AdamTechLouis's talk:Deep Learning approaches to understand Human Reasoning
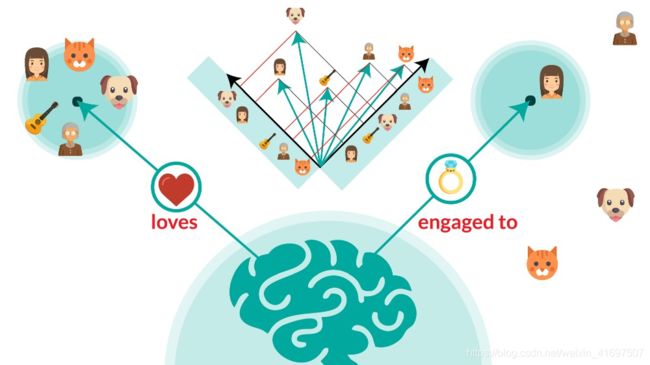
For a doctor who is using Deep Learning to find whether the patient has multiple sclerosis, it is not at all good to get a yes or no answer from the model. For a safety critical application such as autonomous cars , it is not enough to predict the crash. There is an urgent need to make machine learning models reason its assertions and articulate it to humans. Visual Question Answering work by Devi Parikh, Druv Batra [17] and work on understanding visual relationships by Fei-Fei Li team [16] are few leads to achieve it. But there is long way to go in terms of learning reasoning structures. So in this blog, we are going to talk about, How to integrate Reasoning into CNNs and Knowledge Graphs.
For a long time, reasoning has been understood to be a bunch of deductions and inductions. The study of abstract symbolic logic allowed canonicalization of these concepts as described by John Venn [1] in 1881. It’s like those IQ Tests that we take. A implies B, B implies C, so A implies C. etc. Think of it as a bunch of logical equations.
But later, this idea of fixed induced/deduced reasoning was dismantled in 1975 by L.A. Zadeh [2], where he describes the concept of approximate reasoning. It also introduces term called linguistic variable(age=young,very young, quite young, old,quite old,very old) as opposed to numeric variables(age=21,15,19,57,42,72) which forms the bedrock for establishing fuzzy Logic via words [3]. This is a standardization which takes care of fuzziness or ambiguity in the reasoning.
For example, in our day to day language, we don’t say “I am talking to a 21-year-old male of height 173 cm”, I would say “I am talking to a tall young guy” . Fuzzy Logic is, therefore, taking into consideration the vagueness of the argument for constructing the reasoning models.
In Spite of incorporating fuzziness, it couldn’t capture the essence of Human Reasoning. One of the explanations can be that, apart from simple deductions like “A is not B, B is C, means A is not C”, there is an overwhelming element of implicit reasoning in case of the Human Rationale. Within a flash, humans can deduce things without going through the sequence of steps. Sometimes it is instinctive too. If you have a pet dog, then you know what it does when you snatch the toy from its mouth.
Humans display a phenomenal ability to abstract and improve the explicit forms(One Shot, Differentiable Memory) of reasoning over time. This means it is not concocted in purely statistical forms. Statistical Learning [4] based Language Model is an example of Implicit learning, where we do not use any rules, propositions, fuzzy logic. We instead allow the temporal models to learn the long range dependencies [5] [6] . You can imagine this as an autocomplete feature in phones.
You can either train reasoning structures to predict the most logical phrase or let the statistical methods predict a probabilistically suitable completion phrase.
These kind of models are unable to work for rare occurrences of words or images because they forget this information due to rarity. It also fails to generalize a concept. For instance, if we see one type of cow, we are able to generalize our learning to all the other types cows. If we hear an utterance once, we are able to recognize its variant in different accents, dialects and prosody.
One-shot Learning [7] paves the way to learn a rare event based on our ability to make use of past knowledge no matter how unrelated it is. If a person has only seen squares and triangles from birth , like the infamous cat experiment [8] ), and then exposed to a deer for the first time, a person will not just remember it as an image, but also sub-consciously store its similarity w.r.t squares and triangles. For one-shot learning, a memory bank becomes imperative. Memory has to interact with the core model, to make it learn efficiently and reason faster.
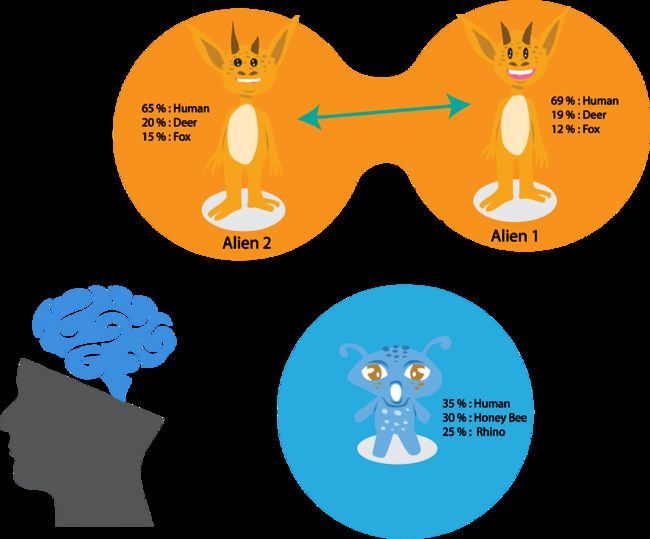
I know that you might be struggling with this term One Shot. And so, here’s a simple example where we use Imagenet for One Shot Learning. Now think of the 1000 classes of imagenet like monkey, humans, cars etc as Judges in a reality show. Each of them giving a score based on how likely it is to be a monkey or a human and so on.
Let’s assume that there is a 1001 th class for which the model is not trained. If I take two items from this class, then none of them would give a confident score, but if we look at this 1000 vector score for both items, they may have similarity. For example Galapagos Lizard, may get upvotes from crocodile and lizard more than any other class judges. The Judges are bound to give similar scores to images of Galapagos Lizard, even though it is not in the class list and without having even a single image in the training data. This feature similarity based clubbing is the simplest form of One Shot Learning.
Recent work on Memory augmented Neural Networks by Santoro [9] considers automating the interaction with memory via differentiable memory operations, inspired by Neural Turing Machines [10].
So the network learns to decide the feature vectors, which it considers useful, to be stored into differentiable memory block along with a class it has never seen. This representation keeps evolving. It gives the neural network the ability to learn “how to learn quickly”, which is why they call it meta-learning. So it starts behaving more like humans. Our ability to relate past with present is fantastic. For instance “If I have not seen this weird alien creature, I can still say that it looks more like a baboon or a gorilla with horns of a cow.
The key takeaway from this discussion is that
- Purely explicit reasoning based on fuzzy logic fails to capture the essence of human reasoning.
- Implicit models like Traditional One-Shot Learning, are incapable of generalizing or learning from the rare events, by itself. It needs to be augmented with memory.
This structure of augmented memory can either be in form of an LSTM as presented by cho , sutskever[5] [6] or it can be a dynamic lookup table like santoro’s recent work. [9]. This dynamic lookup can further be enriched based on external knowledge graphs [11] as proposed by Sungjin from Bengio’s Lab. This is called Neural Knowledge Language Model.
Let’s say you want to learn how to complete an incomplete sentence. Now I can do this via simple Sequence to Sequence model. But it will not be good because of rare occurrence of named entity. It would have rarely heard “Crazymuse” before. But if we learn to fetch the named entities from Knowledge graphs, by identifying the topic or relation and also identifying whether to fetch from LSTM or from Knowledge graph, then we can make it complete the sentence with even rare named entities. This is a really awesome way to combine the power of rich Knowledge Graphs and Neural Networks. Thanks to Reddit ML group, and “What are you reading” thread that I got to read a curated set of papers.
Now what we just learnt opens up a host of possibilities in terms of reasoning and inference because knowledge representation (subject,predicate,object) allows us to perform more complex reasoning tasks similar to explicit fuzzy logic along with implicit statistical learning.
This ability to learn retrieval from Knowledge Graphs along with attention mechanism [12] [13] can lead towards explainable models.
Availability of question answering datasets such as SQUAD [14] [15] has helped make significant strides towards inferable language models. Recent works in Visual Question Answering [16] [17] [18] use datasets such as Visual Genome [19] ,CLEVR [20] and VRD [21] in order to translate an image to an ontology and learn visual relations for improved scene understanding and inference.
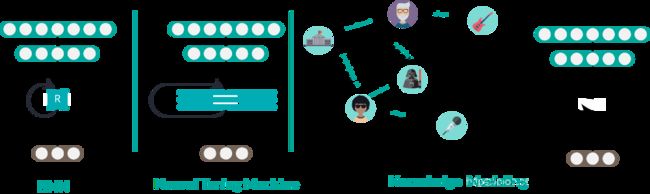
[Evolution of Architectures to learn Reasoning]
But again, despite the advances in question answering based on context on scene understanding, there are a few limitations
- The use of LSTMs for memory based models and learning attention shifts in terms of visual relationships[16] definitely improves the understanding of context and ability to generalize. But there is a lot more to be done in terms of learning and improving canonical forms of reasoning.
