Python必学模块之CSV模块
文章目录
- 一、CSV简介
- 二、python读取CSV文件
- 2.1 csv.reader() 方法
- 2.2 csv.DictReader()方法
- 三、 python写入CSV文件
- 3.1 csv.writer()对象
- 3.2 csv.DictWriter()对象
- 四、csv文件格式化参数和Dialect对象
- 4.1 csv 文件格式化参数
- 4.2 Dialect 对象
一、CSV简介
CSV(Comma Separated Values)是逗号分隔符文本格式,常用于Excel和数据库的导入和导出,Python内置的CSV模块提供对CSV格式文件读取和写入的对象。
二、python读取CSV文件
2.1 csv.reader() 方法
csv.reader(csvfile, dialect=‘excel’, **fmtparams)
主要用于文件的读取,返回一个reader迭代对象, 用于在csv文件内容上进行行迭代。
参数解读:
| 参数 | 解释 |
|---|---|
| csvfile | 需要一个文件对象或者list对象 |
| dialect | 用于指定csv的格式模式不同程序输出的csv格式有细微差别 |
| fmtparams | 是一系列参数列表,主要用于设置特定的格式,以覆盖dialect中的格式 |
可用属性:
csv.reader对象是可迭代对象,包含以下属性:
- csv.reader().dialect #返回其dialect
- csv.reader().line_num #f返回读入的行数
- csvreader.fieldnames #返回标题字段名
代码实例:
'''
程序操作的 stock.csv 文件
'''
index,secID,ticker,secShortName,exchangeCD,tradeDate,preClosePrice,openPrice,highestPrice,lowestPrice,closePrice,turnoverVol
0,000001.XSHE,1,平安银行,XSHE,2017-12-1,13.38,13.4,13.48,12.96,13,178493315
1,000002.XSHE,2,万科A,XSHE,2017-12-1,31.22,30.5,32.03,30.5,30.73,55743855
2,000004.XSHE,4,国农科技,XSHE,2017-12-1,25.56,25.41,26.4,25.18,26.2,2211059
3,000005.XSHE,5,世纪星源,XSHE,2017-12-1,4.2,4.2,4.24,4.2,4.22,2365348
4,000006.XSHE,6,深振业A,XSHE,2017-12-1,9.85,0,0,0,9.85,0
5,000007.XSHE,7,全新好,XSHE,2017-12-1,16.66,0,0,0,16.66,0
6,000008.XSHE,8,神州高铁,XSHE,2017-12-1,8.48,8.48,8.74,8.41,8.59,5689054
7,000009.XSHE,9,中国宝安,XSHE,2017-12-1,7.6,7.61,7.63,7.53,7.58,9149395
8,000010.XSHE,10,美丽生态,XSHE,2017-12-1,5.13,5.13,5.23,5.11,5.21,6765580
9,000011.XSHE,11,深物业A,XSHE,2017-12-1,17.18,17.08,17.28,17,17.11,2474700
10,000012.XSHE,12,南玻A,XSHE,2017-12-1,9.19,9.1,9.28,9.02,9.11,35308183
11,000014.XSHE,14,沙河股份,XSHE,2017-12-1,12.6,12.49,12.73,12.45,12.64,1236110
12,000016.XSHE,16,深康佳A,XSHE,2017-12-1,6.2,6.34,6.54,6.31,6.43,29434715
13,000017.XSHE,17,深中华A,XSHE,2017-12-1,6.68,6.63,6.68,6.6,6.68,1562976
14,000018.XSHE,18,神州长城,XSHE,2017-12-1,7.16,7.16,7.21,7.1,7.15,5792996
15,000019.XSHE,19,深深宝A,XSHE,2017-12-1,12.15,0,0,0,12.15,0
16,000020.XSHE,20,深华发A,XSHE,2017-12-1,14.99,15.28,15.3,14.75,15,3250307
17,000021.XSHE,21,深科技,XSHE,2017-12-1,9.08,9.07,9.41,9.05,9.34,19877164
18,000022.XSHE,22,深赤湾A,XSHE,2017-12-1,24.14,0,0,0,24.14,0
19,000023.XSHE,23,深天地A,XSHE,2017-12-1,22.57,22.41,22.82,22.41,22.62,318725
20,000025.XSHE,25,特力A,XSHE,2017-12-1,40.56,40.25,40.67,40.08,40.17,1584600
使用csv.reader对象从csv文件读取数据,结果为列表对象row,需要通过索引row[i]访问。
import csv
# 读取CSV文件的两种方法
# ===========================================================
# csv.reader()方法
with open('stock.csv','r',encoding='gbk')as f:
Reads = csv.reader(f)
print(type(Reads)) # 结果:
<class '_csv.reader'>
secShortName 1
平安银行 2
万科A 3
国农科技 4
世纪星源 5
深振业A 6
全新好 7
神州高铁 8
....
