python爬虫-----网络数据分析_正则表达式,xpath库,BeautifulSoup库
文章目录
- python爬虫-----网络数据分析
- 一、正则表达式
- 1.为什么要学正则表达式
- 2.什么是正则表达式
- 3.re 模块一般使用步骤
- Pattern 对象
- 正则表达式实现步骤
- 4.正则split和sub
- 5.常用的正则常量
- 项目案例:基于requests和正则 的猫眼电影TOP100定向爬虫
- 报错
- 二、xpath库
- 1.XPath如何实现文档解析?
- 2.xpath用法
- 项目案例:基于requerts和Xpath的猫眼电影TOP100定向爬虫
- 3.csv文件读写操作
- 项目案例:基于requerts和Xpath的TIOBE编程语言排行榜定向爬虫
- 三、BeautifulSoup库
- 1.bs4的基本用法
- 2.bs4的节点选择器
- 3.bs4的方法选择器
- 项目案例:基于requests和bs4的三国演义定向爬虫
python爬虫-----网络数据分析
一、正则表达式
1.为什么要学正则表达式
爬虫一共四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
2.什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。

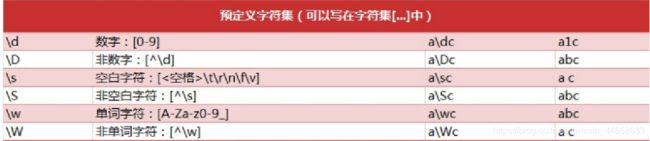
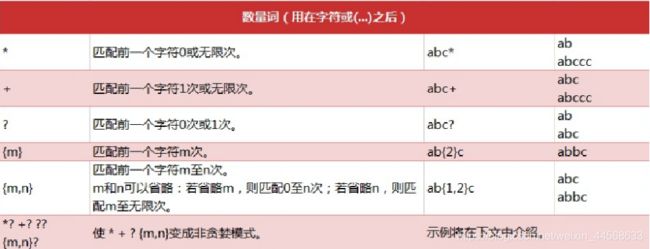





3.re 模块一般使用步骤
- 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象
注意: re对特殊字符进行转义,如果使用原始字符串,只需加一个 r 前缀 - 通过 Pattern 对象对文本进行匹配查找,获得匹配结果,一个 Match 对象。
- 使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
Pattern 对象
正则表达式编译成 Pattern 对象, 可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换

正则表达式实现步骤
import re
text = """
2020-10-10
2020-11-11
2030/12/12
"""
# 1. 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象
# 注意: re对特殊字符进行转义,如果使用原始字符串,只需加一个 r 前缀
pattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}') # 2020-4-11, 无分组的规则
pattern = re.compile(r'(\d{4})-(\d{1,2})-(\d{1,2})') # 2020-4-11, 有分组的规则
pattern = re.compile(r'(?P\d{4})-(?P\d{1,2})-(?P\d{1,2})' ) # 2020-4-11, 有命名分组的规则
# 2. 通过 Pattern 对象对文本进行匹配查找,获得匹配结果,一个 Match 对象。
# search从给定的字符串中寻找一个符合规则的字符串, 只返回一个
result = re.search(pattern, text)
print(result)
# 3. 使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
print("匹配到的信息:", result.group()) # 返回的是匹配到的文本信息
print("匹配到的信息:", result.groups()) # 返回的是位置分组, ('2020', '10', '10')
print("匹配到的信息:", result.groupdict()) # 返回的是关键字分组.{'year': '2020', 'month': '10', 'day': '10'}
#运行结果:
<re.Match object; span=(1, 11), match='2020-10-10'>
匹配到的信息: 2020-10-10
匹配到的信息: ('2020', '10', '10')
匹配到的信息: {'year': '2020', 'month': '10', 'day': '10'}
4.正则split和sub
repl 可以是字符串也可以是一个函数:
1). 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还 可以使用 id 的形式来引用分组,但不能使用编号 0;
2). 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符 串中不能再引用分组)。
count 用于指定最多替换次数,不指定时全部替换。
正则匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00- u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是 够用的。
