DevoFlow
文章目录
- 实验设计
- Mechanism
- devolving control
- statistic collection
- 专业术语解释
- TCAM
- 交换
- 交换机转发方式
- 存储转发交换
- 无碎片方式
- 交换机域
- 冲突域
- 广播域
- Elephant flow
- ECMP 等价多路径
- CDN 架构
- 负载均衡架构
- 负载均衡算法
- Pull
- Statistical Multiplexing
- Statistical Multiplexing Gain 多路复用增益
- Oversubscription 和 undersubscription
- 影响理解的生词
- 未能理解的部分
- 一些额外的知识补充
- NetFlow中的流
- sFlow协议
- 1.1、sFlow组成要点
- 1.2、sFlow报文理解
- 1.3、sFlow采样要点
- 1.3.1 、Flow采样
- 1.3.2 、Counter采样
- 1.3.3、Flow采样与Counter采样的区别与联系
- 2、 总结一些sFlow的特色
- LAG
- NIC
- oblivious routing
- clos topology
- HyperX topology
- MAP reduce
- Energy-aware routing
- STP spanning tree protocol
- Valiant Load-Balancing
- inter-rack
DevoFlow对Openflow的优化
Openflow的标准到现在为止已经发展到了V1.4,但是离能够大规模商用部署仍有相当距离,因为它仍有一些关键问题无法解决
1)根据openflow的spec,必须使用TCAM来支持flow,flow数量巨大,所以导致TCAM必须也很大。芯片中的TCAM可是个奢侈品,占用面积大,一条TCAM entry基本上相当于5条DRAM entry的面积,且功耗也很大。这样导致整个交换机系统硬件成本和功耗都居高不下,无论是内置还是外挂。
2)每条flow都需要有一个counter,每条flow都要有一个timer,这些counter和timer都需要centralized controller来统一管理,当flow数量变大的时候,对这些counter, timer的管理开销(controller跟switch之间的通信开销,switch和controller自身的计算开销)非常巨大,scalability是个大问题
3)每条flow的创建都需要controller的参与,而且是switch跟controller之间一来一回,不仅带来额外的通信开销,而且导致flow的install有延迟,影响报文转发。
4)实际的数据中心网络里面,影响网络拥塞的可能就是10%的flow,这些flow贡献了90%的流量。所以,网络中花了那么多代价对另外90%的flow去管理,优化,性价比太低,等于是浪费了,再怎么去load balance,对网络产生的影响也很有限。而去优化那10%的significant flow,则是有价值的。
正是基于对以上的openflow中的问题的认识,Waterloo大学的研究人员发表了一个paper,介绍了一个叫DevoFlow (Devolve Flow)的机制,来优化openflow. 这个机制基于的前提假设条件就是实际的数据中心网络里面,10%的flow贡献了90%的流量,重点需要来管理优化这部分flow,对于其它flow,用最简单的load balance方式去处理就行了,管它呢。
这个机制的总体工作原理大概可以分为三部分
1)检测这些10%的flow, 这些flow称之为elephant flow(相对于其它的mice flow) multipath wildcards rules避免和controller交互,然后用数据收集手段上报controller
2) 抽取标志性的字段,来install exact match的flow entry (使用hash) The controller finds the least congested path between the flow’s endpoints, and re-routes the flow by inserting table entries for the flow at switches on this path
3) 对这些elephant flow进行管理,如路径优化
uses only edge switches to encapsulate new flows to send to the central
controller. The controller programs core and aggregation switches reactively to flow setups from the edge
switches. Therefore, the only overhead imposed is cost of
installing flow table entries at the the core and aggregation
switches—no overheads are imposed for statistics-gathering.
大概的工作原理如下。
1)先install少量TCAM entry,来标志一些aggregated flow (比如具有相同的destination IP,或者相同的source IP等)。
然后对这些flow进行监控。 有几种机制,最简单的是定期看它的statistics,如果在一段时间内超过了某个threshold,
就从报文中提取出关键字段,加到hash表里面去。或者对这条aggregated flow进行采样分析,一旦超过了threshold,
就从报文中提取出关键字段,加到hash 表里面去。而更有效地我觉得还是使用他们所谓的approximate counter,
这只是一个概念,具体到实现,可以才用bloom filter算法(paper中并没有提),这个算法可以用很小的误差率来检测一条elephant flow,
而前面两个则都不能做到。
但是无论哪种做法,最后都将标志性字段提取出来(比如IPSA+IPDA+protocol+L4dest port + l4 source port),然后install到hash table.
在芯片里面查表的时候看,会同时查hash table和tcam table,hash table结果优先。
2)install elephant flow到hash table的时候,可以选择一条流量最轻的路径给它。
3)这些elephant flow还可以被老化
4)对于非elephant flow,直接使用传统的ECMP,根据hash结果去选择一条路径,不管是heavy utilization or light utilization.
5) elephant flow也可以不指定一条固定的路径,而是使用multiple path,但是选路的时候,是要使用**DLB (dynamic load balance)**机制,动态的选择流量最低的路径。 当然DLB的机制就算不使用DevoFlow, 普通的openflow也可以用。所以这个不属于DevoFlow的发明创造。
DevoFlow需要芯片的强有力的支持。
核心想法在于不重要的流直接用通配规则
负载均衡不需要控制器知道每条流的建立
实验设计
implementing OpenFlow on the HP
ProCurve 5406zl [1] switch, which uses an ASIC on each
multi-port line card, and also has a CPU for management
functions
To estimate the flow setup rate of the ProCurve 5406zl, we
attached two servers to the switch and opened the next connection from one server to the other as soon as the previous
connection was established.
We measured how long it took to read statistics from the
5406zl as we varied the number of flow table entries. The results are shown in Figure 1. For this experiment (and all others in this section), we attached three servers to the switch:
two servers were clients (A and B) and one was the OpenFlow controller. To get measurements with no other load on
the switch, we configured the switch so that its flow table
entries never expired. Then, both clients opened ten connections to each other. The controller waited 5 sec. to ensure
that the switch was idle, and then pulled the statistics from
the switch. This process was repeated until the flow table
contained just over 32K entries
Mechanism
devolving control
交换机预先设定多个方案,或学习通配,使得控制器少做一点
Rule Cloning: 聚合太多会导致在出去的时候不知道往哪走,因此引出Rule Cloning,把通配的地方自动匹配微流 If the flag is clear, the switch follows the standard wildcard behavior. Otherwise, the switch locally “clones” the wildcard rule to create a new rule in which all of the wildcarded fields are replaced by values matching this microflow, and all other aspects of the original rule are inherited.
Local actions: 提供一些本地可选的actions,如果都不能用,那么再上报controller,如multiple support和rapid re-routing.
- multiple support:给通配的规则不止一个出口,根据概率分布选端口
we envision rules augmented with a small set of possible “local routing actions” that a switch can take without paying
the costs of invoking the controller. If a switch does not support an action, it defaults to invoking the controller, so as
to preserve the desired semantics. - rapid rerouting: 出故障的备选路径
statistic collection
专业术语解释
TCAM
TCAM (ternary content addressable memory)是一种三态内容寻址存储器,主要用于快速查找ACL、路由等表项。
它是从CAM的基础上发展而来的。一般的CAM存储器中每个bit位的状态只有两个,“0”或“1”,而TCAM中每个bit位有三种状态,除掉“0”和“1”外,还有一个“don’t care”状态,所以称为“三态”,它是通过掩码来实现的,正是TCAM的这个第三种状态特征使其既能进行精确匹配查找,又能进行模糊匹配查找,而CAM没有第三种状态,所以只能进行精确匹配查找。
特点:条目并行访问,二进制关键字匹配(这两条性质使得无论表内有多少条目,性能都不会减弱),
交换
在计算机网络和通讯中,分组交换(英语:Packet switching)是一种相对于电路交换的通信范例,分组(又称消息、或消息碎片)在节点间单独路由,不需要在传输前先建立通信路径。
分组是由一块用户数据和必要的地址和管理信息组成,保证网络能够将数据传递到目标。类似于从邮局发送的包裹上注明的地址一样,只有提供给网络这些信息,网络(邮局)才能把分组(包裹)往正确的地址传送。
分组通过最佳路径(取决于 路由算法)路由到目标。但并不是所有在相同两个主机之间传送的分组(即使是来自同一消息的那些分组)一定要沿着相同的路径传送。
在分组交换中,一个系统可以将数据组装到报文中使用一条通信链路与多台机器通信。不仅链路是可以共享的,而且每个报文可以独立于其他报文进行路由。这是分组交换最主要的优势。
交换机转发方式
存储转发交换
差错控制:
使用存储转发技术的交换机对进入帧进行差错控制。在进入端口接收完整一帧之后,交换机将数据报最后一个字段的帧校验序列(frame check sequence, FCS)与自己的FCS进行比较。FCS校验过程用以帮助确保帧没有物理及数据链路错误,如果该帧校验正确,则交换机转发。否则,丢弃。
自动缓存:
存储转发交换机通过进入端口缓存,支持不同速率以太网的混合连接。例如,接收到一个以1Gb/s速率发出的帧,转发至百兆以太网端口,就需要使用存储转发方式。当进入与输出端口速率不匹配时,交换机将整帧内容放入缓存中,计算FCS校验,转发至输出缓存之后将帧发出。
Cisco的主要交换方式是存储转发交换。
无碎片方式
交换机域
冲突域
设备间共享同一网段称为冲突域。因为该网段内两个以上设备同时尝试通讯时,可能发生冲突。使用工作在数据链路层的交换机可将各个网段的冲突域隔离,并减少竞争带宽的设备数量。交换机的每一个端口就是一个新的网段,因为插入端口的设备之间无需竞争。结果是每一个端口都代表一个新的冲突域。网段上的设备可以使用更多带宽,冲突域内的冲突不会影响到其他网段,这也成为微网段。
广播域
尽管交换机按照MAC地址过滤大多数帧,它们并不能过滤广播帧。LAN上的交换机接收到广播包后,必须对所有端口泛洪。互连的交换机集合形成了一个广播域。网络层设备如路由器,可隔离二层广播域。路由器可同时隔离冲突和广播域。
当设备发出二层广播包,帧中的目的MAC地址被设置为全二进制数,广播域中的所有设备都会接收到该帧。二层广播域也称为MAC广播域。MAC广播域包含LAN上所有接收到广播帧的设备。广播通信比较多时,可能会带来广播风暴。特别是在包含不同速率的网段,高速网段产生的广播流量可能导致低速网段严重拥挤,乃至崩溃。
Elephant flow
在实际数据中心网络中,导致网络拥塞的流量可能指只占10%,而这些流量占总流量大小的90%,被称为大象流(Elephant Flow),其余流量被称为老鼠流(Mice Flow)。DeveFlow通过定期的采样统计流量,检测大象流并对其进行标记,之后集中对这些流量采用动态负载均衡,多路径等流量工程技术进行优化。
most(e.g.80%) of the traffic is actually carried by only a small number of connections(elephants), while the remaining large amount of connections are very small in size or lifetime(mice).
ECMP 等价多路径
数据中心内负载均衡-ECMP的使用分析井丽南 • 18-03-14
ECMP是一个逐跳的基于流的负载均衡策略,当路由器发现同一目的地址出现多个最优路径时,会更新路由表,为此目的地址添加多条规则,对应于多个下一跳。可同时利用这些路径转发数据,增加带宽。ECMP算法被多种路由协议支持,例如:OSPF、ISIS、EIGRP、BGP等。在数据中心架构VL2中也提到使用ECMP作为负载均衡算法。
CDN 架构
CDN与Load Balance
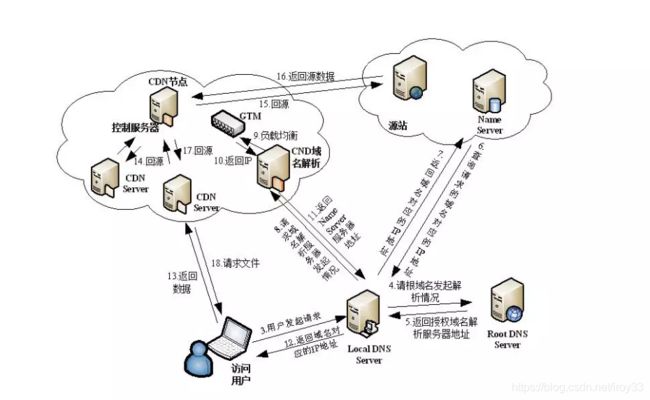
如图所示,以用户访问某个静态文件(如CSS),域名为cdn.taobao.com,首先向LDNS请求,经过迭代解析后回到Name Server解析,一般每个公司都会有一个DNS解析服务器,这个DNS解析服务器通常会把它重新CNAME解析到另一个域名,这个域名最终会被指向CDN全局中的DNS负载均衡服务器,再由这个GTM来最终分配是哪个地方的访问用户,返回给离此访问用户最近的CDN节点,若在此节点找不到文件,将回到源站去获取
负载均衡架构
负载均衡算法
-
轮询策略
实际应用中,轮询也会有多种方式,有按顺序轮询的、有随机轮询的、还有按照权重来轮询的。前两种比较好理解,第三种按照权重来轮询,是指给每台后端服务设定一个权重值,比如性能高的服务器权重高一些,性能低的服务器给的权重低一些,这样设置的话,分配流量的时候,给权重高的更多流量,可以充分的发挥出后端机器的性能。- 动态负载均衡
Nginx动态负载均衡
动态负载均衡策略类似于加权轮询策略,可以通过对于后端服务器集群的状态监测,量化不同服务器的性能差异,来周期性调整服务器的比重来实现权重的动态调整。
- 动态负载均衡
-
负载度策略
负载度策略是指当「负载均衡器」往后端转发流量的时候,会先去评估后端每台服务器的负载压力情况,对于压力比较大的后端服务器转发的请求就少一些,对于压力比较小的后端服务器可以多转发一些请求给它。
这种方式也带来了一些弊端,因为需要动态的评估后端服务器的负载压力,那这个「负载均衡器」除了转发请求以外,还要做很多额外的工作,比如采集 连接数、请求数、CPU负载指标、IO负载指标等等,通过对这些指标进行计算和对比,判断出哪一台后端服务器的负载压力较大。
- 响应策略
响应策略是指,当用户请求过来的时候,「负载均衡器」会优先将请求转发给当前时刻响应最快的后端服务器(不管服务器负载度、配置) - 哈希策略
将请求中的某个信息进行hash计算,然后根据后端服务器台数取模,得到一个值,算出相同值的请求就被转发到同一台后端服务器中。
常见的用法是对用户的IP或者ID进行这个策略,然后「负载均衡器」就能保证同一个IP来源或者同一个用户永远会被送到同一个后端服务器上了,一般用于处理缓存、会话等功能的时候特别好用。
Pull
Pull coding or client pull:由客户端发起连接,服务器响应,从服务器上拉资源下来~
push technology: 服务器将资源送至客户端
比较容易误区的一个是:RSS这样的,服务器不会未经请求就向客户端发送信息,还是基于pull
Statistical Multiplexing
统计时分多路复用”,又称“异步时分多路复用
时分就是分配time slot给每个终端,你用不用都给你分配了,这种明显不好,浪费,这里说的用不用指的是业务流量。比如传统电话,你拨通了,说不说话,电路就一直给你用。统计时分复用就是当有需求的时候,才分配time slot,这里的需求指的是你有业务流量,回到电话,在统计时分里面,只有你有语音输入的时候,系统才分配time slot给你,没有数据的时候不分配,这个跟之前的时分复用最大的区别就在于分配time slot的时机,时分是固定给你,专用车位,管你来没来。统计时分是你要车位,ok,但是只有你车子进来,真正给你分配一个。SDH就是最典型的统计时分
作者:Kavi Zhang
链接:https://www.zhihu.com/question/287271013/answer/456378287
华盛顿大学计算机网络教程
为什么我们要复用
Since not everyone will be using the network at once in many cases we can imagine, then we can benefit by sharing its resources. This is called statistical multiplexing. Multiplexing == sharing. Statistical multiplexing == sharing using the statistics of demand. It allows us to build a network for the high-end of the expected case rather than the worst case (much cheaper) at the cost of occasionally being oversubscribed.
Example: A user wants 1Mbps of bandwidth 10% of the time to surf the web. (See slides). Draw PDF for one user, two independent users, etc. For N users this is simply a binomial expansion. [You could easily use MatLab to plot this.] The Central Limit Theorem (CLT) says that as N grows large, the demand will rapidly (exponentially fast) die off over the expected value. This holds for all distributions with finite variance. In this case we see that we can support 35 users with 10Mbps of bandwidth with a very small chance of being oversubscribed – a network that is 3.5X smaller and cheaper.
