今日头条美图爬虫跟新
没想到吧,今天就跟新了:
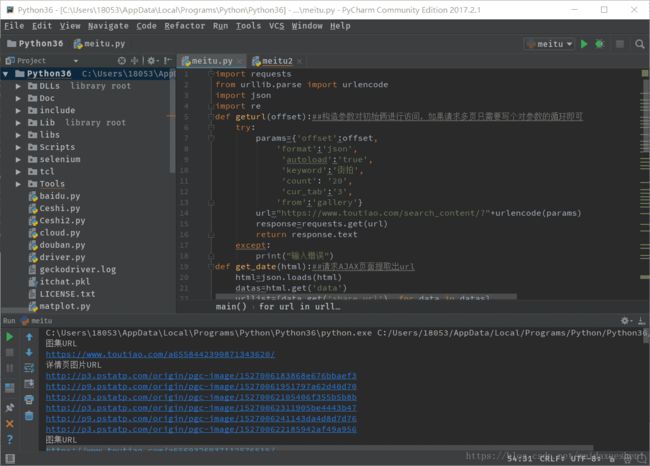
将图片写入文件的代码我没给出来,因为部分需要去重等等,我的知识还不足以去做到这样一件事,所以我就不误人子弟了,如果需要请求多页,只需要修改offset参数写个循环就OK,以下是我的代码和效果图:
import requests from urllib.parse import urlencode import json import re def geturl(offset):##构造参数对初始俩进行访问,如果请求多页只需要写个对参数的循环即可 try: params={'offset':offset, 'format':'json', 'autoload':'true', 'keyword':'街拍', 'count': '20', 'cur_tab':'3', 'from':'gallery'} url="https://www.toutiao.com/search_content/?"+urlencode(params) response=requests.get(url) return response.text except: print("输入错误") def get_date(html):##请求AJAX页面提取出url html=json.loads(html) datas=html.get('data') urllist=[data.get('share_url') for data in datas] return urllist def get_newurl(url):##因为上面提取出url是不能访问源码的,所以在这里需要时生成一个新的url demo=re.compile('group/(.*?)/',re.S) demos=demo.search(url) newurl="https://www.toutiao.com/a"+demos.group(1)+"/" print("图集URL") print(newurl) return newurl def get_onepage(url):##对新的俩进行解析,并将返回的数据生成一个字典 try: html=requests.get(url) html.encoding=html.apparent_encoding demo=re.compile('gallery: JSON.parse\("(.*?)"\)',re.S) demos=demo.search(html.text) iteam=demos.group(1) newiteam=json.loads(json.loads('"'+iteam+'"')) return newiteam except: print("请求详情页错误") return None def parse_onpageurl(iteam):##对字典进行提取,提取出每个图片的url-----然后后面要做的就是写如文件或者写入数据库,这个很简单我就不赘述了 print("详情页图片URL") urllist=[image.get('url') for image in iteam.get('sub_images')] for url in urllist: print(url) def main(): html=geturl(1) urllist=get_date(html) for url in urllist: urll=get_newurl(url) iteam=get_onepage(urll) parse_onpageurl(iteam) main()
效果图: