在机器学习项目中该如何选择优化器
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Philipp Wirth
编译:ronghuaiyang
导读
几种流行的优化器的介绍以及优缺点分析,并给出了选择优化器的几点指南。
本文概述了计算机视觉、自然语言处理和机器学习中常用的优化器。此外,你会找到一个基于三个问题的指导方针,以帮助你的下一个机器学习项目选择正确的优化器。
找一份相关的研究论文,开始使用相同的优化器。
参考表1并将数据集的属性与不同优化器的优缺点进行比较。
根据可用的资源调整你的选择。
介绍
为你的机器学习项目选择一个好的优化器是非常困难的。热门的深度学习库,如PyTorch或TensorFlow,提供了广泛的优化器的选择,不同的优化器,每个都有自己的优缺点。然而,选择错误的优化器可能会对你的机器学习模型的性能产生重大的负面影响,这使得优化器在构建、测试和部署机器学习模型的过程中成为一个关键的设计选择。
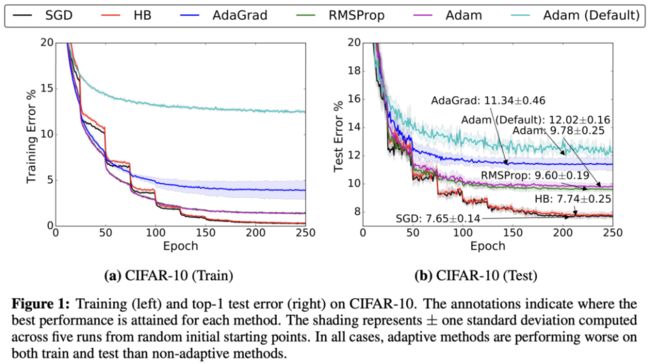
选择优化器的问题在于,由于no-free-lunch定理,没有一个单一的优化器可以在所有场景中超越其他的。事实上,优化器的性能高度依赖于设置。所以,中心问题是:
哪个优化器最适合我的项目的特点?
下面的内容给出了回答上述问题的一个指南。它由两个主要段落组成:在第一部分,我将向你快速介绍最常用的优化器。在第二部分中,我将为你提供一个三步计划来为你的项目选择最好的优化器。
一些最常用的优化器
在深度学习中,几乎所有流行的优化器都基于梯度下降。这意味着他们反复估计给定的损失函数L的斜率,并将参数向相反的方向移动(因此向下爬升到一个假设的全局最小值)。这种优化器最简单的例子可能是随机梯度下降(或SGD),自20世纪50年代以来一直使用。在2010年代,自适应梯度的使用,如AdaGrad或Adam已经变得越来越流行了。然而,最近的趋势表明,部分研究界重新使用SGD而不是自适应梯度方法。此外,当前深度学习的挑战带来了新的SGD变体,如LARS或LAMB。例如,谷歌研究在其最新论文中使用LARS训练了一个强大的自监督模型。
下面的部分将介绍最流行的优化器。如果你已经熟悉了这些概念,请转到“如何选择正确的优化器”部分。
我们将使用以下符号:用w表示参数,用g表示模型的梯度,α为每个优化器的全局学习率,t为时间步长。
Stochastic Gradient Descent (SGD)
![]()
在SGD中,优化器基于一个小batch估计最陡下降的方向,并在这个方向前进一步。由于步长是固定的,SGD会很快陷入平坦区或陷入局部极小值。
SGD with Momentum

其中β < 1,使用了动量,SGD可以在持续的方向上进行加速(这就是为什么也被叫做“重球方法”)。这个加速可以帮助模型摆脱平坦区,使它更不容易陷入局部最小值。
AdaGrad

AdaGrad是首个成功的利用自适应学习率的方法之一(因此得名)。AdaGrad根据梯度的平方和的倒数的平方根来衡量每个参数的学习速率。这个过程将稀疏梯度方向上的梯度放大,从而允许在这些方向上执行更大的步骤。其结果是:AdaGrad在具有稀疏特征的场景中收敛速度更快。
RMSprop

RMSprop是一个未发布的优化器,在过去几年中被过度使用。这个想法与AdaGrad相似,但是梯度的重新缩放不那么激进:梯度的平方的总和被梯度平方的移动平均值所取代。RMSprop通常与动量一起使用,可以理解为Rprop对mini-batch设置的适应。
Adam