Statistical multiplexing is a key concept in data networks because traffic is bursty (meaning that the peak usage is >> the average usage). How often is your access link at home idle or very low usage? Probably much more than 90% of the time.
统计复用什么时候不work
A1: If each user wants to transmit all of the time – radio/TV stations are allocated a dedicated frequency band, they are not statistically multiplexed.
A2: If demand is dependent. This might be a flash crowd, diurnal (daily) activity, or it might be packet transmissions that are related nearby in time over some scale. Later in the quarter we will see an example of bursts where packet activity is related (self-similarity, or “heavy-tailed bursts” of activity) over some timescales. This was a shocking discovery in the 1990s: because heavy-tailed phenomena have infinite variance the tandard CLT does not apply and aggregating packet traffic makes it more bursty rather than more smooth. Thus traffic does not become smooth until larger timescales (over which there is no self-similarity) than had been expected (if there were no self-similarity). [I’m fairly sure all this is right, but I’m not an expert.]
Q: Is statistical multiplexing the same as packet switching?
A: No. Statistical multiplexing is used in the telephone system too, which
is based on circuit switching (where bandwidth resources are reserved for
a complete telephone circuit for the duration of a call). In that case, it
is the number of calls that is aggregated using statistics as we go deeper
into the core of the network and away from the edges. Nonetheless,
statistical multiplexing has come to be associated with packet switching
because packet switching makes use of it at a fine granularity.
统计复用电路交换在用,分组交换也在细粒度地用。
There are other advantages to packet switching however, the foremost probably being
rate adaptation: assuming a reasonable allocation of resources between
competing inputs when the output is oversubscribed, packet switching will
gracefully allow communication between access links of any capacity, and
can accommodate more users by giving each a smaller share, ie., we all get
to download from that Web server, regardless of the size of our access
line, and the fewer users the more bandwidth we can get. Circuit switching
comes in fixed sizes of necessity.
这一段再说什么我怎么看不懂?
Statistical Multiplexing Gain 多路复用增益
统计复用是一种类型的通信链路共享非常相似的动态带宽分配(DBA)。在统计多路复用中,通信信道被划分成任意数量的可变比特率数字信道或数据流。链路共享适用于在每个通道上传输的数据流的瞬时流量需求。这是创建链接的固定共享的替代方法,例如在常规时分多路复用(TDM)和频分多路复用(FDM)中。如果正确执行,则统计复用可以改善链路利用率,称为统计复用增益。
Oversubscription 和 undersubscription
Over Subscription: If the no. of shares applied for is more than the no. of shares offered to the public then that is called as over Subscription.
Under Subscription: If the no. of shares applied for is less then the no. of shares offered to the public then it is called as Under Subscription.
技术发展要求新的数据中心有更小的超占比,甚至没有超占比;更高的东西向流量带宽;支持SDN。
所以这个超占比到底是什么概念呢
数据中心网络会尽可能地降低带宽收敛比(oversubscription,指一层交换机连接下
层交换机或服务器的总带宽与连接上层交换机的总带宽之比).