import re
# ****************************split***************************
# text = '1+2*4+8-9/10'
# # 字符串方法: '172.25.254.250'.split('.') => ['172', '25', '254', '250']
# pattern = re.compile(r'\+|-|\*|/')
# # 将字符串根据+或者-或者*或者/进行切割.
# result = re.split(pattern, text)
# print(result) #['1', '2', '4', '8', '9', '10']
# #***********************sub**************************************
def repl_string(matchObj):
# matchObj方法: group, groups, groupdict
items = matchObj.groups()
# print("匹配到的分组内容: ", items) # ('2019', '10', '10')
return "-".join(items)
# 2019/10/10 ====> 2019-10-10
text = "2019/10/10 2020/12/12 2019-12-10 2020-11-10"
pattern = re.compile(r'(\d{4})/(\d{1,2})/(\d{1,2})') # 注意: 正则规则里面不要随意空格
# 将所有符合条件的信息替换成'2019-10-10'
# result = re.sub(pattern, '2019-10-10', text)
# 将所有符合条件的信息替换成'year-month-day'
result = re.sub(pattern, repl_string, text)
print(result) #2019-10-10 2020-12-12 2019-12-10 2020-11-10
5.常用的正则常量
正则表达式在线测试
https://c.runoob.com/front-end/854

"""
常用的正则常量:
"ASCII": 'A'
"IGNORECASE": 'I'
"MULTILINE":'M'
"DOTALL":'S'
"""
import re
# ******************************** 1. re.ASCII *****************************
text = "正则表达式re模块是python中的内置modelue."
# 匹配所有的\w+(字母数字下划线, 默认也匹配中文), 不想匹配中文时,指定flags=re.A
result = re.findall(r'\w+', string=text, flags=re.A)
print(result) #['re', 'python', 'modelue']
# ******************************** 2. re.IGNORECASE *****************************
text = 'hello world heLLo westos Hello python'
# 匹配所有he\w+o, 忽略大小写, re.I
result = re.findall(r'he\w+o', text, re.I)
print(result) # ['hello', 'heLLo', 'Hello']
# # ******************************** 3. re.S *****************************
text = 'hello \n world'
result = re.findall(r'^he.*?ld$', text, re.S)
print(result) #['hello \n world']
# # ************************匹配中文**********************
pattern = r'[\u4e00-\u9fa5]'
text = "正则表达式re模块是python中的内置modelue."
result = re.findall(pattern, text)
print(result) #['正', '则', '表', '达', '式', '模', '块', '是', '中', '的', '内', '置']
项目案例:基于requests和正则 的猫眼电影TOP100定向爬虫


import codecs
import json
import re
import time
import requests
from colorama import Fore
from fake_useragent import UserAgent
from requests import HTTPError
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
'Host': 'maoyan.com',
'Cookie': '__mta=244103482.1586583849431.1586591578863.1586591596622.7; uuid_n_v=v1; uuid=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; _csrf=911258e83ffafda305001ded783784bef80e9113d1d47c8f8b4940dc934b9acd; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1586583838; mojo-uuid=1bf14bca5d2a510f6e85c2857cc8d257; _lxsdk_cuid=17167c43f33c8-07022459d688ce-4313f6a-144000-17167c43f33c8; _lxsdk=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; mojo-session-id={"id":"83a8b6a56c45ba34bd30bd7e6d5c46b9","time":1586591446957}; __mta=244103482.1586583849431.1586583890672.1586591526586.6; mojo-trace-id=6; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1586591597; _lxsdk_s=171683837b1-2a5-86f-f4e%7C%7C10'
}
# 请求https协议的时候, 回遇到报错: SSLError
# verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败: %s' % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
return response.text
def parse_html(html):
"""
通过正则表达式对html解析获取电影名称、时间、评分、图片等信息。
:param html:
:return:
"""
pattern = re.compile(
''
+ '.*?(\d+)' # 获取电影的排名1
+ '.*?![(.*?)]() # 获取图片网址和图片名称
# 获取图片网址和图片名称![我和我的祖国]() + '.*?
+ '.*?(.*?)
