Storm学习(1)——基本的概念和工作原理
一、基本概念
1.相较于hadoop的优势
相对于hadoop而言,strom的优势在于对于应对大数据两的实时数据处理上,因为hadoop在处理大数据过程中高延时的特点使得其面对实时数据缺乏足够的应对策略,目前strom已经被广泛的应用在诸如金融系统,实时推送系统,预警系统,网站统计等多个场景中,他可伸缩性高,不存在数据丢失,高容错性,高健壮性等特点都使得他在未来拥有更广阔的天地
2.实时推送(数据实时处理)的核心
以消息队列作为核心技术,使用消息队列作为实时处理系统的数据源,而在消费者那端,使用死循环对消息队列进行监控,使得数据得以实时的被处理和存储
二、集群的结构特点
1.与hadoop相比较

nimbus是作为storm的主节点存在的,类似于hadoop中的jobtracker,主要存在的作用是负责集群分发的代码
supervisor是strom的工作节点,类似于hadoop中的tasktracker,它监听分配给他的节点,根据Numbus的指派在必要的时候启动和关闭工作进程
2.strom集群的基本架构
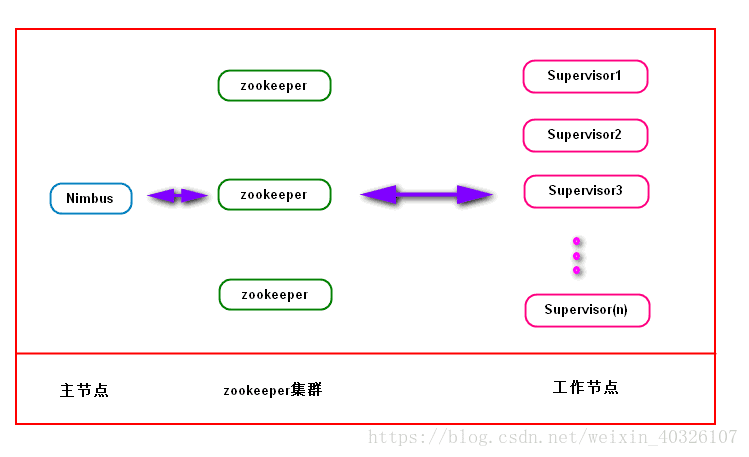
由上面的架构图可以初步的对strom集群做一个初步的了解:
1)集群是基于zookeeper集群存在的,Nimbus和Supervisor都是依赖于zookeeper建立的
2)主节点和工作节点的具体状态都保存在zookeeper中,主节点通过查看工作节点的状态文件是否存在判断工作节点的连接状态
3)主节点和工作接待点之间通过zookeeper集群进行协调,这使得Nimbus和Supervisor之间没有耦合,同时也提高了系统的健壮性
三、Storm原理简析
1. Bolt工作原理
bolt是作为一个消息处理者的角色存在的,它存在的主要作用有两个:接收处理数据和发送数据给下一个bolt
bolt工作图
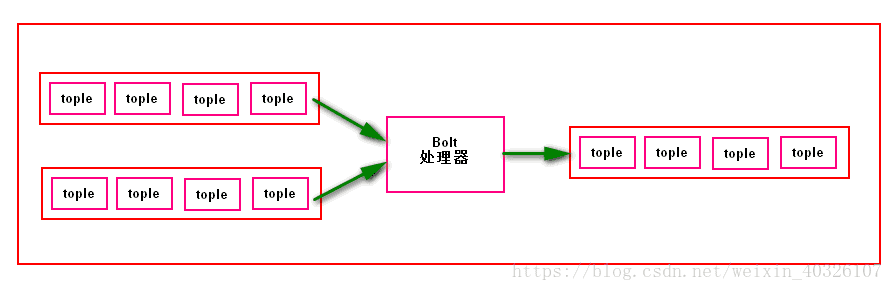
Bolt处理Stream内部的tuple,bolt可以消费任意数量的输入流,只要将流的方向导入到该blot,同时他也可以发送新的流给其他的bolt
Bolts
bolt处理消息的逻辑代码被封装在bolts中,其内部封装了的功能主要有:过滤,聚合,查询数据库等