略
2.2 csv.DictReader()方法
如果希望通过csv文件的首行标题字段名访问存储数据,则可以使用csv.DictReader对象读取
csv.DictReader(csvfile,fieldnames=None,restkey=None,restval=None,dialect=‘excel’,*args,**kwds)
也可叫next(reader), 返回的是一个reader字典对象
参数解读:
| 参数 | 解释 |
|---|---|
| csvfile | 需要一个文件对象或者list对象 |
| dialect | 用于指定csv的格式模式不同程序输出的csv格式有细微差别 |
| fmtparams | 用于指定字段名,如果没有指定,则第一行为字段名 |
| restkey和restval | 用于指定字段名和数据个数不一致时所对应的字段名或数据值 |
DictReader对象属性和方法:
方法:
csv.DictReader().next()# 称之为next(reader)
属性:
- csvreader.dialect # 解析器使用的方言的只读描述。
- csvreader.line_num #返回读入的行数
- csvreader.fieldnames #返回标题字段名
代码实例
with open('stock.csv','r',encoding='gbk')as f:
Reads = csv.DictReader(f)
print(type(Reads)) # 结果:
平安银行 2
万科A 3
国农科技 4
世纪星源 5
深振业A 6
全新好 7
神州高铁 8
....
略
三、 python写入CSV文件
3.1 csv.writer()对象
csv.writer(csvfile,dialect=‘excel’,**fmtparams)
主要用于把列表数据写入到csv文件。
参数解读:
| 参数 | 解释 |
|---|---|
| csvfile | 任何支持write()方法的对象,通常为文件对象 |
| dialect | 用于指定csv的格式模式不同程序输出的csv格式有细微差别 |
| fmtparams | 是一系列参数列表,主要用于设置特定的格式,以覆盖dialect中的格式 |
可用方法:
-
writer.writerow(row) # 方法,写入一行数据
-
writer.writerows # 方法,写入多行数据
可用属性:
writer.dialect # 只读属性,返回其 dialect
代码实例
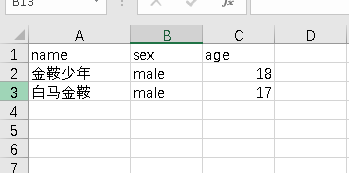
import csv
headers = ('name','sex','age')
students = [
("金鞍少年",'male',18),
("白马金鞍",'male',17),
]
with open("students.csv",'w',encoding='gbk',newline='') as fp:
writer = csv.writer(fp, dialect='excel')
writer.writerow(headers) # 写入一行
writer.writerows(students) # 写入多行
print(writer.dialect) # <_csv.Dialect object at 0x000001F166725DB0>
结果:
3.2 csv.DictWriter()对象
csv.DictWriter(csvfile,fieldnames,restval = ‘’,extrasaction = ‘raise’,dialect = ‘excel’,*args,**kwds)
参数解读:
extrasaction用于指定多余字段时的操作,其他参数同上
DictWriter对象方法:
- csvwriter.writerow(row) # 将row写入writer的文件对象,根据当前方言进行格式化。支持迭代
- csvwriter.writerows(rows) # 将行中的所有元素写入编写器的文件对象,并根据当前方言进行格式化。支持迭代
- DictWriter.writeheader() # 写入标题字段名
DictWriter对象属性:
csvwriter.dialect # 使用的方言只读描述
代码实例:
headers = ('name','sex','age')
students = [
{"name":"金鞍少年","sex":"male","age":18},
{"name":"白马金鞍","sex":"male","age":18},
]
# newline='' 写入内容不换行
with open("students2.csv",'w',encoding='gbk',newline='') as fp:
writer = csv.DictWriter(fp,headers,dialect='excel')