影响理解的生词
vetting:审查 the act of making a prior examination and critical appraisal of (a person, document, scheme, etc)
rack: be racked by sth.被什么折磨 ,架子,三角框,a rack of pork猪颈肉,齿轮
** capacitated, directed graph** 容量大的有向图
未能理解的部分
specific flow-onlink level
一些额外的知识补充
数据网络中心架构浅谈
在传统的大型数据中心,网络通常是三层结构。Cisco称之为:分级的互连网络模型(hierarchical inter-networking model)。这个模型包含了以下三层:
Access Layer(接入层):有时也称为Edge Layer。接入交换机通常位于机架顶部,所以它们也被称为ToR(Top of Rack)交换机,它们物理连接服务器。
Aggregation Layer(汇聚层):有时候也称为Distribution Layer。汇聚交换机连接Access交换机,同时提供其他的服务,例如防火墙,SSL offload,入侵检测,网络分析等。
Core Layer(核心层):核心交换机为进出数据中心的包提供高速的转发,为多个汇聚层提供连接性,核心交换机为通常为整个网络提供一个弹性的L3路由网络。
一个三层网络架构示意图如下所示:

通常情况下,汇聚交换机是L2和L3网络的分界点,汇聚交换机以下的是L2网络,以上是L3网络。每组汇聚交换机管理一个POD(Point Of Delivery),每个POD内都是独立的VLAN网络。服务器在POD内迁移不必修改IP地址和默认网关,因为一个POD对应一个L2广播域。
汇聚交换机和接入交换机之间通常使用STP(Spanning Tree Protocol)。STP使得对于一个VLAN网络只有一个汇聚层交换机可用,其他的汇聚层交换机在出现故障时才被使用(上图中的虚线)。也就是说汇聚层是一个active-passive的HA模式。这样在汇聚层,做不到水平扩展,因为就算加入多个汇聚层交换机,仍然只有一个在工作。一些私有的协议,例如Cisco的vPC(Virtual Port Channel)可以提升汇聚层交换机的利用率,但是一方面,这是私有协议,另一方面,vPC也不能真正做到完全的水平扩展。下图是一个汇聚层作为L2/L3分界线,且采用vPC的网络架构。
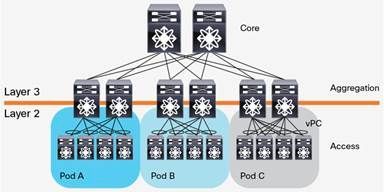
随着云计算的发展,计算资源被池化,为了使得计算资源可以任意分配,需要一个大二层的网络架构。即整个数据中心网络都是一个L2广播域,这样,服务器可以在任意地点创建,迁移,而不需要对IP地址或者默认网关做修改。大二层网络架构,L2/L3分界在核心交换机,核心交换机以下,也就是整个数据中心,是L2网络(当然,可以包含多个VLAN,VLAN之间通过核心交换机做路由进行连通)。大二层的网络架构如下图所示:

大二层网络架构虽然使得虚机网络能够灵活创建,但是带来的问题也是明显的。共享的L2广播域带来的BUM(Broadcast·,Unknown Unicast,Multicast)风暴随着网络规模的增加而明显增加,最终将影响正常的网络流量。
传统三层网络架构已经存在几十年,并且现在有些数据中心中仍然使用这种架构。这种架构提出的最初原因是什么?一方面是因为早期L3路由设备比L2桥接设备贵得多。即使是现在,核心交换机也比汇聚接入层设备贵不少。采用这种架构,使用一组核心交换机可以连接多个汇聚层POD,例如上面的图中,一对核心交换机连接了多个汇聚层POD。另一方面,早期的数据中心,大部分流量是南北向流量。例如,一个服务器上部署了WEB应用,供数据中心之外的客户端使用。使用这种架构可以在核心交换机统一控制数据的流入流出,添加负载均衡器,为数据流量做负载均衡等。
NetFlow中的流
网络协议之Netflow与sFlow协议
1.4、Flow的概念要点
1、定义为一组单向传递的数据包,因此一条会话连接将会有两个方向的数据流,一个是服务器-----〉客户端,另一个是客户端----〉服务器。
2、配置网络设备的时候如果发现仅仅能够接收到某一个方向的数据,那么就要考虑配置是否按照要求设置,流是单方向的,in和out两个方向的数据应该可以同时接收到。
3、NetFlow用七个关键字段定义每一个Flow,一般来说这七个字段可以定义唯一一个流,即:SIP+DIP+SPORT+DPORT +Layer 3 protocol type +TOS byte() + Router or switch interface。
其中协议种类应该是TCP与UDP等协议,在TCP/IP协议中位于第三层传输层。
4、Flow的转发及存储:路由器在接收到一个数据包后,将会查看这七个字段然后作出一个转发决定,如果这个包属于一个存在的数据流,那么相应的流量统计就会被创建,否则一个新的流条目将被创建。
sFlow协议
sFlow技术原理
1.1、sFlow组成要点
1、由sFlow Agent与sFlow Collector组成,简单来说,sFlow Agent布置在交换机与路由器上收集流量信息,组装成报文发送给sFlow Collector做分析。
2、sFlow Agent通过sFlow采样获取本设备上的接口统计信息和数据信息, 将这两种信息封装成sFlow报文,注意这两种信息还是封装在不同的报文中。