- The suffocation of using a structured pipeline of convolution neural network makes the model opaque to human interpretation. It may be suitable for basic classification and domain specific generative tasks, but not designed for reasoning. Instead if only we could directly learn richer multi-modal entity representation in Knowledge graphs and ontology as proposed in “Never Ending Learning” by Tom Mitchell [24]. Then we could learn cross domain reasoning structures and force the model to articulate its understanding of entity-relationship better.
I dream of a day, when machines will learn to reason. A day when we could ask Machines, why do you think this guy has multiple sclerosis. And then, it could find words to articulate its reasoning. I am aware of Naftali’s work on Information Bottleneck Principle and Michell’s [24] work on Never Ending Learning. But what’s missing is actively learning abstractions over basic reasoning structures provided by fuzzy logic.You can drive it by learning optimal policy via rewards, or some kind of validation based on one shot learning principles or some semi-supervised graph based approaches. But whatever be the driving factor, the model needs to learn to improve reasoning. The model needs to learn to associate this reasoning engine with rich feature representations coming from sounds or images which may even catalyze a loop of “improving representation, improving reasoning, improving representation, improving reasoning” just like Policy Iteration. And most importantly, the model should be able to articulate the abstractions to humans and say, “Hey humans, I think cats are cute, because their eyes resemble that of babies and are full of life unlike your monotonous routine ”
Till then, let’s keep training models and keep dreaming of the day the model is up and running. Because dreams are becoming reality faster than you can imagine!
About Me
Jaley is a youtuber and creator at Edyoda (www.edyoda.com). He has been a senior datascientist at Harman in the past and is super-curious to know the structure of Human Reasoning.
Show your support to independent well researched publications by giving claps.
My mini-course related to Knowledge Graphs
Course Link : Knowledge Graphs and Deep Learning
References
[1] John Venn. Symbolic logic. 1881.
[2] L.A. Zadeh. The concept of a linguistic variable and its application to approximate reasoning — i. Information Sciences, 8(3):199–249, 1975.
[3] Lotfi A Zadeh. Fuzzy logic= computing with words. IEEE transactions on fuzzy systems, 4(2):103–111, 1996.
[4] Eugene Charniak. Statistical language learning. MIT press, 1996.
[5] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
[6] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112, 2014.
[7] Li Fei-Fei, Rob Fergus, and Pietro Perona. One-shot learning of object categories. IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611, 2006.
[8]David Rose and Colin Blakemore. An analysis of orientation selectivity in the cat’s visual cortex. Experimental Brain Research, 20(1):1–17, 1974.
[9] Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. In International conference on machine learning, pages 1842–1850, 2016.
[10] Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
[11] Sungjin Ahn, Heeyoul Choi, Tanel Pärnamaa, and Yoshua Bengio. A neural knowledge language model. arXiv preprint arXiv:1608.00318, 2016.
[12] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning, pages 2048–2057, 2015.](https://arxiv.org/abs/1502.03044)
[13] Robert Desimone and John Duncan. Neural mechanisms of selective visual attention. Annual review of neuroscience, 18(1):193–222, 1995.
[14] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
[15] Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. arXiv preprint arXiv:1806.03822, 2018.
[16] Ranjay Krishna, Ines Chami, Michael Bernstein, and Li Fei-Fei. Referring relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6867– 6876, 2018.
[17] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015.
[18] QiWu, PengWang, Chunhua Shen, Anthony Dick, and Anton van den Hengel. Askme anything: Free-form visual question answering based on knowledge from external sources. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4622– 4630, 2016.
[19] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1):32–73, 2017.
[20] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages 1988–1997. IEEE, 2017.
[21] Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. Visual relationship detection with language priors. In European Conference on Computer Vision, 2016
[22] Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun Zhao. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), volume 1, pages 687–696, 2015.
[23] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems, pages 2787–2795, 2013.
[24] Tom Mitchell, William Cohen, Estevam Hruschka, Partha Talukdar, Bo Yang, Justin Betteridge, Andrew Carlson, B Dalvi, Matt Gardner, Bryan Kisiel, et al. Never-ending learning. Communications of the ACM, 61(5):103–115, 2018.