python网络爬虫与信息提取(一)了解request库
本笔记是看北理嵩天老师的视频课程记录,来源于中国大学mooc
(一)前言
Requests库
robots.txt 协议
beatiful soup 解析html页面
Projeets 实战项目a/b
re 正则表达式 提取我们最关键信息
本课程实例
京东商品页面爬取
亚马逊商品页面爬取
百度/360搜索关键词提取
网络图片的爬取和存储
ip地址归属地的自动查询
中国大学排名定向爬虫
淘宝商品比价定向爬虫
股票数据定向爬虫
股票数据专业爬虫
表情包专业爬虫
requests库7个主要方法
request() 构造一个请求 支撑一下各个方法的基础方法
requests.rquest(get,erl,其他参数)
get() 获取html网页的主要方法
head 获取html网页头信息的方法
post 向html网页提交post请求的方法 附加新的资源
put 向html网页提交put请求 存储一个资源,覆盖原资源
patch 向html网页提交局部修改需求 改变该处资源的部分内容
delete 向html网页提交删除需求 删除url位置存储的资源
get response对象 response对象的属性
r.status_code: http请求的返回状态 200表示连接成功 404连接失败
r.text http相应内容的字符串形式 即,url对应的页面内容
r.encoding 从http header中猜测的响应内容编码方式
r.apparent_encoding 从内容分析出的响应内容编码形式(备选编码方式)
r.content http 响应内容的二进制形式
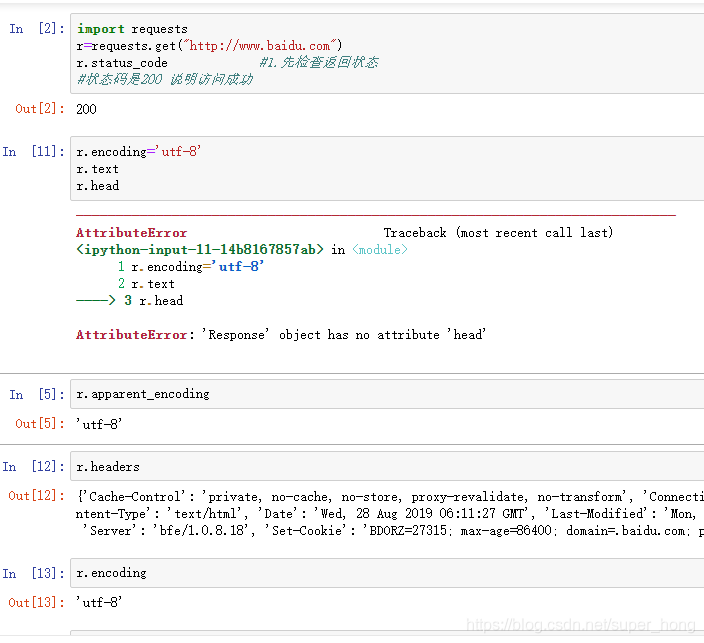
如果header中不存在charset字段,则认为encoding编码为iso-8859-1,但是这个编码不能解析中文。encoding只是在header中提取编码,apparent_coding提取的是内容的编码,所以后者更加准确。
(二)requests库
(1)爬取网页的通用代码框架
常用的是网页爬取方式是:requests.get()
但是网络连接有风险,所以get 不能处理所有的问题 所以处理异常很重要。
常用的异常:
requests.ConnectionError 网络连接错误异常 如dns查询失败 拒绝连接等
requests.HTTPError http错误异常
requests.URLRwquired url错误异常
requests.TooManyRedirects 超过最大定向次数 产生重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求url超时 产生超时异常
r.raise_for_status :如果不是200 产生异常requests.HTTPError
import requests
def Gethttltext(url):
try:
r=requests.get(url)
r.raise_for_status
r.encoding=r.apparent_encoding
return r.text
except:
return “连接失败”
url=“http://www.baidu.com”
print(Gethttltext(url))

url缺失http:

(2)http协议和requests库的方法
http 超文本传输协议:是一种基于“请求与响应”模式的 无状态的应用层协议
url格式 http://host[:port][path]
host:合法的internet主机域名或者ip地址
port:端口号,缺省端口为80,可省略
path:请求资源的路径
get() 获取html网页的主要方法
head 获取html网页头信息的方法
post 向html网页提交post请求的方法 附加新的资源
put 向html网页提交put请求 存储一个资源,覆盖原资源
patch 向html网页提交局部修改需求 改变该处资源的部分内容
delete 向html网页提交删除需求 删除url位置存储的资源
put和patch的区别:
假设url位置有一组20个字段的数据,如果想更新username,其他不变
patch,仅向url提交username的局部更新请求
put:需要把20个字段全部提交给url,未提交的字段就被删除
使用put要谨慎
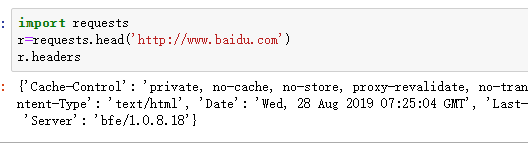
requests的head()方法