3、当sFlow报文缓冲区满或是缓存时间超时后,sFlow Agent会将sFlow报文发送到指定的sFlow Collector。
4、网络设备在整个协议中充当sFlow Agent的角色,sFlow Collector则可能是服务器,IP机等。
1.2、sFlow报文理解
1、采用UDP封装,说明报文也有丢失的可能,缺省目的端口号为知名端口6343,这个端口应该是sFlow Collector的默认端口。
2、四种报文头格式,应该是对应两种采样方式生产的报文,每个报文头还有对应扩展。而且扩展的报文头并不向前兼容。
1.3、sFlow采样要点
1.3.1 、Flow采样
1、sFlow Agent在指定端口上按照特定的采样方向和采样比对报文进行采样分析,这里指定端口是针对报文的采样很关键,这种采样可以获取报文中的信息,是直接截取报文的一段,而不是采用镜像的方式。
2、基本采样方式有固定采样与随机采样两种,运用更多的是随机采样,两者在采样率上有差别,固定采样采样率只能是1/N这种值,而随机采样采样率n/(N+1),设置可以多样,我觉得后者更加灵活。
3、Flow采样的报文中字段很多,有截取的原数据报文,还有针对各种协议解析的报文,还有针对报文转发的字段等等,这些都表明Flow报文中含有丰富的信息。
1.3.2 、Counter采样
1、Counter采样是sFlow Agent周期性的获取接口上的流量统计信息,其实就是定期从接口中提取这段时间内通过的流量大小,再生成报文发给采集器。
2、很明显,这种采样只能得到通过端口的流量大小,却得不到通过流量的具体信息。
3、Counter采样后生成的报文明显比Flow报文简单很多,大部分是关于流量大小的统计信息、CPU占用率和内存使用情况。
1.3.3、Flow采样与Counter采样的区别与联系
1、显然两种采样有很大的区别,Flow采样截取报文,可以获得流量的细节,有了这些就能来分析一些特定的网络行为;但是Counter采样就不关注这些,只关注这些接口上通过流量的量,不关注流量细节。也就是说,两个维度,一个是针对相关数据,一个是关于统计信息。
2、两种采样是相互独立的采样,互不影响,可以同时进行配置。
2、 总结一些sFlow的特色
1、“永远在线”,sFlow技术已经嵌入到的路由器跟交换机的ASIC芯片中,这说明只要设备开机,正常工作,这项技术就能运行,达到“永远在线“的效果。
2、嵌入到芯片中监控所有接口,同时也意味着不需要其他的与流量检测相关的技术,如镜像接口,不仅降低了实施费用,也减少了CPU的计算,省时。
3、Flow采样报文,截取长度可以可以自己设置,这说明可以从数据包中获取更多的信息,有时更多的信息有时可以帮助我们分析网络行为。
4、sFlow可以实时监测每个接口,甚至可以为不同的接口设置不同的采样率,说明在监测流量方面,它比较灵活。
5、运用抽样的方式来监测流量,不用监测每个数据包,说明更适合运用在承载更大流量的网络中。
6、采用Flow采样与Counter采样两种采样方式,我们可以根据自己对流量分析的需求,配置其中一种采样或者同时配置。
LAG
A link aggregation group (LAG) combines a number of physical ports together to make a single high-bandwidth data path, so as to implement the traffic load sharing among the member ports in the group and to enhance the connection reliability.

链路聚合(Link Aggregation)由IEEE802.3ad定义,包括链路聚合目标及实现、聚合子层的功能及操作、链路聚合控制及LACP等。链路聚合将多条物理以太链路聚合形成为一个逻辑链路聚合组,这种聚合对于上层协议和应用是透明的,上层协议和应用将同一聚合组内的多条物理链路视为单一链路,无需改变即可在其上运行。
- 增加带宽:聚合链路的带宽最大为聚合组中所有成员链路的带宽和,目前H3C的交换机产品支持最多64条物理链路聚合,极大的拓展了链路带宽;
- 增加可靠性:聚合组存在多条成员链路的情况下,单条成员链路故障不会引起聚合链路传输失败,故障链路承载的业务流量可自动切换到其他成员链路进行传输;
- 可负载分担:业务流量按照一定的规则被分配到多条成员链路进行传输,提高了链路使用率;
- 可动态配置:缺少人工配置的情况下,链路聚合组能够根据对端和本端的信息灵活调整聚合成员端口的选中/非选中状态。
NIC
网络接口控制器(英语:network interface controller,NIC),又称网络接口控制器,网络适配器(network adapter),网卡(network interface card)
oblivious routing
a robust routing for a class of traffic demand is computed, and thus has the potential to handle traffic spikes well. A potential drawback of oblivious routing is that optimizing for the worst-case performance may incur a high cost when traffic is predictable and stable, which may account for a majority of time.
