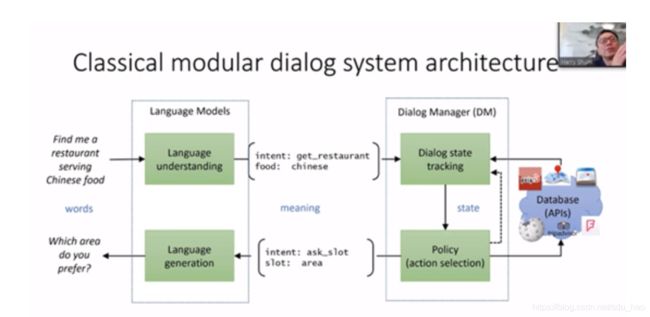
那么,这里面发生了什么呢?先看看经典的模块化对话系统架构,一般包括四个关键模块:
- 自然语言理解(Natural LanguageUnderstanding, NLU) :对用户的文本输入进行识别解析,得到槽值和意图等计算机可理解的语义标签。
- 对话状态跟踪(Dialog StateTracking, DST) :根据对话历史,维护当前对话状态,对话状态是对整个对话历史的累积语义表示,一般就是槽值对(slot-value pairs)。
- 对话策略(Dialogue Policy):根据当前对话状态输出下一步系统动作。一般对话状态跟踪模块和对话策略模块统称为对话管理模块(Dialogue manager,DM)。
- 自然语言生成(Natural LanguageGeneration, NLG):将系统动作转换成自然语言输出。

那么一个robust AI 系统是什么样子的呢?如上所示,有两部分,第一部分是Narrow AI, 与经典的模块化对话系统并无区别,系统的第二部分试图将知识纳入体系,希望构建深度理解模型。这种深度学习与知识相结合的混合模型,构建起来非常困难,需要用现代机器学习手段实现知识/推理/认知模型,用深度学习的方式表示知识与常识(entity linking),还需要用于对话状态跟踪(dialog statetracking)的强化学习、用迁移学习进行预训练与微调等等。

上面论文中提到的SOLOIST就是robust AI 系统的一种尝试,其主要思想是:基于Transformer的自动回归语言模型对对话系统进行参数化,并可以将不同的对话模块归入一个单一的神经网络模型。

GTG模型与GPT模型对比也有比较大的优势:GPT是学习如何理解和生成自然语言,而GTG是学习预测对话状态,产生grounded responses(真实响应)来完成任务。具体任务测试对比如上图所示。
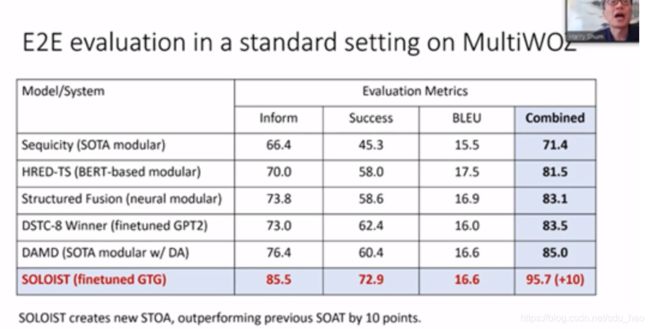
GTG在两个公开基准MultiWOZ和CamRest 中也进行了测试,在考虑Inform、Success、BLEU三个维度后,加总出一个综合得分,已经优于当前的SOTA模型。
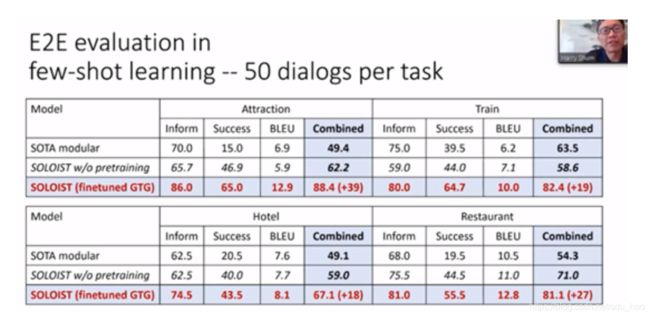
SOLOIST在新任务的“适应性”上也比当前的SOTA模型更加高效。所以,一个基于混合模式的强人工智能系统真的非常有效。
最后,我总结一下,现在是时候从深度学习转向深度理解了。当然,这也并不是说我们不应该继续“攻坚”深度学习。