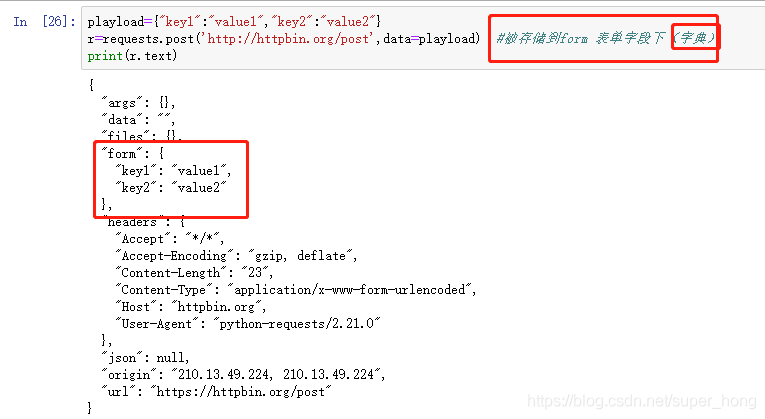
requests.rquest(get,url,其他参数)
其他13个参数包括 ,前四个最重要
params:字典或者字节序列,作为参数增加到url中,以筛选url的部分资源
data:字典、字节序列或文件对象,作为request的内容
json :json格式的数据,作为request的内容
headers:字典,http定制头
以及 cookies auth files 等13个访问控制参数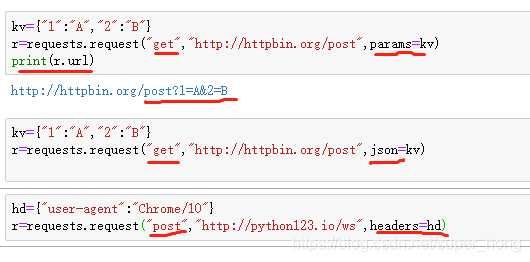
注意:用到最多的是get,因为安全问题,大部分网站内容是不允许被修改的。爬虫用的最多的是提取,而不是提交的方法。
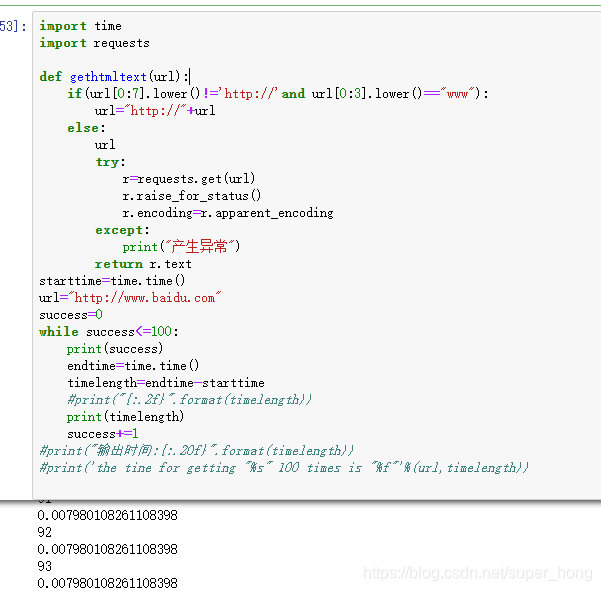
第一节中的讨论题是 爬取某一网页100次,看爬取时间。以下是看了两个同学的结论 相对其他答案时间要短很多 不知道是不是我的代码有问题