# 虽然DictWriter创建的时候有一个headers,但是想要写入数据进去,还是需要调用
# writer.writeheader()方法,否则,表头数据写入不进去
writer.writeheader() # 写入标题字段名
writer.writerows(students)
结果:
四、csv文件格式化参数和Dialect对象
4.1 csv 文件格式化参数
创建reader/writer对象时,可以指定csv文件格式化命名参数。
常用参数:
| 参数 | 作用 |
|---|---|
| delimiter | 用于分隔字段的分隔符。默认为"," |
| lineterminator | 用于写操作的行结束符,默认为“’\r\n ’ 。读操作将忽略此选项,它能认出跨平台的行结束符 |
| quotechar | 用于带有特殊字符(如分隔符)的字段的引用符号。默认为’ " ’ |
| quoting | 引用约定可选值有csv.QUOTE _ ALL(引用所有字段),csv.QUOTE_MINIMAL((引用如分隔符之类特殊字符的字段)默认),csv.QUOTE_NONNUMERIC((非数字字段)),csv.QUOTE_NON((不引用)) |
| skipinitialspace | 忽略分隔符后面的空白符。默认为False |
| doublequote | 如何处理字段内的引用符号。如果为True ,字符串中的双引号使用" "表示;如果为False,使用转义字符escapechar指定的字符 |
| escapechar | 用于对分隔符进行转义的字符串 |
| strict | 如果为True,读入错误格式的CSV行时将导致csv.Error;默认值为False |
代码示例:
import csv
def writecsv3(csvfilepath):
headers = ['学号', '姓名', '性别', '班级', '语文', '数学', '英语']
rows = [
{'学号': '100010', '姓名': '小南', '性别': '男', '班级': '1班', '语文': '70', '数学': '89', '英语': '85'},
{'学号': '100011', '姓名': '小风', '性别': '女', '班级': '6班', '语文': '79', '数学': '89', '英语': '85'}
]
with open(csvfilepath, 'w', newline='') as f:
f_csv = csv.DictWriter(f, headers, delimiter=',', quoting=csv.QUOTE_MINIMAL)
f_csv.writeheader()
f_csv.writerows(rows)
if __name__ == '__main__':
writecsv3('students3.csv')
4.2 Dialect 对象
若干格式化参数可以组成Dialect对象,Dialect对象包含对应于命名格式化参数的属性。可以创建 Dialect或其派生类的对象,然后传递给reader或writer的构造函数。
下列 csv模块的函数可以创建Dialect对象
- csv.register_dialect(name[,dialect],**fmtparams):使用命名参数,注册一个名称
- csv.unregister_dialect(name):取消注册的名称。
- csv.get_dialect(name):获取注册的名称的Dialect对象,无注册时csv.Error
- csv.list_dialects():所有注册Dialect对象的列表。
另外可以使用csv模块函数,获取和设置字段的长度限制:csv.filed_size_limit([new_linit]
import csv
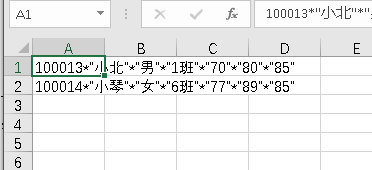
def writecsv4(csvfilepath):
csv.register_dialect('mydialect', delimiter='*', quoting=csv.QUOTE_ALL)
headers = ['学号', '姓名', '性别', '班级', '语文', '数学', '英语']
rows = [{'学号': '100013', '姓名': '小北', '性别': '男', '班级': '1班', '语文': '70', '数学': '80', '英语': '85'},
{'学号': '100014', '姓名': '小琴', '性别': '女', '班级': '6班', '语文': '77', '数学': '89', '英语': '85'}
]
with open(csvfilepath, 'a+', newline='') as f:
f_csv = csv.DictWriter(f, headers, dialect='mydialect')
f_csv.writerows(rows)
if __name__ == '__main__':
writecsv4('students4.csv')
结果: