Ubuntu上配置caffe+SSD及demo演示(附带问题汇总)
实验目的:
不得不说,现在深度学习真的是火,去年年底博主在做人脸识别这个应用的时候,选择的是faster rcnn,还没捂热乎,现在又再看SSD的东西了。SSD和faster rcnn都是目前比较经典的基于caffe深度学习架构的一种方法,是目前比较先进的目标检测方法,还有YOLO,不过在项目组里面博主被安排到了SSD这一边,所以本文就主要说一下安装配置SSD一路上比较坑的地方。目前把faster rcnn放一边而去选择SSD,其中一个最大的原因就是实时性的问题,因为未来需要在嵌入式端部署生产环境,我们选择了NVIDIA TX1,使用faster rcnn的话,一秒钟差不多也就5张左右,可能也没仔细去优化过,但是毕竟局限性摆着这儿,所以从实时性上考虑得话我们选择了SSD。
实验环境:
训练平台:NVIDIA K80
预测平台:NVIDIA TX1
语言 :C++,python
框架 :caffe
方法 :SSD
备注: 博主最近开始接手这件事的,所以目前一切部署都在k80上,demo演示也成功了,之后没问题的话就在TX1 上搭建环境了。根据faster rcnn的部署经验,不会有什么兼容性问题的。
实验步骤:
1.数据准备
ssd在github上的项目主页:weiliu89/caffe
(进入到主页以后,大家跟着里面的配置步骤来,部署caffe这里就不在多说了)
主页上给出的几个文件:
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar这里因为网络的问题,一般下得很慢,贴一下我放到百度云网盘中的资源:
链接:http://pan.baidu.com/s/1c1AwrRy 密码:ly70
这些是VOC的训练集,方便大家自己去亲手操作训练,不过我们今天的目的主要是运行demo,所以需要模型文件还有prototxt文件,在主页的最后,作者给出了自己最新的预训练好的模型文件,还有网络文件:
在我的百度云网盘里面也准备好了(这里我下载的是07++12的模型打包):
链接:http://pan.baidu.com/s/1kVoJ6GR 密码:leo6
有的人可能从github上clone比较慢,我这里提供一份在Windows上clone下来的,同样也是ssd分支的源码压缩包(需要注意的是,里面的脚本文件,是dos格式的,在vim里面用 set ff=unix将其改为unix格式):
链接:http://pan.baidu.com/s/1c19auCK 密码:rog6
目前来看,所有需要准备的东西全部齐全了,我们可以进行到下一步了。
2.实验开始
根据github主页上的步骤来做,在caffe路径下,建议大家在环境中将其路径定义为$CAFFE_ROOT,这样之后的一些脚本文件就不用改太多了。
cp Makefile.config.example Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8在这一步,有几个坑,第一个Makefile.config文件,如果你自己的电脑不是 cuda8.0的话,把config文件中的:
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
#-gencode arch=compute_61,code=sm_61
最后一句注释掉,不然之后报错会有不支持compute_61的错误;第二个坑就是,博主之前给服务器搭建环境的时候caffe的版本还比较老,SSD这个方法用的是目前最新的caffe版本吧貌似,所以主要注意的Linux系统的依赖库有(boost,hdf5),一开始我以为之前都搭建过caffe了,依赖库什么的全部搞定了,后来才想明白貌似caffe在全年年底的时候有过更新,不管怎样,大家在Linux下多敲一些命令,把依赖库都搞定吧,所以这里关于搭建环境推荐两篇博客,选择合适你的地方看就好:
GTX1070+CUDA8.0+Ubuntu16.04+Caffe+SSD 深度学习框架搭建 细节一步到位版
SSD安装及训练自己的数据集
3.demo演示
环境部署成功之后就开始demo的演示了,这里先跳过了caffe使用SSD训练自己的数据集,直接用官方的模型和网络文件来先演示下demo,先推荐一个博客:
SSD: Single Shot MultiBox Detector检测单张图片
网络上能搜到的大多数演示都挺无聊的,浪费大家时间,只是把官方主页上的东西搬过来,甚至于一张图片的效果都没有,官方给出的python的脚本是读取网络摄像头的,但是对于单张图片的检测,也给出了C++和python的接口,这里先说python的,文件是examples/ssd_detect.ipynb,这里需要用到ipython和jupyter库,这里其实我挺搞不懂,干嘛不直接写一个py文件好了,不过这也就留给我当做之后的任务吧。
具体的操作在上面贴出来的博客里面已经有了,我说几个遇到的问题:
第一:就是每个接触caffe的人都能会心一笑的路径问题,一共就几个文件,caffemodel文件,prototxt文件,一定要把路径确认好,推荐还是使用绝对路径比较靠谱;
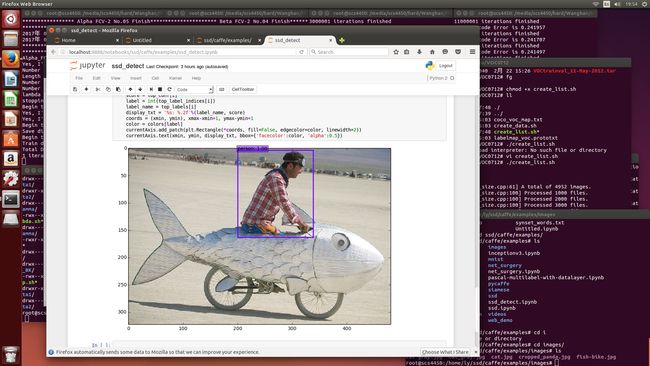
第二:在deploy.prototxt文件的最后,如下图所示:

第一个是输出文件的路径,一定要修改过来;第二个圆圈比较重要,在作者github主页上弄下来的data文件夹中,是没有data/VOC0712/test_name_size.txt这个文件的,大家需要到data路径下的相应位置,找到一个名字叫做create_list.sh的脚本,将里面data的路径修改为自己的,也就是我给大家的第一个百度云盘链接里面的那些文件到时候放到你的系统中的位置,训练完之后才有这个txt文件。
第三:上图中最后其实并不是4952,原本是1w+的,但是官方给的数据集中其实只有4952张图片,没去数过,反正运行create_list那个脚本,输出的统计信息就是4952张图片,改一下就好了。
然后主要的问题就这些了,现在可以看一看效果了。
实验效果:


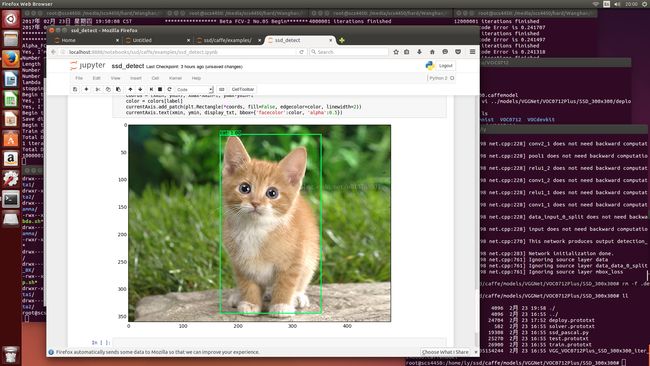
以上便是这一次实验的目的,至于性能什么的还没来得及去感受,这应该是之后几天的任务了,了解下cpp下的demo,然后梳理一下自己写一个python的接口文件出来,有什么问题欢迎大家一起留言沟通。或者QQ上联系:435977170.。