' # 获取电影的主演: 主演:黄渤,张译,韩昊霖
+ '.*?(.*?)
' # 获取电影的上映时间: 上映时间:2019-09-30
'.*?',
re.S
)
# findall返回列表, finditer返回的是迭代器
items = re.finditer(pattern, html)
for item in items:
yield {
'index': item.groups()[0],
'image': item.groups()[1],
'title': item.groups()[2],
'star': item.groups()[3].strip().lstrip('主演:'),
'releasetime': item.groups()[4].lstrip('上映时间:')
}
def save_to_json(data, filename):
"""将爬取的数据信息写入json文件中"""
# r, r+, w, w+, a, a+
# 解决的问题:
# 1. python数据类型如何存储到文件中? json将python数据类型序列化为json字符串
# 2. json中中文不能存储如何解决? ensure_ascii=False
# 3. 存储到文件中的数据不是utf-8格式的,怎么解决? ''.encode('utf-8')
# with open(filename, 'ab') as f:
# f.write(json.dumps(data, ensure_ascii=False,indent=4).encode('utf-8'))
# print(Fore.GREEN + '[+] 保存电影 %s 的信息成功' %(data['title']))
with codecs.open(filename, 'a', 'utf-8') as f:
# f.write(json.dumps(data, ensure_ascii=False) + '\n')
f.write(json.dumps(data, ensure_ascii=False, indent=4))
print(Fore.GREEN + '[+] 保存电影 %s 的信息成功' % (data['title']))
def get_one_page(page=1):
# url = 'https://maoyan.com/board/' # 采集热映口碑榜, 只有一页。
# 采集电影TOP100, 总共10页. url的规则: https://maoyan.com/board/4?offset=(page-1)*10
url = 'https://maoyan.com/board/4?offset=%s' % ((page - 1) * 10)
html = download_page(url)
# print(html)
items = parse_html(html)
# item是字典
for item in items:
save_to_json(item, 'maoyan.json')
def no_use_thread():
for page in range(1, 11):
get_one_page(page)
print(Fore.GREEN + '[+] 采集第[%s]页数据' % (page))
# 反爬虫策略: 方式爬虫速度太快被限速, 在采集数据的过程中,休眠一段时间
time.sleep(0.5)
def use_multi_thread():
# 使用多线程实现的代码
from threading import Thread
for page in range(1, 11):
thread = Thread(target=get_one_page, args=(page,)) #给每一页分配一个线程
thread.start()
print(Fore.GREEN + '[+] 采集第[%s]页数据' % (page))
def use_thread_pool():
from concurrent.futures import ThreadPoolExecutor
# 实例化线程池并指定线程池线程个数
pool = ThreadPoolExecutor(100)
pool.map(get_one_page, range(1, 11))
print("采集结束")
if __name__ == '__main__':
no_use_thread()
#运行结果 ,这里因为反爬原因,部分数据为能爬取
F:\python\Anaconda3\python.exe F:/ziliao/python_kaifa/my_code/13_Spider/SpiderProject/10_基于requests和正则的猫眼电影TOP100定向爬虫(1).py
F:\python\Anaconda3\lib\site-packages\urllib3\connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
[+] 保存电影 霸王别姬 的信息成功
[+] 保存电影 肖申克的救赎 的信息成功
[+] 保存电影 这个杀手不太冷 的信息成功
[+] 保存电影 罗马假日 的信息成功