bolts可以做简单的消息传递功能,也可以做复杂的消息处理,不过复杂的消息处理需要经过多级的bolts处理,此时,第一级的bolts可以作为后面一级bolts的输入级
bolts处理实时数据功能主要是基于其内的execute方法,execute(死循环)方法连续处理传入的tuple,成功的处理完每一个tuple后调用OutputCollector的ack方法,以通知Strom这个tuple完成了,当处理失败的时候,可以调用fail方法通知Spout端重新发送该tuple。
具体的处理流程是:Bolts处理一个输入tuple,然后调用ack通知strom自己已经处理过这个tuple了,Storm提供一个IBasicBolt会自动调用ack。
Bolts使用OutputCollector来发射tuple到下一级Bolt。
一个简单的多级bolts处理流:
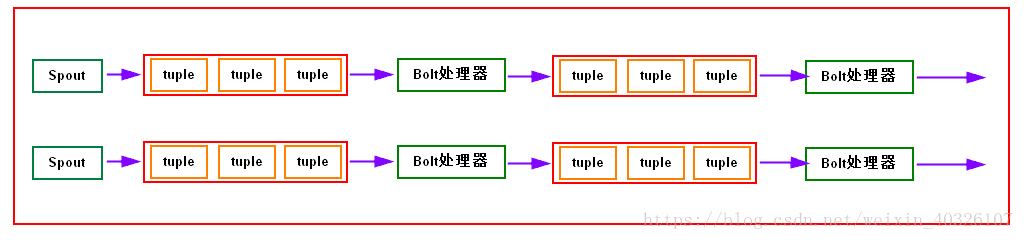
上图可以看到单一流程的多级bolts处理,其中:
Spout:Strom认为每一个Stream都有一个源,也就是原始元祖的源头,叫做spout
spout只能有下一级,它不是数据创造者,也是从其他的通道或者队列中获取数据
Tuple:Strom将stream中的元素抽象为tuple,每一个tuple都是一个Key List形式的值列表,每一个key都有一个名称name,并且这个可以是一个任意可序列化的类型
2.多级多源的数据处理
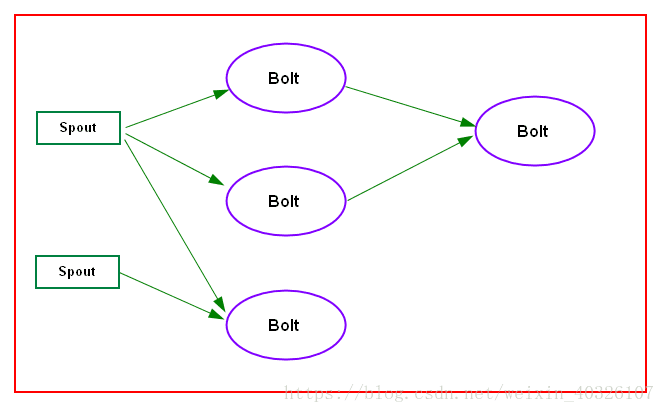
如上图,可以视之为一个简单的topology(拓扑),其中说明了数据在这个流中的处理过程,可以看出,Bolt可以有多个数据来源,同时,也可以将处理之后的数据传递到下一级
数据传输方式:
数据从Spout到Bolt或者从Bolt到Bolt是以广播的形式进行的
但是从单个Spout到单个Bolt有6中gouping形式(具体后面讨论)
Strom将stream中的元素抽象为tuple,每一个tuple都是一个Key List形式的值列表,每一个key都有一个名称name,并且这个可以是一个任意可序列化的类型。
拓扑的每个节点搜需要说明他所发出的元组的名称name,其他的节点只需要订阅该name就可以接收处理