Adam将AdaGrad,RMSprop和动量法结合在一起。步长方向由梯度的移动平均值决定,步长约为全局步长的上界。此外,梯度的每个维度都被重新缩放,类似于RMSprop。Adam和RMSprop(或AdaGrad)之间的一个关键区别是,矩估计m和v被纠正为偏向于零。Adam以通过少量的超参数调优就能获得良好性能而闻名。
LARS

LARS是使用动量的SGD的一种扩展,具有适应每层学习率的能力。它最近引起了研究界的注意。原因是由于可用数据量的稳步增长,机器学习模型的分布式训练已经流行起来。其结果是批大小开始增长。然而,这导致了训练中的不稳定。Yang等人认为,这些不稳定性源于某些层的梯度范数和权重范数之间的不平衡。因此,他们提出了一个优化器,该优化器基于一个“trust”参数η < 1和该层的梯度的范数的倒数,对每一层的学习率进行缩放。
如何选择正确的优化器?
如上所述,为你的机器学习问题选择正确的优化器是困难的。更具体地说,没有一劳永逸的解决方案,必须根据手头的特定问题仔细选择优化器。在下一节中,我将提出在决定使用某个优化器之前应该问自己的三个问题。
与你的数据集和任务类似的state-of-the-art的结果是什么?使用过了哪些优化器,为什么?
如果你正在使用新的机器学习方法,可能会有一篇或多篇涵盖类似问题或处理类似数据的可靠论文。通常,论文的作者已经做了广泛的交叉验证,并且只报告了最成功的配置。试着理解他们选择优化器的原因。
举例: 假设你想训练生成对抗性网络(GAN)来对一组图像执行超分辨率。在一些研究之后,你偶然发现了一篇论文:”Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network,” ,其中研究人员使用Adam优化器来解决完全相同的问题。Wilson等人认为,训练GANs并不等于解决最优化问题,Adam可能非常适合这样的场景。因此,在这种情况下,Adam是优化器的一个很好的选择。
你的数据集是否具有某些优化器的优势?如果有,是哪些,如何利用这些优势?
表1显示了不同优化器及其优缺点的概述。尝试找到与数据集的特征、训练设置和目标相匹配的优化器。
某些优化器在具有稀疏特征的数据上表现得非常好,而另一些优化器在将模型应用于之前未见过的数据时可能表现得更好。一些优化器在大batch中工作得很好,而另一些优化器可以收敛到很陡峭的极小值但是泛化效果不好。

例子:对于你当前工作的项目,你必须将用户反馈分为积极反馈和消极反馈。你考虑使用bag-of-words作为机器学习模型的输入特征。由于这些特征可能非常稀疏,你决定使用自适应梯度的方法。但是你想用哪一种呢?考虑表1,你看到看到AdaGrad具有自适应梯度方法中最少的可调参数。看到你的项目有限的时间表,你选择了AdaGrad作为优化器。
你的项目所具有资源是什么?
项目中可用的资源也会影响选择哪个优化器。计算限制或内存约束,以及项目的时间表可以缩小可行选择的范围。再次查看表1,你可以看到不同的内存需求和每个优化器的可调参数数量。此信息可以帮助你评估你的设置是否支持优化器所需的资源。
例子:你在做一个项目,在该项目中,你想在家用计算机上的图像数据集上训练一个自监督模型(例如SimCLR)。对于SimCLR这样的模型,性能随着batch size大小的增加而增加。因此,你希望尽可能地节省内存,以便能够进行大batch的训练。你选择一个简单的不带动量的随机梯度下降作为你的优化器,因为与其他优化器相比,它需要最少的额外内存来存储状态。
总结
尝试所有可能的优化器来为自己的项目找到最好的那一个并不总是可能的。在这篇博客文章中,我概述了最流行的优化器的更新规则、优缺点和需求。此外,我列出了三个问题来指导你做出明智的决定,即机器学习项目应该使用哪个优化器。
作为一个经验法则:如果你有资源找到一个好的学习率策略,带动量的SGD是一个可靠的选择。如果你需要快速的结果而不需要大量的超参数调优,请使用自适应梯度方法。

—END—
英文原文:https://www.whattolabel.com/post/which-optimizer-should-i-use-for-my-machine-learning-project

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!