[+] 保存电影 泰坦尼克号 的信息成功
[+] 保存电影 乱世佳人 的信息成功
[+] 保存电影 唐伯虎点秋香 的信息成功
[+] 保存电影 魂断蓝桥 的信息成功
[+] 保存电影 辛德勒的名单 的信息成功
[+] 保存电影 喜剧之王 的信息成功
[+] 采集第[1]页数据
F:\python\Anaconda3\lib\site-packages\urllib3\connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
[+] 保存电影 天空之城 的信息成功
[+] 保存电影 大闹天宫 的信息成功
[+] 保存电影 春光乍泄 的信息成功
[+] 保存电影 音乐之声 的信息成功
[+] 保存电影 剪刀手爱德华 的信息成功
[+] 保存电影 黑客帝国 的信息成功
[+] 保存电影 指环王3:王者无敌 的信息成功
[+] 保存电影 加勒比海盗 的信息成功
[+] 保存电影 教父2 的信息成功
[+] 保存电影 楚门的世界 的信息成功
[+] 采集第[2]页数据
F:\python\Anaconda3\lib\site-packages\urllib3\connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
[+] 保存电影 无间道 的信息成功
[+] 保存电影 蝙蝠侠:黑暗骑士 的信息成功
[+] 保存电影 射雕英雄传之东成西就 的信息成功
[+] 保存电影 指环王1:护戒使者 的信息成功
[+] 保存电影 天堂电影院 的信息成功
[+] 保存电影 指环王2:双塔奇兵 的信息成功
[+] 保存电影 机器人总动员 的信息成功
[+] 保存电影 活着 的信息成功
[+] 保存电影 狮子王 的信息成功
[+] 保存电影 拯救大兵瑞恩 的信息成功
[+] 采集第[3]页数据
。。。。。。
报错
1.报错:requests.exceptions.SSLError: HTTPSConnectionPool(host=‘verify.meituan.com’, port=443): Max retries exceeded with url: /v2/web/general_page?action
原因及解决:当使用https请求时,可能会遇到SSLError的报错,这是证书有问题,简单的觉得方法就是获取url的时候,设置verify=False。
response = requests.get(url, params=parmas, headers=headers,verify=False)
2.反爬策略
(1)在头部加上Host和Cookie信息
cookie 位置:右击 审查元素–>网络–>Headers
headers = {
'User-Agent': ua.random,
'Host': 'maoyan.com',
'Cookie': '__mta=244103482.1586583849431.1586591578863.1586591596622.7; uuid_n_v=v1; uuid=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; _csrf=911258e83ffafda305001ded783784bef80e9113d1d47c8f8b4940dc934b9acd; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1586583838; mojo-uuid=1bf14bca5d2a510f6e85c2857cc8d257; _lxsdk_cuid=17167c43f33c8-07022459d688ce-4313f6a-144000-17167c43f33c8; _lxsdk=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; mojo-session-id={"id":"83a8b6a56c45ba34bd30bd7e6d5c46b9","time":1586591446957}; __mta=244103482.1586583849431.1586583890672.1586591526586.6; mojo-trace-id=6; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1586591597; _lxsdk_s=171683837b1-2a5-86f-f4e%7C%7C10'}
}
(2)加休眠
# 反爬虫策略: 方式爬虫速度太快被限速, 在采集数据的过程中,休眠一段时间
time.sleep(0.5)
二、xpath库
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
XPath (XML Path Language) 是一门在 xml文档中查找信息的语言,可用来在 xml /html文档中对元素和属性进行遍历。
查询更多XPath的用法: https://www.w3school.com.cn/xpath/xpath_syntax.asp
1.XPath如何实现文档解析?