(三)网络爬虫引发的问题。
爬虫分类:
1.爬取网页,玩转网页 requests库 90%
小规模 数据量小,对速度不敏感
2.爬取网站 爬取系列网站 scrapy库
中规模 数据规模较大 爬取速度敏感 爬取速度要赶上更新速度
例如 爬取
3.爬取全网 需要定制开发
大规模 搜索引擎 爬取速度关键
带来问题:
1.爬虫会对服务器性能带来“骚扰”影响
2.服务器上的数据有产权归属
3.泄露隐私
爬虫限制:
1.来源审查 判断user-agent
2.发布公告 robots协议
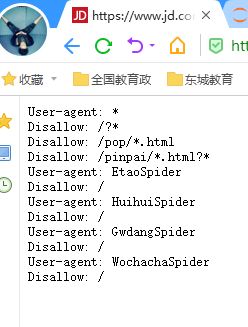
robots协议:
作用:网站告知爬虫哪些数据可以爬取 那些不行
形式:robots.txt 放在网站的根目录下
遵守协议:
可以不遵守 但是很可能会违反法律
但是还是要遵守,类人类行为可以不遵守。
(四)具体案例
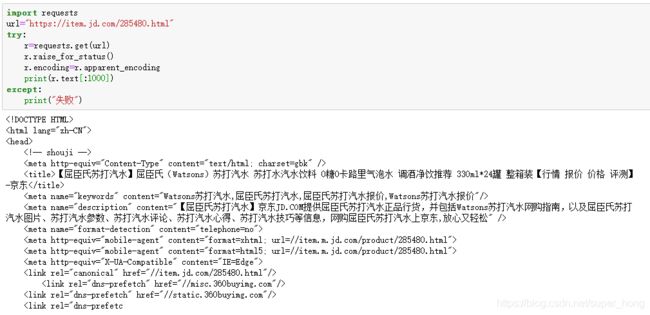
(1)京东商品页面爬取
import requests
url=“https://item.jd.com/285480.html”
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print(“失败”)
 (二)亚马逊商品页面
(二)亚马逊商品页面
有些网站如亚马逊不支持网络爬虫爬取信息,所以会进行来源审查,限制user-agent
此时我们可以对user-agent进行修改成浏览器的名称 Mozilla/5.0。
需要通过headers字段修改
r.raise_for_status() 如果状态码是200则成功 不是200则意味着异常
(以下代码Wie2017年的代码,从爬取的结果可以看出来,亚马逊又新增了防爬取的验证,导致本次爬取失败。)

(3)百度360搜索关键词提交
提交关键词 输出搜索结果
主要是搜索引擎关键词提交接口,所以关键点是构造url即可实现
http://www.baidu.com/s?wd=keyword
http://www.so.cim/s?q=keyword 360
params:字典或者字节序列,作为参数增加到url中,以筛选url的部分资源

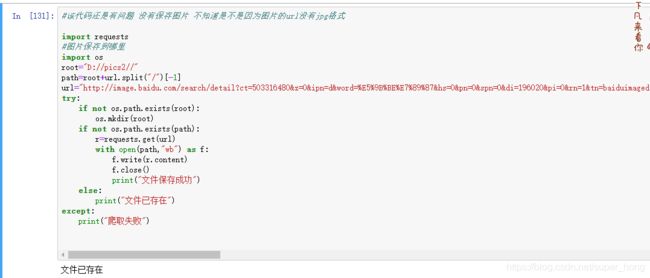
(4)网络图片的爬取和存储
关键点在于:
1.写出存储位置
2.图片是二进制格式,所以存储的格式是二进制 r.content
(5)ip地址归属地的自动查询
1.ip138的网址可以手动查询ip地址
.2把text全部打印出来可能使idle失效,所以打印了最后500个字符
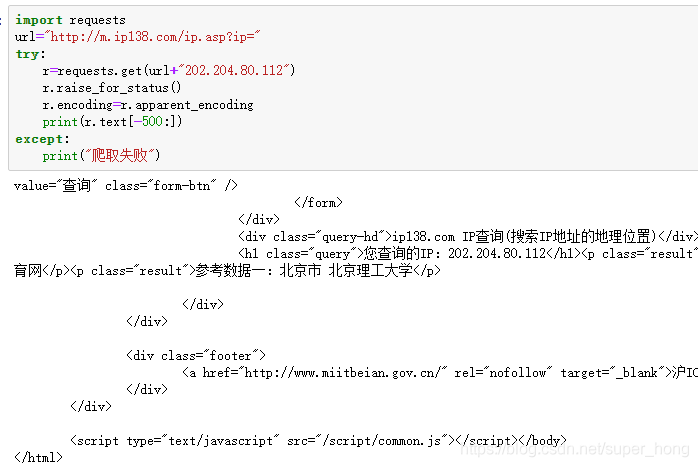
总结:
1.案例二和案例四 并没有返回我们想要的结果 需要进一步查找原因。
2.写出代码并不困难 最关键的是 思考全面 无论什么状况都不报错。