在遗忘路由中,针对一类流量需求计算出一种健壮的路由,因此具有很好地处理流量峰值的潜力。 遗忘路由的潜在缺点是,当流量可预测且稳定时,针对最坏情况的性能进行优化可能会导致高昂的成本,这可能会占用大量时间。
clos topology
从英文翻译而来-在电信领域,Clos网络是一种多级电路交换网络,代表了实用的多级交换系统的理论理想化。
我觉得我老师在宽带技术课上提到过
HyperX topology
HyperX is a promising high-radix topology proposed by a group of researchers in HP laboratories. The topology offers numerous advantages of high-radix routers, among which are very low diameter and low average distance.
MAP reduce
MapReduce是一种分布 MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。这两个函数的形参是key、value对,表示函数的输入信息。
Energy-aware routing
Energy-aware routing, where routing minimizes the amount of energy used by the network, can significantly reduce the cost of powering a network by making
the network power-proportional [8]; that is, its power use
is directly proportional to utilization.Proposed approaches
including shutting o↵ switch and router components when
they are idle, or adapting link rates to be as minimal as possible [3,7,27,28,40]. For some networks, these techniques can
give significant energy savings: up to 22% for one enterprise
workload [7] and close to 50% on another [40].
However, these techniques do not save much energy on
high-performance networks.
STP spanning tree protocol
生成树协议(英语:Spanning Tree Protocol,STP),是一种工作在OSI网络模型中的第二层(数据链路层)的通信协议,基本应用是防止交换机冗余链路产生的环路.用于确保以太网中无环路的逻辑拓扑结构.从而避免了广播风暴,大量占用交换机的资源。
Valiant Load-Balancing
Valiant Load-Balancing学习
一想到它是1982年提出的,我就觉得难过orz
假设一个内部网络有N个结点,每个结点的容量为r:这意味着出入流量的上限都是r,结点之间的边容量为2r/N,结点之间构成全连通拓扑,我们用flow代表一条流量,如下图所示。
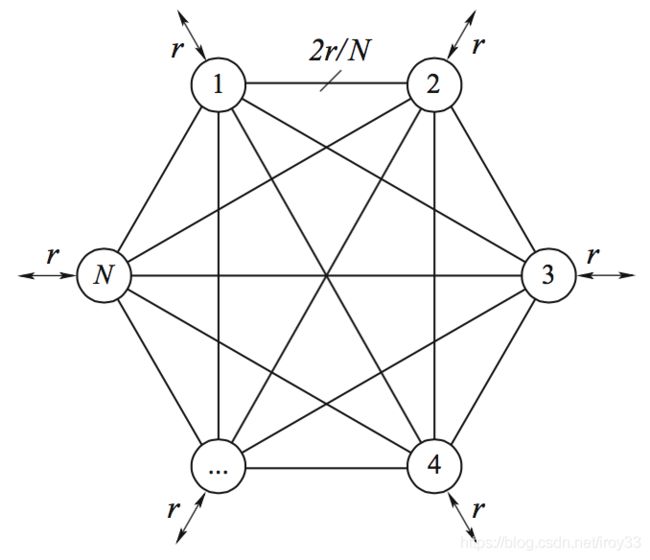
http://vinllen.com/content/images/2015/VLB/VLB_simple.png
这N个结点构成一个内部网络,每当一条flow进入该网络的第一个结点后,都会被等价分流到N个结点上去,然后再从不同结点发往终点(假设终点也在网络内部)。那么,经历的总跳数为2跳,第一跳为分流到不同结点,第二跳到达终点结点。这意味着N个结点平均分担流量压力,如果第一跳结点就是终点或起点,那么该结点经历一跳。尽管点容量为r,但边容量只要2r/N就能满足要求。
VLB网络的优点在于负载均衡,缺点在于本来一跳就可以的路径变成了两跳,增加了时延。