- etree库把HTML文档中的字符串解析为Element对象
from lxml import etree
html=etree.HTML(text)
result=etree.tostring(html) - etree库把HTML文档解析为Element对象
html=etree.parse(‘xxx.html’)
result=etree.tostring(html,pretty_print=True)
2.xpath用法
- 获取子节点与属性匹配
//li、 //li/a、//a[@href=“xxx”]/…/@class、//li[@class=“item-1”]
//li[contains(@class,“aaa”)]/a/text() - 文本获取
//li[@class=“item-1”]/a/text()、//li[@class=“item-1”]//text() - 属性获取
//li/a/@href、//li//@href
项目案例:基于requerts和Xpath的猫眼电影TOP100定向爬虫

import codecs
import json
import requests
from colorama import Fore
from fake_useragent import UserAgent
from requests import HTTPError
from lxml import etree
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
'Host': 'maoyan.com',
'Cookie': '__mta=244103482.1586583849431.1586591578863.1586591596622.7; uuid_n_v=v1; uuid=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; _csrf=911258e83ffafda305001ded783784bef80e9113d1d47c8f8b4940dc934b9acd; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1586583838; mojo-uuid=1bf14bca5d2a510f6e85c2857cc8d257; _lxsdk_cuid=17167c43f33c8-07022459d688ce-4313f6a-144000-17167c43f33c8; _lxsdk=70A8E5507BB711EA904101D407E7401D56771E011B5248CCB28F41E623827FA2; mojo-session-id={"id":"83a8b6a56c45ba34bd30bd7e6d5c46b9","time":1586591446957}; __mta=244103482.1586583849431.1586583890672.1586591526586.6; mojo-trace-id=6; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1586591597; _lxsdk_s=171683837b1-2a5-86f-f4e%7C%7C10'
}
# 请求https协议的时候, 回遇到报错: SSLError
# verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败: %s' % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
return response.text
def parse_html(html):
"""
通过Xpath对html解析获取电影名称、时间、评分、图片等信息。
:param html:
:return:
"""
# 通过lxml对文档进行解析
# 1). 将传入的html文档内容通过lxml解析器进行解析,lxml中有个etree库把HTML文档中的字符串解析为Element对象
html = etree.HTML(html)
# 2). 通过Xpath语法获取电影的信息
# //dl[@class="board-wrapper"]/dd, 从当前节点寻找class属性名等于board-wrapper的dl标签, 拿出里面的所有dd标签
movies = html.xpath('//dl[@class="board-wrapper"]/dd')
for movie in movies:
# 从当前dd节点寻找i标签里面的文本内容
index = movie.xpath('./i/text()')[0]
# .//从当前标签寻找img标签(class='border-img'), 获取标签的data-src和alt属性
# /不深入寻找, // 深入寻找
image = movie.xpath('./a/img[@class="board-img"]/@data-src')[0]
title = movie.xpath('./a/img[@class="board-img"]/@alt')[0]
star = movie.xpath('.//p[@class="star"]/text()')[0]
releasetime = movie.xpath('.//p[@class="releasetime"]/text()')[0]
yield {
'index': index,
'image': image,
'title': title,
'star': star.strip().lstrip('主演:'),
'releasetime': releasetime.lstrip('上映时间:')
}
def save_to_json(data, filename):
"""将爬取的数据信息写入json文件中"""
# r, r+, w, w+, a, a+
# 解决的问题:
# 1. python数据类型如何存储到文件中? json将python数据类型序列化为json字符串
# 2. json中中文不能存储如何解决? ensure_ascii=False
# 3. 存储到文件中的数据不是utf-8格式的,怎么解决? ''.encode('utf-8')
# with open(filename, 'ab') as f:
# f.write(json.dumps(data, ensure_ascii=False,indent=4).encode('utf-8'))
# print(Fore.GREEN + '[+] 保存电影 %s 的信息成功' %(data['title']))
with codecs.open(filename, 'a', 'utf-8') as f:
# f.write(json.dumps(data, ensure_ascii=False) + '\n')
f.write(json.dumps(data, ensure_ascii=False, indent=4))
print(Fore.GREEN + '[+] 保存电影 %s 的信息成功' % (data['title']))
def get_one_page(page=1):
url = 'https://maoyan.com/board/' # 采集热映口碑榜, 只有一页。
html = download_page(url)
# print(html)
items = parse_html(html)
# item是字典
for item in items:
save_to_json(item, 'maoyan.json')
if __name__ == '__main__':
get_one_page()
运行结果:

3.csv文件读写操作
"""
逗号分隔值(Comma-Separated Values,CSV)以纯文本形式存储表格数据(数字和文本)。
csv文件读取有两种方法: reader()和DictReader()
csv文件的写入有两种方法: writer()和DictWriter()
"""
import csv
# 1). 通过reader方式读取文件内容,每行的内容是一个列表
# with open('hello.csv') as f:
# csv_reader = csv.reader(f)
# for row in csv_reader:
# # ['fentiao', '10']
# print(row)
# # 2). 通过Dictreader方式读取文件内容,每行的内容是一个字典
# with open('hello.csv') as f:
# csv_reader = csv.DictReader(f)
# for row in csv_reader:
# # OrderedDict([('name', 'xiaoli'), ('age', '20')])
# print(row)
# print("名称: ", row['name'])
# print("年龄: ", row['age'])
# # 3). 通过writer方式写入文件, 传入一个列表
# info = [
# ('fentiao', 10),
# ('fensi', 9)
# ]
# with open('writer.csv', 'w', encoding='utf-8') as f:
# csv_writer = csv.writer(f)
# # 一次写入多行内容
# csv_writer.writerows(info)
#
# # for循环,每次写入一行内容
# # for row in info:
# # csv_writer.writerow(row)
# 4). 通过DictWriter方式写入文件, 传入一个字典
data = [
{'name':'name1', 'password':'password1'},
{'name':'name2', 'password':'password2'},
{'name':'name3', 'password':'password3'},
]
with open('writer.csv', 'w', encoding='utf-8') as f:
# ['name', 'password']是csv文件的表头
csv_writer = csv.DictWriter(f, ['name', 'password'])
# 依次遍历列表中的每一个字典并写入文件
for row in data:
csv_writer.writerow(row)
项目案例:基于requerts和Xpath的TIOBE编程语言排行榜定向爬虫
import csv
import requests
from colorama import Fore
from fake_useragent import UserAgent
from lxml import etree
from requests import HTTPError
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
# 请求https协议的时候, 回遇到报错: SSLError
# verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败: %s' % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
return response.text
def parse_html(html):
"""
编程语言的去年名次、今年名次、编程语言名称、评级Rating和变化率Change等信息。
:param html:
:return:
"""
# 1). 通过lxml解析器解析页面信息, 返回Element对象
html = etree.HTML(html)
# 2). 根据Xpath路径寻找语法获取编程语言相关信息
# 获取每一个编程语言的Element对象
#
languages = html.xpath('//table[@id="top20"]/tbody/tr')
# 依次获取每个语言的去年名次、今年名次、编程语言名称、评级Rating和变化率Change等信息。
for language in languages:
# 注意: Xpath里面进行索引时,从1开始
now_rank = language.xpath('./td[1]/text()')[0]
last_rank = language.xpath('./td[2]/text()')[0]
name = language.xpath('./td[4]/text()')[0]
rating = language.xpath('./td[5]/text()')[0]
change = language.xpath('./td[6]/text()')[0]
yield {
'now_rank': now_rank,
'last_rank': last_rank,
'name': name,
'rating': rating,
'change': change
}
def save_to_csv(data, filename):
# 1). data是yield返回的字典对象
# 2). 以追加的方式打开文件并写入
# 3). 文件的编码格式是utf-8
# 4). 默认csv文件写入会有空行, newline=''
with open(filename, 'a', encoding='utf-8', newline='') as f:
csv_writer = csv.DictWriter(f, ['now_rank', 'last_rank', 'name', 'rating', 'change'])
# 写入csv文件的表头
# csv_writer.writeheader()
csv_writer.writerow(data)
def get_one_page(page=1):
url = 'https://www.tiobe.com/tiobe-index/'
filename = 'tiobe.csv'
html = download_page(url)
items = parse_html(html)
for item in items:
save_to_csv(item, filename)
print(Fore.GREEN + '[+] 写入文件%s成功' %(filename))
if __name__ == '__main__':
get_one_page()

三、BeautifulSoup库
Beautiful Soup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。Beautiful Soup在解析时实际上依赖解析器, 可以选择的解析器如下表所示:

1.bs4的基本用法
# 1. 从bs4模块中导入BeautifulSoup类
from bs4 import BeautifulSoup
# 2. 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
html = """
BS4
"""
soup = BeautifulSoup(html, 'lxml')
# 3. 把要解析的字符串以标准的缩进格式输出
string = soup.prettify()
print(string)
2.bs4的节点选择器

html = """
beautifulsoup
姓名
年龄
张三
10
李四
20
 """
# 1. 从bs4模块中导入BeautifulSoup类
from bs4 import BeautifulSoup
# 2. 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 3. 节点选择器
# 3-1). 元素选择: 只返回在html里面查询符合条件的第一个标签内容
# print(soup.title)
# print(soup.img)
# print(soup.tr) #只返回第一个tr标签
# 3-2). 嵌套选择器
# print(soup.html.head.title) #打印出title的标签
# print(soup.body.table.tr.td)
# 3-3). 属性选择
# # 3-3-1). 获取标签名称: 当爬虫过程中, 标签对象赋值给一个变量传递进函数时, 想获取变量对应的标签, name属性就很有用。
# print(soup.img.name)
# movieimg = soup.img
# print(movieimg.name)
# # 3-3-2). 获取标签的属性
# print(soup.table.attrs) # 返回标签所有的属性信息{'class': ['table'], 'id': 'userinfo'}
# print(soup.table.attrs['class']) # 获取class属性对应的值
# print(soup.table['class']) # 获取class属性对应的值推荐版
# print(soup.table['id']) # 获取id属性对应的值推荐版
# # 3-3-3). 获取文本内容
# print(soup.title.string)
# print(soup.title.get_text())
# 3-4). 关联选择
# 3-4-1). 父节点和祖父节点
# first_tr_tags = soup.table.tr
# print(first_tr_tags.parent) # 父节点
# parents = first_tr_tags.parents # 祖父节点generator object PageElement.parents
# for parent in parents:
# print("*******************") # tr标签的父标签是table, table的父标签是body, body父标签是html
# print(parent)
#
# # 3-4-2). 子节点和子孙节点
# table_tag = soup.table
# for children in table_tag.children:
# print('**********')
# print(children)
#
# 3-4-3). 兄弟节点
# tr_tag = soup.table.tr
# print(tr_tag)
# print(tr_tag.next_sibling)
"""
# 1. 从bs4模块中导入BeautifulSoup类
from bs4 import BeautifulSoup
# 2. 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 3. 节点选择器
# 3-1). 元素选择: 只返回在html里面查询符合条件的第一个标签内容
# print(soup.title)
# print(soup.img)
# print(soup.tr) #只返回第一个tr标签
# 3-2). 嵌套选择器
# print(soup.html.head.title) #打印出title的标签
# print(soup.body.table.tr.td)
# 3-3). 属性选择
# # 3-3-1). 获取标签名称: 当爬虫过程中, 标签对象赋值给一个变量传递进函数时, 想获取变量对应的标签, name属性就很有用。
# print(soup.img.name)
# movieimg = soup.img
# print(movieimg.name)
# # 3-3-2). 获取标签的属性
# print(soup.table.attrs) # 返回标签所有的属性信息{'class': ['table'], 'id': 'userinfo'}
# print(soup.table.attrs['class']) # 获取class属性对应的值
# print(soup.table['class']) # 获取class属性对应的值推荐版
# print(soup.table['id']) # 获取id属性对应的值推荐版
# # 3-3-3). 获取文本内容
# print(soup.title.string)
# print(soup.title.get_text())
# 3-4). 关联选择
# 3-4-1). 父节点和祖父节点
# first_tr_tags = soup.table.tr
# print(first_tr_tags.parent) # 父节点
# parents = first_tr_tags.parents # 祖父节点generator object PageElement.parents
# for parent in parents:
# print("*******************") # tr标签的父标签是table, table的父标签是body, body父标签是html
# print(parent)
#
# # 3-4-2). 子节点和子孙节点
# table_tag = soup.table
# for children in table_tag.children:
# print('**********')
# print(children)
#
# 3-4-3). 兄弟节点
# tr_tag = soup.table.tr
# print(tr_tag)
# print(tr_tag.next_sibling)
3.bs4的方法选择器
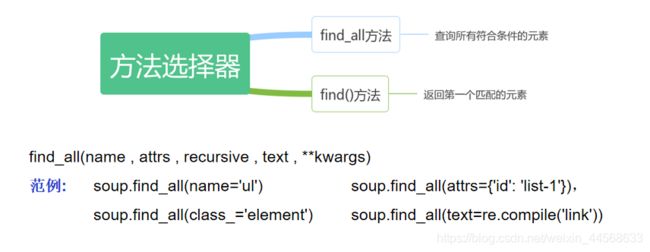
"""
- findall
- find
"""
import re
html = """
beautifulsoup
姓名
年龄
张三
10
李四
20
"""
# 1. 从bs4模块中导入BeautifulSoup类
from bs4 import BeautifulSoup
# 2. 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 3. 使用方法选择器灵活的查找标签元素
# # 3-1). 根据标签名进行寻找
# print(soup.find_all('title'))
# print(soup.find('title').string)
# 3-2). 根据标签名和属性信息attrs进行寻找
# print(soup.find_all('table', attrs={'class':'table', 'id':'userinfo'}))
# print(soup.find('table', attrs={'class':'table', 'id':'userinfo'}))
# print(soup.find('table', attrs={'class':'table', 'id':'userinfo'}, recursive=True))
# 3-3). 根据标签名和属性信息class_='xxx', id='xxx'进行寻找
# print(soup.find_all('table', id='userinfo'))
# print(soup.find_all('table', class_='table'))
# # ******规则可以和正则表达式结合
# print(soup.find_all('tr', class_=re.compile('item-\d+')))
# print(soup.find_all('tr', class_=re.compile('item-\d+'), limit=2))
# 3-4). 根据标签的文本信息进行寻找
# 需求: 将td标签中文本信息是一位数字或者两位数字的值拿出来
# print(soup.find_all('td', text=re.compile(r'\d{1,2}')))
项目案例:基于requests和bs4的三国演义定向爬虫
思路分析:
- 根据网址http://www.shicimingju.com/book/sanguoyanyi.html获取三国演义主页的章节信息.
- 分析章节信息的特点, 提取章节的详情页链接和章节的名称。
- ,li的详情信息如下:
- 第一回·宴桃园豪杰三结义 斩黄巾英雄首立功
- 根据章节的详情页链接访问章节内容
- 提取到的章节内容包含特殊的标签, eg:
==> '\n' ,
=> ''
- 将章节信息存储到文件中
import csv
import os
import re
import requests
from colorama import Fore
from fake_useragent import UserAgent
from lxml import etree
from requests import HTTPError
from bs4 import BeautifulSoup
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
# 请求https协议的时候, 回遇到报错: SSLError
# verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败: %s' % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
return response.text
def parse_html(html):
# 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 根据bs4的选择器获取章节的详情页链接和章节的名称
book = soup.find('div', class_='book-mulu') # 获取该书籍对象
chapters = book.find_all('li') # 获取该数据的所有章节对应的li标签, 返回的是列表
# 依次遍历每一个章节的内容
for chapter in chapters:
detail_url = chapter.a['href']
chapter_name = chapter.a.string
#这里返回一个生成器,不是把找到的章节一次性以列表方式返回(占用内存),而是返回生成器,需要的时候一边生成一边进一步处理
yield {
'detail_url': detail_url,
'chapter_name': chapter_name
}
def parse_detail_html(html):
# 实例化BeautifulSoup对象, 并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 根据章节的详情页链接访问章节内容, string只拿出当前标签的文本信息, get_text返回当前标签和子孙标签的所有文本信息
#
chapter_content = soup.find('div', class_='chapter_content').get_text()
return chapter_content.replace(' ', '')
def get_one_page():
base_url = 'http://www.shicimingju.com'
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
dirname = "三国演义"
if not os.path.exists(dirname):
os.mkdir(dirname)
print(Fore.GREEN + "创建书籍目录%s成功" %(dirname))
html = download_page(url)
items = parse_html(html)
for item in items:
# 访问详情页链接
detail_url = base_url + item['detail_url']
# 生成文件存储的路径: 三国演义/第一回.xxxxx.txt
chapter_name = os.path.join(dirname, item['chapter_name'] + '.txt')
chapter_html = download_page(detail_url)
chapter_content = parse_detail_html(chapter_html)
# 写入文件
with open(chapter_name, 'w', encoding='utf-8') as f:
f.write(chapter_content)
print(Fore.GREEN + "写入文件%s成功" %(chapter_name))
if __name__ == '__main__':
get_one_page()

你可能感兴趣的:(python爬虫-----网络数据分析_正则表达式,xpath库,BeautifulSoup库)